c에서 multiple token을 처리하기 위해서 strtok을 이용할 수 있습니다. 자바는 split 로 매우 간단하게 처리할 수 있습니다. 그리고 이 메서드는 정규 표현식을 이용합니다. c++에서는 어떻게 하면 좋을까요? 자바의 split가 정규 표현식을 쓴다는 것에 착안하시면 무엇을 써야 할 지 쉽게 알 수 있습니다.
문자열 s를 ,과 .를 구분자로 나누는 예제를 생각해 보겠습니다. 먼저, delimeter는 . 아니면 ,입니다. 따라서, 이를 정규 표현식으로 표현하면 [.,]입니다. 이것은 scan 집합이 . 아니면 ,라는 의미입니다.
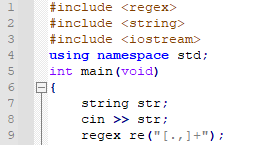
그런데, 이들이 한 번 이상 나오면 어떨까요? 예를 들어, 문자열 ",,"이나, "..,"는 어떤가요? 이런 경우도 match가 되게 하려면 regex의 패턴이 "[.,]+"가 되어야 합니다. 9번째 줄은 이를 반영한 코드입니다.

이제, 10번째 줄과 11번째 줄을 봅시다. 먼저 11번째 줄은 regex_token_iterator를 생성하였는데요. 아무런 인자 없이 default로 생성했음을 알 수 있어요. 이는 이 문서에서 (1)번에 속하는데요. 이것은 end of sequence를 생성한다고 되어 있어요. 문제는 10번째 줄입니다.
해석해 보면, single pattern이 들어가는 걸로 봐서는 (3)번에 속함을 알 수 있는데요. 4번째 인자가 -1이 들어왔어요. 이 의미부터 보도록 하겠습니다. -1이 들어간 자리는 seperator를 뜻합니다. 문서를 내려 보시면 -1일 때 설명이 있는데요.

해석해야 하는 부분은 별 게 없습니다. sequence인데 that 뒤에 is not matched가 붙어 있어요. 문서에서는 regex가 주로 나온 걸로 보아서는 regex 패턴과 매치되지 않는 것을 선택한다. 이 정도로 해석하시면 됩니다. match를 seperator, 즉 구분자로 쓴다는 이야기입니다. seperator라는 단어가 핵심 키워드입니다.

match의 대상은 regex object입니다. 이는 3번째 인자인 rgx를 보면 알 수 있습니다.
12번째 줄에 iter++한 것의 의미를 봅시다. 문서를 참고하면, next submatch를 리턴해 준다는 것을 알 수 있습니다. 그런데 특정 인자, submatch 값이 -1이였으므로, [:,]+ 패턴에 걸리지 않는 것이 선택됩니다.

문자열이 이렇게 있다고 생각해 봅시다. ,이나 .에 걸리지 않는 match는 어떤 게 있나요? 먼저 a가 있어요.
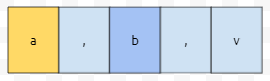
그 다음에는 b가 있어요.

그 다음 match에는 v가 있네요. 그 다음은 없습니다. 따라서, "a", "b", "v"가 순서대로 뽑히게 됩니다. 그런데, regex 패턴으로 넣은 것은 "[,.]"가 아니라 "[,.]+"였습니다. 그랬다는 의미는, ,나 .가 하나 이상 나와도 match가 된다는 것입니다. submatch에 -1을 넣었으니, 이러한 패턴이 아닌 것을 match 하게 될 겁니다.

문자열이 이렇게 들어왔다고 가정해 봅시다. ",."은 ,나 .가 1번 이상 나온 패턴입니다. 따라서 "a" 다음에 읽히는 것은 "b"일 겁니다.
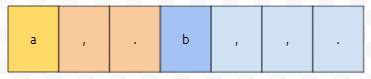
현재 "b"를 읽은 상황입니다. 다음에는 뭐가 읽힐까요?
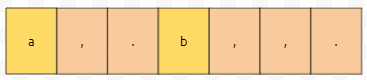
아무것도 읽히지 않습니다. "[,.]+"가 아닌 패턴을 ",,."에서 찾을 수 없기 때문입니다.

실행 결과는 위와 같이 나옵니다.
시간 복잡도는 어떻게 될까요?
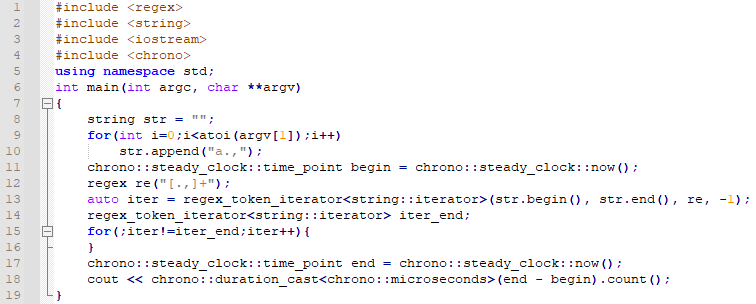
로직의 시작 부분과 끝 부분에 시간을 측정하는 것을 넣어두었습니다.
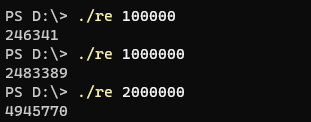
argv[1]은 데이터 size를 의미합니다. 데이터 size가 커질수록 실행 시간은 선형으로 늘어남을 알 수 있어요. 200만개일 때, 4945770 ms가 걸리네요. 상수가 매우 크다는 것을 암시합니다. 그러면, delimeter size에 비례해서 시간이 걸릴까요?

regex만 바꿔서 테스트 해 보겠습니다. 이것은 단순히, 대문자를 구분자로 해서 tokenizing 하는 것입니다.

100만개와 200만개에 대해서 테스트를 돌려보니, 구분자를 2개로 했을 때와 별반 차이가 없음을 알 수 있습니다. 상수가 매우 클 지는 모르겠지만, 최소한 구분자 갯수에 비례해서 수행 시간이 증가하지 않음을 알 수 있어요. 제가 이전에 Java의 split와 Tokenizer에 대해서 이 글에서 간단하게 분석해 드렸는데요. 그것과 비슷하다고 보시면 되겠습니다.
'레퍼런스 > 예제' 카테고리의 다른 글
| java arrays binarysearch 함수를 알아봅시다. (4) | 2021.07.07 |
|---|---|
| c++ tuple 사용법을 예제와 문제를 통해서 알아봅시다. (2) | 2021.06.28 |
| c++ find 메서드로 multiple delimiter일 때 string을 분리해 봅시다. (0) | 2021.05.31 |
| 파이썬 randint randrange : 랜덤하게 수를 뽑을 때 쓴다. (0) | 2021.05.17 |
| c++ stoi 함수 : string to int를 할 때 많이 이용한다. (0) | 2021.05.05 |


최근댓글