요새 졸리네요. 코딩 테스트를 개최하면서 여러 코드를 보았는데요. 2회 코테가 의외로 1번부터 막히는 경우가 많았는데요. 아마도 정렬과 비교 함수의 메커니즘에 대해서 익숙하지 않아서 그러셨을 겁니다. strict weak ordering은 이펙티브 자바에서도 언급하는 주제이니 다른 조심해야 할 점을 언급해 볼게요.
이 질문과 이 질문은 제가 오늘 쓰려는 글과 관련이 깊습니다. 결론부터 말하자면, 정렬 문제에서 전처리 할 부분을 미리 전처리 하고 오면 로직이 단순해 집니다. 그러면 실수할 여지도 적습니다. 그리고 크기가 n인 배열을 정렬할 때 키 2개를 비교하는 compare 함수는 O(nlogn)번 호출됩니다.
이 글에서는 compare 함수가 어떻게 동작하나요? 에 대해서는 다루지 않습니다. 어떻게 정의해야 하나요? 이건 이펙티브 자바에서 더 잘 설명하고 있으니, 저는 compare 함수가 몇 번이나 호출되고, 그래서 왜 이렇게 작성하면 안 되는지에 대해 다뤄보겠습니다. 예제 프로그램을 봅시다.

struct moo가 선언되어 있어요. 딱히 의미는 없고요. int field 하나를 가지고 있습니다. 그리고 전역 변수로 cmp_count가 있는데요. 이것은 재정의된 cmp 함수를 몇 번이나 호출하는지 세기 위함입니다.

cmp 함수를 봅시다. 내부에서 cmp_count를 증가시키는 로직이 있네요. 그리고 정의된 것으로 보아서는 x 오름차순으로 정렬하려고 했나 봐요.
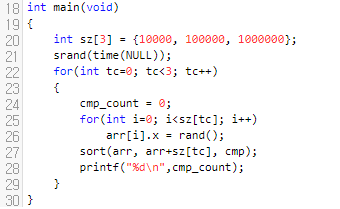
22번째 for loop를 봅시다. 이 부분은 딱히 설명드릴 게 없어요. 단지, input의 크기를 1만, 10만, 100만으로 늘려가면서 cmp 함수를 몇 번이나 호출하는지 출력한다는 것 정도는 아실 수 있습니다. rand와 srand 함수 덕분에 매 실행마다 cmp_count 값은 달라질 겁니다.

실행 결과를 보면, 크기가 1만일 때에는 15만, 10만일 때는 201만, 100만일때는 2396만번 호출되었음을 볼 수 있어요. 대략 cmp 함수는 정렬해야 할 원소의 갯수를 n이라 하면 nlog(n)회 정도 호출된다고 보면 되겠네요.
그 전에, 가희와 파일탐색기 문제는 정렬해야 할 데이터 갯수가 최대 20만개까지 주어집니다. 그렇다는 이야기는 cmp 함수가 350만 ~ 450만회 정도 호출이 된다는 이야기가 되겠습니다. 어림잡아 500만이라 해 볼게요. 시간 제한이 1.5초이지만, 생각보다 빡빡한 이유는 compare 함수 안에 들어가는 로직이 꽤 복잡하기 때문입니다. 해당 질문의 로직을 봅시다.
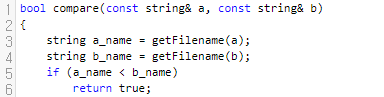
a.txt, b.txt 등으로부터 확장자와 파일 이름을 얻어옵니다. 이것은 그렇게 시간을 오래 끌 정도는 아닙니다.

해당 함수의 시간 복잡도를 분석해 보면, 어려울 건 딱히 없어요. 최악의 경우에 O(|s|)일 겁니다. 그리고 문제 조건상 파일 이름.확장자 꼴로 주어지고 파일 이름이나 확장자나 10자 이하이니, 이 메서드는 많아봐야 10개의 문자만 보고 끝날 겁니다.

이 부분은 어떨까요? 여기도 그렇게 큰 문제로 보이진 않습니다. getExtension 역시 많아봐야 20자 정도 보고 끝낼 것이기 때문입니다. 정말 그런지 봅시다.

뭔가 복잡해 보이지만, 사실 .이 나타나는 위치를 찾고 그 다음부터 쭉 뽑아내게 됩니다. s.size()까지는 돌 거고, 확장자랑 파일 이름은 길어봐야 10자이니 21자 정도 보고 끝내겠어요. cmp 함수가 400만번 정도 호출되고, 문자 비교를 대충 3x회 하면 넉넉하게 시간 내에 돌아가야 하는 것이 정상입니다. 심지어, 비교 연산은 그렇게 느린 편도 아닙니다.
그런데 왜 시간 초과가 났을까요?

11번째 줄을 보면 extensions 부분이 있어요. 이것이 unordered_map으로 선언되어 있는데요. ext의 길이가 10인 확장자들이 한 버킷에 하나씩만 있다고 해 봅시다.
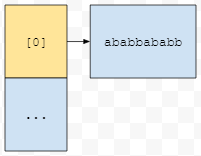
예를 들어 ababbababb가 0번 버킷에 있다고 해 봅시다. ababbababd 확장자가 있는지 판단하는 쿼리가 들어오는데요. 이것의 해시값을 토대로 어느 버킷에서 탐색해야 할 지 계산해 보니 0번 버킷이더라. 라는 결과가 나왔다고 해 봅시다.

그러면 이 버킷에 있는 하나의 문자열 ababbababb와 입력으로 들어온 ababbababd가 다르다는 것을 판단하기 위해서 10개의 문자를 비교해야 해요. 그런데, 이것을 1번만 할까요? 한 번 더 합니다. a의 확장자와 b의 확장자에 대해서. 어? 뭔가 무거워 질 수도 있을 거 같습니다. 그런데 13번째 줄의 else 문을 보면 a_ext와 b_ext를 비교하는 게 또 있어요.
그러면 비교 함수를 호출할 때 마다 이런 일을 하게 되네요.

이 작업을 450만번 하게 된다는 의미입니다. 그런데, name하고 ext를 얻어오는 과정에서 string을 통으로 호출합니다. 게다가, ext를 얻어올 때에도 abcdefg.abcdefg 이런 식으로 파일명.확장자가 들어 있는 string을 통으로 보내버립니다. 그러면 위 과정에서 이런 과정도 추가되었을 겁니다.

즉, 노란색으로 표시한 연산도 가볍지 않았다는 의미가 됩니다. 최소한 이 부분은 name하고 ext하고 나누어서 받았다면 name, ext를 얻어올 때 20짜리 문자열을 통으로 넘겨서 비교하는 게 아니라, 10짜리 문자열을 넘겨서 비교했을 겁니다. 그러면 보다 효율적으로 처리가 가능했을 겁니다.
거기에다가 check OS support ext 또한 이미 주어진 정보라면, 정렬하기 전에 미리 해당 확장자가 있는지 없는지를 판단하기만 하면 됩니다. 정렬을 하기 전에 해당 정보를 넣는다면, compare 함수에서 두 번 세 번 일 할 이유가 없습니다. 해당 질문 글은 파일 이름과 확장자를 필요 없는 연산을 해 가면서까지 뽑은 게 더 커 보이지만, unordered_map도 무시는 못 할 요인이라 보여집니다.
그러면, compare 함수 내에서 bsearch나 set을 써서 확장자가 있는지 없는지 탐색한 경우는 어떨까요? 실패한 코드들을 읽어 보니 의외로 이 부분에서 미스가 난 경우가 많았습니다. 데이터 크기가 20만일 때 compare 함수의 호출 횟수가 대략 400만이다라는 것을 기억하시면 됩니다. 그 다음에 이 질문을 해 봅시다. 데이터의 크기가 20만일 때, bsearch나 균형 트리는 몇 번이나 탐색할까요? 대충 로그(20만)이니까 10 ~ 20회 정도 탐색한다고 해 볼까요?
26^4가 46만 정도 되니까, 앞에 접두사 6개는 모두 같은 확장자가 나오는 데이터가 없을까요? 최악의 경우에는 있을 수도 있습니다.

그러면 접두사가 aaaaaa인 길이가 10인 확장자가 들어왔고, OS가 인식하는 확장자 또한 접두어가 aaaaaa라면, 최소한 7개의 문자를 비교해야 상대적인 비교가 가능할 겁니다. 이러한 작업을 10 ~ 20회를 한다? 확장자가 없는 경우라면, 최소한 compare가 한 번 호출이 될 때 마다 70 ~ 140개의 문자를 비교해야 한다는 소리가 됩니다.
그런데 400만번이 호출되었대요. 400만에 70을 단순하게 곱하기만 해도 2.8억입니다. n이 20만일 때 O(n(logn)^2)가 아슬아슬 한가요? 여기에 확장자나 파일 이름의 길이만큼의 상수가 더 붙는다면 어떤가요? 1.5초이면 넉넉할까요? 확실한 것은, 크기가 n인 배열을 정렬할 때 compare 함수는 O(nlogn)번 호출이 되니까, 그것을 감안해서 custom한 비교 함수를 작성하면 좋겠다. 정도가 되겠습니다.
'자료알고 > 알고리즘' 카테고리의 다른 글
| 가희와 비행기 문제를 카탈란 수로 구해 봅시다. (0) | 2022.01.06 |
|---|---|
| 롯데 자이언츠와 가희 : 벤다이어그램을 그려서 도식화 시켜 봅시다. (0) | 2021.11.24 |
| 리버스 가희와 프로세스 : 상황 도식화를 잘 시켜 봅시다. (0) | 2021.11.01 |
| in place 알고리즘에 대해서 간단하게 알아봅시다. (0) | 2021.09.27 |
| Longest Substring Without Repeating Characters 문제를 풀면서 슬라이딩 윈도우를 정복해 봅시다. (2) | 2021.08.27 |


최근댓글