mysql에서는, 정보를 조회할 때 select from where 절은 상당히 많이 씁니다. 오늘은 그 중 첫 번째, from 절에 대해 알아봅시다. 보통 이 뒤에는 릴레이션, 즉 db 안에 있는 테이블 명이 오는데요. 이 뒤에 테이블 이름이 여러개가 들어와 있으면 어떻게 동작할까요?
그 전에, 카티션 곱을 아실 필요가 있습니다. 집합 A가 있고 집합 B가 있다고 해 봅시다. 이 때, A와 B의 카티션 곱 C는 아래와 같이 정의됩니다.
C = {(a,b)|a는 A에 속하고, b는 B에 속한 원소}
즉, n(A) = 3이고, n(B) = 3이라면 n(C) = 9라는 것입니다. from 절에 테이블 2개가, 즉 t1과 t2가 오면 결과 값은 t1과 t2의 카티션 곱으로 나옵니다. 정말 그런지 확인을 해 볼까요?

다음과 같이 테이블을 생성합니다. 테이블 t1과 테이블 t2는, str이라는 필드만 가지고 있는 레코드를 저장할 수 있습니다. 저는 t1에 'a', 'b', 'c', 'd'를, 그리고 t2에도 똑같이 'a', 'b', 'c', 'd'를 넣을 겁니다.

이렇게 넣고, 아래와 같은 쿼리를 실행해 봅시다.

이것은 t1과 t2를 카티션 곱한 결과를 출력하라는 의미입니다.

그러면 수행 결과가 어떻게 나올까요? 16개의 row가 출력됩니다. 보시면 (a,b)쌍이 모두 출력되었음을 알 수 있어요. 쉽게 말해서, 2중 for loop를 돌면서 바깥쪽 for문은 t1을, 안쪽 for문은 t2를 돌면서 출력했다고 보시면 됩니다. 그러면, t1의 크기에다가 t2의 크기를 곱한 것 만큼의 단위 시간이 걸릴 거에요.
from절 뒤에 테이블 명이 3개 오면 어떨까요? 3개의 테이블들의 크기 곱만큼 걸립니다. 예를 들어서 select * from t1,t2,t3; 이렇게 쿼리가 들어왔다고 하면, t1의 크기에 t2의 크기에 t3의 크기를 곱한 값만큼의 단위 연산을 수행합니다.
다른 예제를 봅시다.
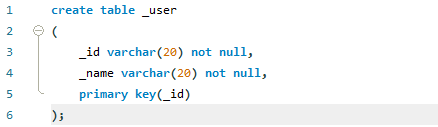
먼저, _user를 정의했습니다. _id와 _name을 정의했는데요. _id는 primary key입니다.

그리고 _order 테이블 또한 정의했는데요. primary key로 주문 번호를, 그리고 외래키로 _id를 지정했습니다. 이는, 고유 번호 xx를 주문한 유저가 어느 ID를 가지고 있는지 참조하기 위해서 위와 같이 설계하였습니다.

그리고 유저에는 다음과 같이 데이터를 넣었습니다.

주문은 이렇게 들어왔습니다. 그러면, select 문으로 order하고, _id에 어떠한 레코드들이 들어가 있는지 눈으로 확인해 보도록 합시다. 먼저 order입니다.

뭔지는 모르겠지만, 2번을 주문한 사람의 _id가 chogahui05입니다. 5번은 gg32이고요. 7번은 iron92가 했군요.
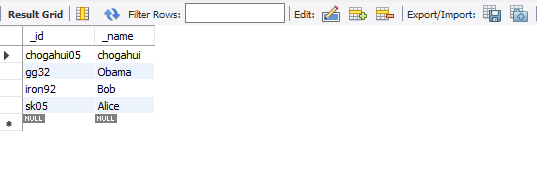
그리고 회원 정보입니다. _name은 이름, _id는 웹 사이트에서의 id를 의미합니다. 그러면 테이블 1의 레코드 수가 7이고, 2으 레코드 수가 4이니까, 그냥 단순히 from 절에 _order, _id를 넣어주면 28개의 결과가 생성이 될 거에요.

이 쿼리를 수행해 봅시다. 그러면 _order와 _user의 카티션 곱을 할 거에요.

그러면 대충 28개 정도가 좌르륵 출력이 됨을 알 수 있어요. 실행 계획을 봅시다.

다른 건 잘 모르겠지만, 어찌 되었던 카티션 곱을 생성해야 하니까, 2중 루프를 돈 건 분명해 보이네요. 그 과정에서 두 개의 테이블 또한 계속 Full Scan을 해 버립니다. where 절이 없었기 때문에 이 부분은 당연한 것일 테고요.
그런데, 이 조건을 줘 봅시다. _order._id와 _user._id가 같은 것만 출력해라. 실제로 이것은 모든 쌍 중에서, 주문을 한 사람의 id와 유저 정보에 있는 id가 같은 것만 출력하는데요. 예를 들어서, _order의 _id가 'chogahui05'였는데, _user의 _id가 'gg32'인 레코드는 출력하지 않는다는 겁니다.

그러면 이렇게 주면 될 건데요. _order._id는 외래키, _user._id는 고유키입니다. 만약에, 바깥쪽 loop가 _user를 탐색하고, 안쪽 loop가 _order를 탐색한다고 해 봅시다. 그리고, _order의 외래키, 그러니까 _id 필드가 인덱스를 쓴다고 가정하면, for loop를 2개를 도는 대신에 이런 식으로 optimize를 할 수도 있을 겁니다.

물론 반대로 _order를 바깥쪽으로 빼고, _user를 안쪽 Loop로 넣는다고 하면, _order를 Full scan 하고, 안쪽에 있는 테이블은 index를 통해 찾을 수도 있긴 하겠네요.
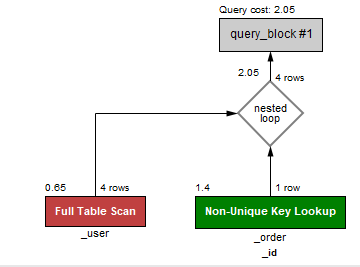
중요한 것은 둘 다 Full Table Scan은 아니라는 겁니다. 물론 인덱스 값이 모두 같다. 그러면 또 모르겠지만, 테이블에 들어간 데이터 구조를 보면 그렇지는 않았습니다.
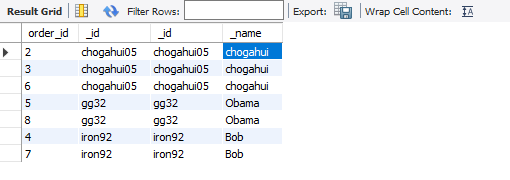
그러면 결과가 위와 같이 나옵니다. 그러면 2번 주문을 한 손님의 _name을 출력하려면 어떻게 하면 좋을까요?
where 절에 order_id = 2를 추가해 주면 됩니다.
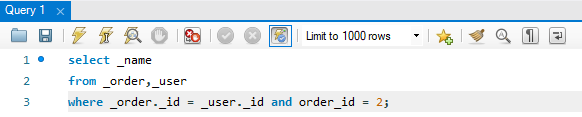
그러면 요런 쿼리가 될 겁니다. 그러면 이 경우는, 사실 요런 식으로 최적화가 가능할 겁니다.

먼저 _order에서 주문 번호가 2인 레코드를 찾습니다. 그리고 나서, 그것의 _id를 얻어올 겁니다. 그 값이 'chogahui05' 였으니, _user.id의 값이 'chogahui05'인 것을 찾아요. 주황색인가요? 초록색과 주황색을 카티션 곱 해 버리면 됩니다. 그러면 28개의 행을 모두 안 보고도 결과값을 출력할 수 있습니다.

이것은 실행 계획을 봐도 알 수 있는데요. 쿼리를 최적화 한 것입니다. 인덱스가 걸려있기 때문에, 28개의 데이터들을 모두 볼 필요가 없었던 겁니다. 두 개의 테이블의 레코드 사이즈가 작아서 그렇지, 만약에 10만개, 20만개였다고 치면, 처음에 카티션 곱을 생성하려면, 200억 번의 단위 연산을 수행해야 합니다. 이는 꽤 끔찍한 일입니다. 그만큼 카티션 곱은 꽤 무겁다는 것 정도만 짚고 넘어가셔도 좋을 듯 싶습니다.
'코딩 > Sql' 카테고리의 다른 글
| mysql concat 함수 : 문자열을 뒤에 계속 붙인다. (7) | 2019.08.26 |
|---|---|
| mysql in 연산자 : 피연산자가 집합의 원소인가? (10) | 2019.08.23 |
| mysql regexp : 복잡한 패턴 매칭을 해 봅시다. (20) | 2019.08.12 |
| mysql 테이블 컬럼 추가 : alter 명령어로 해 보자. (3) | 2019.08.02 |
| mysql Like 연산자 : 간단한 패턴과 매칭되는지 검사한다. (8) | 2019.08.01 |


최근댓글