postgresql에는 partial index가 있습니다. 문서에 있는 것을 간단하게 요약하면, 조건을 만족하는 것만 indexing 하기 위해 쓰입니다. To avoid indexing common values가 중요한 부분입니다. django에서 email 필드에 대해, 널 값인 경우 unique 제약조건을 먹히지 않게 하는 방법을 찾다가 아래의 방법을 찾게 되었는데요.
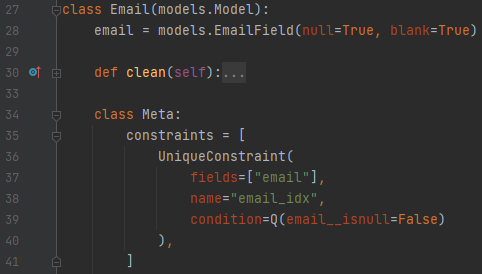
35 ~ 39번째 의미는, 제약 조건을 추가할 텐데 UniqueConstraint를 추가할 거라는 의미입니다. field는 email, name은 email_idx, 중요한 것은 Q 조건입니다. email__isnull이 False인 것에 대해서만 적용하겠다는 의미입니다. 장고에서 이것을 어떻게 쓰는지에 대해, 이 글에서는 언급을 하지 않겠습니다.
다만, 이런 식으로 짰을 때, 어떻게 postgres에 반영되는지 보도록 하겠습니다.

email 관련 model을 migrate 하고, dbeaver에서 DDL을 조회해 봅시다. 그러면 이런 DDL도 있음을 볼 수 있는데요. 1번째 줄부터 천천히 해석해 봅시다. email_idx라는 unique index를 생성한답니다. 그런데, public.myapp_email에 대해서. btree를 쓴다네요. 그런데, 4번째가 중요합니다. where 절을 보면 email이 not null인 경우만 적용된다는 의미에요.

이는, Predicate를 보아도 알 수 있습니다. unique는 체크 표시가 되어 있는데요. email이 NULL값이 아닌 경우에 대해서만 적용된다는 의미입니다. 이제, email 데이터들을 추가해 보겠습니다.

이 쿼리는 잘 작동합니다. 왜냐하면, NULL인 경우, unique 제약 조건이 걸려있는 인덱스에 indexing이 되지 않기 때문입니다. 다음에, 3번째 'cho@a.com'이 들어갑니다. 그러면 인덱스에는 'cho@a.com'만이 들어갑니다.

다음에, 이 쿼리를 수행하면 어떻게 될까요? 4, 5번은 별 문제가 없어 보이지만, 6번에서 문제가 발생합니다. 왜냐하면, 이미 데이터 'cho@a.com'가 있기 때문입니다.

왜? 'cho@a.com'은 널이 아니기 때문에, indexing이 되었기 때문입니다. 그리고, 해당 인덱스는 unique 조건이 걸려 있었습니다.

이 쿼리를 수행하면, 빈 문자열과 NULL이 들어가는데요. 이 때 NULL 값이 아닌 빈 문자열 ''이 indexing 됩니다.

다음에 다시 ''를 넣으려고 하면 어떻게 될까요? 제약 조건을 위반해 버립니다. 왜? 이미 빈 문자열은 index에 있기 때문입니다.

어떻게 해야 할까요? 빈 문자열은 NULL로 바꿔서 넣던지, 인덱싱 조건을 바꾸는 수밖에 없습니다. 저는 후자의 방법을 택하겠습니다. email_idx 인덱스를 drop 하고 다시 생성하겠습니다.

이 쿼리는 무엇을 의미할까요? email이 not NULL이면서, email이 빈 문자열이 아닌 경우에만 indexing을 한다는 것을 의미합니다. 인덱스를 드롭하고 다시 생성했기 때문에, 실제 인덱스에는 'cho@a.com'만 들어가 있을 겁니다.
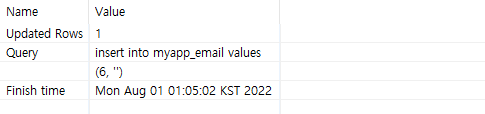
이제, 빈 문자열 데이터를 넣어보니, 성공함을 알 수 있습니다.
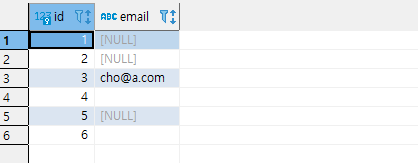
email 테이블에 있는 데이터를 모두 조회해 보았습니다. id가 4번인 것과 6번인 것이 빈 문자열입니다. 빈 문자열은 인덱싱이 되지 않았기 때문에, 중복해서 들어갔음을 알 수 있습니다. 이를 조금 더 응용하면, partial index를 사용해서, trim 함수로 공백 문자만 있는 것들을 모두 인덱싱이 되지 않게 걸러버릴 수도 있을 겁니다.
'코딩 > Sql' 카테고리의 다른 글
| postgres aggregate filter 에 대해 알아봅시다. (0) | 2022.08.28 |
|---|---|
| dbeaver db 백업하고 복구하는 방법을 알아봅시다. (0) | 2022.08.25 |
| postgresql generate_series 함수를 간단히 알아봅시다. (0) | 2022.07.23 |
| postgresql random 함수를 알아봅시다. (0) | 2022.07.22 |
| django mptt와 업뎃이 별로 없는 계층형 구조에 대해 알아봅시다. (0) | 2022.06.23 |


최근댓글