리눅스에서 파일 줄 수를 셀 때 wc 명령어를 이용하면 됩니다.

예를 들어 파일 1의 줄 수를 세기 위해서는 cat 1 | wc -l을 입력하시면 됩니다. 이는 1의 내용을 출력한 결과를 piping 해서 wc -l에 넘기는데요. "abc\ndef"가 저장이 되어 있었다면, "abc\ndef"가 wc -l의 입력으로 넘어가게 됩니다. 당연하게도, 2개의 줄이 있으니, 2가 출력됩니다.
윈도우 cmd에서는 조금 복잡한데요. 간단하게 알아봅시다.
제 문서. 즉 C:\Users\chokw에 있는 1.txt에 있는 특수 문자들을 보도록 하겠습니다.

notepad++을 쓰고 있다면, 보기에서 기호 보기에서 특수 문자 표시에 체크해 줍니다.
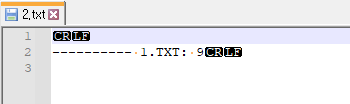
그러면, CR LF가 뜨게 되는데요. 캐리지 리턴인 \r와 개행 문자인 \n가 있습니다. 리눅스의 경우는 조금 다른데요.
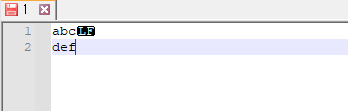
linux 서버에 올려져 있는 파일 1을 다운로드 받아서 notepad++로 보면, 끝에 CR이 없고 LF만 있어요. 개행 처리할 때 다르다는 점을 조심할 필요가 있어요. 파일에서 텍스트 문자열을 찾기 위해서 쓸 수 있는 것은 find 명령어입니다.

설명을 보면, /V는 지정한 문자열이 없는 줄을 표시하고, /C는 그 수를 표시한다고 되어 있습니다. 즉 /V /C "a"는 a 문자열이 없는 줄 수를 출력한다는 의미입니다.

1.txt는 위와 같습니다.
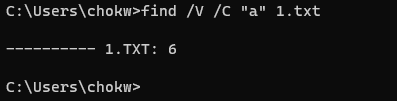
문자열 "a"가 없는 줄은 2개입니다. Hello my name is chogahui와 abcde는 줄에 "a"가 있습니다. 따라서, 8에서 2를 뺀 6이 됩니다. 캐리지가 있고, 개행이 있다면, 해당 줄의 길이는 0이 아닙니다. 따라서, "", 즉 빈 문자열을 찾을 수 없는 줄의 갯수를 찾으면, 파일 라인 수가 됩니다.

1.txt의 라인 수는 8이 됩니다.
그런데 결과에 ---------- 1.TXT: 8이 나오는데요. 8만 취할 수 있는 방법은 없을까요?

파일을 인자로 받지 않고 써 봅시다. 그러면 cmd 창에 뭔가 입력해야 하는데요. abc, def, C를 입력하고 ctrl+C를 누르면 3이 나옵니다. 3만 나왔다는 것이 핵심 포인트입니다. 표준 입출력으로 받는 대신에 1.txt에서 입력을 받도록 하면 됩니다. 아래 명령어를 봅시다.

find /v /c "" < 1.txt인데요. <는 <-로 연상하면 쉽습니다. 반대로 >는 ->로 연상하시면 되고요. 데이터가 흐르는 방향으로 보시면 되는데요. 1.txt에서 좌항으로 가는 것이므로, 1.txt에서 입력받아서 find /v /c ""를 처리한다로 해석하시면 됩니다. 결과는 8이 나옵니다.
'OS > 윈도우' 카테고리의 다른 글
| window 특정 포트를 쓰는 사용 중인 프로세스를 종료해 봅시다. (0) | 2022.11.20 |
|---|---|
| window type 명령어를 이용해서 redirection 처리를 해 봅시다. (0) | 2022.01.18 |


최근댓글