제가 개최한 코딩테스트 2회의 2번 문제는 가희와 키워드 문제였습니다. 메모장에 있었던 키워드는 해당 키워드에 대한 글을 쓰고 나면 지워지게 되는데요. 문제는 블로그에 글을 쓰고 난 후, 메모장에 남은 키워드는 몇 개인지를 묻는 것입니다. 이 문제의 원래 출제 의도는 string의 길이 제한을 잘 보고 압축을 해서, 문자열 비교하는 복잡도를 떨궈낼 수 있는 가였습니다.
문제 제한을 더 자세히 보겠습니다. 문제에서 등장하는 키워드의 총 개수는 200만개 이하입니다. 200만개에 대해서 메모장에 키워드가 있는지를 검사하면 되므로, treemap을 써도 괜찮아 보이긴 합니다. O(200만log50만)면 괜찮지 않을까요? 여기서 문제. treemap을 쓰면 문자열의 compareTo 함수는 얼마나 호출이 될까요?
jdk17로 테스트 했습니다.

이 코드를 디버그 해 보겠습니다.
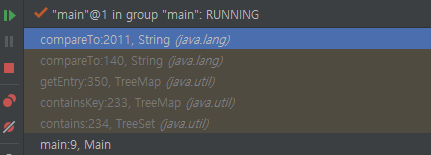
디버그를 걸어보면 treeset의 add나 contains 같은 얘들을 호출할 때 compareTo가 호출됨을 알 수 있어요. 당연할 겁니다. 왜냐하면 키 값의 비교를 통해서 어떤 노드에 어떤 키를 넣을지 정해야 하기 때문입니다. comparable하지 않은 키에 대해서 hashmap이나 hashset이 충돌이 매우 많이 일어났을 때 비효율적으로 동작하는 이유이기도 합니다. 다른 기준으로 정렬해 버리기 때문입니다.
이에 대한 것은 제가 예전에 썼던 글들을 보시다 보면 간파하실 수 있을 겁니다. 자. 그러면, "pineapple"이 contain이 되었는지 판단하는 메서드가 호출되었을 때, compareTo는 몇 번이나 호출될지 trace를 걸어봅시다.

anotherString이 "pineappleh"일 때 "pineapple"과 비교를 하는 모양입니다. binary tree의 특성상 일치하지 않으면 왼쪽이나 오른쪽으로 타고 내려갈 겁니다.

다시, 비교를 하게 되는데, 이번에는 "pineappled"와 비교합니다. 어? 여전히 일치하지 않네요. 그러면 어떻게 해야 하나요? 왼쪽을 타고 내려갈 겁니다.

이제, "pineappleb"와 비교합니다. 여전히 일치하지 않네요. 왼쪽을 타고 내려갑니다.

이제 "pineapplea"와 비교합니다. 어떤가요? 여전히 일치하지 않습니다. 이 과정에서 어떤 연산을 하게 되나요? 문자열 2개를 비교하는 로직을 타게 됩니다. 이 로직은 최악의 경우 원소끼리 비교하는 것을 몇 번이나 수행하나요?

정확히 말하면, 115번째 loop가 몇 번 도느냐입니다. k값이 어디까지 커질 수 있냐인데요.
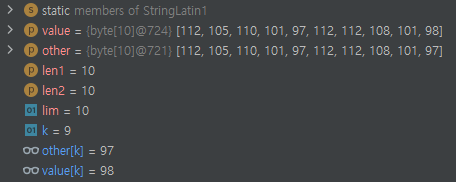
9까지 커질 수 있네요. 이는 복잡도와 매우 깊은 연관이 있습니다. 이 9라는 수치는 비교할 문자열의 길이와 엇비슷합니다. 즉, 자바에서 tree 계열을 이용했을 때 걸리는 복잡도는 O(10nlogm)이 아니라, O(100nlogm)이 되게 됩니다. 메모장에 키워드가 있는 상황을 구축하는 복잡도는 포함하지 않은 겁니다. n과 m이 20만입니다. 전자가 아니라 후자에 대강 넣어서 계산해 보면 대략 3.4억이 나오게 되는데요. treeset과 treemap의 상수가 꽤 크다는 걸 생각해 보면..
이제 O(100nlogm)에서 개선하는 방법을 생각해 봅시다. 문자열 비교 상수를 떼는 방법이 있고, 뒤에 붙은 로그를 떼어 버리는 방법이 있습니다. 쿼리를 보면 키워드가 있는지 없는지가 중요합니다. 있는가 없는가? 이는 equal 연산만 있음을 의미합니다.
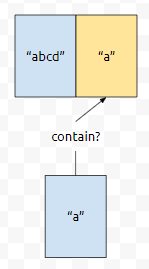
"a"가 있으면 적당한 자료구조에서 이를 제거하기만 하면 됩니다. 이 적당한 자료구조는 그냥 key가 있는지만 보면 됩니다. 그렇기 때문에, hash 계열도 적합한 구조임을 알 수 있습니다. hashcode 값이 모두 동일해서 충돌이 매우 많이 일어나는 경우에는 동일하겠지만, 10n번 찾는 연산의 평균 복잡도를 O(100n) 정도로 줄일 수 있습니다. n의 최댓값이 20만임을 감안했을 때, 매우 효율적으로 동작함을 알 수 있습니다. 제 의도와는 다소 벗어났지만, 올바른 풀이입니다. 실제로 대회에서 가장 많이 제출된 풀이였습니다.
혹은, 문자열을 적당하게 압축할 수도 있습니다. 길이가 10 이하이고 소문자만 들어온다는 것이 핵심 포인트입니다.
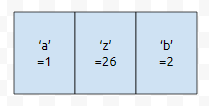
소문자 'a'를 1로, 'z'를 26으로 대응하면 어떤가요? 32진법 수로 표현할 수 있나요? 32는 2^5이고 문자열의 길이가 10까지 나오기 때문에, 커져봤자 2^50이 됩니다. 2^50은 2^63 - 1보다는 작으므로, 8byte 정수형 하나로 압축할 수 있습니다. 문자열을 비교하는 연산을 떼 버릴 수 있습니다. 이 코드는 문자열을 압축하는 방법을, 이 코드는 hashmap을 이용하는 방법을 사용하였습니다.
'구현' 카테고리의 다른 글
| key multiple value 처리를 물어본 가희와 파일탐색기 2 문제를 풀어봅시다. (0) | 2022.07.03 |
|---|---|
| 가희와 자원 놀이 : 자원 카드를 어떻게 관리할지 생각해 봅시다. (0) | 2022.02.14 |
| 가희와 btd5 : 직선의 기울기를 gcd를 이용해서 손쉽게 처리해 봅시다. (0) | 2021.10.20 |
| 하드 코딩을 이용해서 7 세그먼트 구현 응용 문제를 풀어봅시다. (0) | 2021.09.15 |
| 가희배 코테에 나온 수인분당선 문제를 세팅한 이야기 (5) | 2021.09.12 |


최근댓글