안녕하세요. 백준에서 활동하고 있는 chogahui05입니다. 저번 lazy propagation 시간에는 변환을 합성한다는 관점에서 접근했습니다. 이번에는, 그것을 알고 있다는 전제 하에서, 어떻게 코드를 이해하셔야 할 지 설명을 해 보도록 하겠습니다. 이 글에 있는 코드는 설명을 위해 중요 부분만 간략화 한 것임을 참고해 주시면 감사하겠습니다.
먼저, lazy는 누적된 변환이라는 것이 핵심이라고 했습니다. 그러면, 누적된 변환이라는 개념이 왜 나왔는지부터 생각해 봅시다. 그 전에, 연속된 k개의 구간을 어떻게 처리할 것인지부터 고민해 봅시다. 보통의 segment Tree에서 연속된 k개의 구간을 업데이트 하는 연산은 klogn번만큼 수행이 됩니다. 문제는, 이런 쿼리가 50만개 들어왔다고 생각해 봅시다. [s, e]의 구간에 k를 더한다. 그리고, 구간의 크기는 50만이라고 해 봅시다.
이 경우에, 최악의 경우, 50만 x 50만 x log 50만의 복잡도를 가지게 됩니다. 이걸 줄이는 방법이 없을까요?
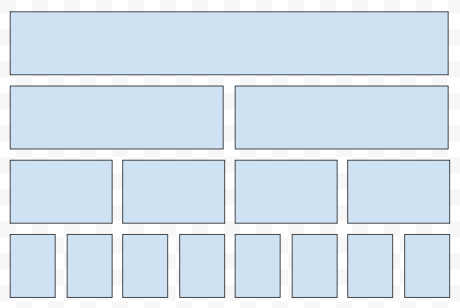
구간의 전체 크기를 n이라고 합시다. 세그먼트 트리에서 구간 [s, e]를 표현하기 위해서는 많아봐야, 2 x log(n)에 비례하는 수만큼의 노드가 필요합니다. 예를 들어서, 위 그림은 구간 1부터 8까지를 나타내는 세그먼트 트리를 간략하게 나타내 본 것인데요. 구간 [3, 7]을 간략하게 표현을 해 봅시다.

그러면, [3, 7]까지의 구간은 단 3개의 대표 노드로 압축이 될 수 있어요. 사실 이것이 전부입니다. 그러면, [s, e]에 k가 더해진다는 쿼리가 들어왔을 때, e - s + 1개의 노드를, 그러니까 점 e - s + 1개를 각각 업데이트를 하는 것이 아니라, 이들을 커버하는 단 몇 개의 대표 노드들을 업데이트 하자는 이야기입니다. 예를 들어, [1, 6]을 업데이트를 한다. 그러면 아래와 같은 노드를 업데이트 하면 됩니다.

그러면, 시간 복잡도 문제는 해결이 됩니다. 그런데, 여기서 문제가 하나 생깁니다. 그 다음에는 어떻게 처리해야 할까요? 예를 들어서, 어떠한 구간의 합을 구하기 위해서, 노드를 log(n)에 비례하는 수만큼 방문하게 될 텐데, 그 노드에 있는 값은 '업데이트 쿼리들이 모두 반영된' 상태인가? 이것이 반영이 되어 있고, 그렇지 않고의 차이는 생각보다 크다는 것을 생각해 봅시다.
일단, 우리는 어떠한 쿼리에 대한 답을 할 때 방문하는 노드에 대해서는 '업데이트 쿼리들이 모두 반영된 상태' 가 되어야 합니다. 그렇다면 사실 별 문제가 없을 겁니다.
먼저, 어떠한 노드를 방문했을 때, 반영이 되지 않은 값이 남아있다고 해 봅시다.

현재, 이런 상황입니다. 이 값을 반영하려면, 실제 값에, val을 반영하는 작업을 해야 합니다. 예를 들어서, 구간 합을 구해야 한다고 하면 어떻게 하면 좋을까요?

먼저 해당 노드의 값을 lz 값을 토대로 업데이트를 합니다. 예를 들어, x번째 노드가 관리하고 있는 구간이 [node_s, node_e]이고, 쌓여 있는 더하기 변환이 lz만큼이였다면, node[x]는, node[x]에 (node_e - node_s + 1)에 lz를 곱한 값을 더하면 될 겁니다. 이를, lazy , 혹은 누적된 변환 값을 실제 tree에 반영했다고 합니다.

그리고 이 변환값을 자식에게 누적시키면 됩니다. 이러한 일을 하는 함수를 delegate라고 표현하겠습니다. 그리고 val 만큼의 누적을 넘겨준 것을, +val로 표현했습니다. 예를 들어서, 자식 A에는 3만큼의 더하기 변환이 누적되었고, 자식 B에는 5만큼의 더하기가 누적이 되었다고 해 봅시다. 그러면 +val만큼을 추가로 누적시킨다면 어떻게 될까요?
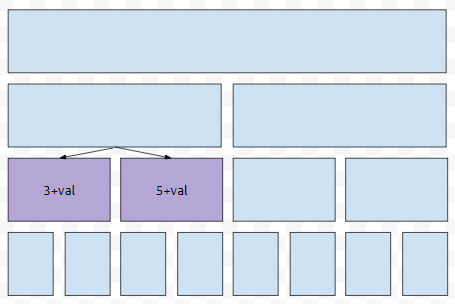
누적된 변환 값은 3+val, 5+val이 될 겁니다. 이 누적된 convert 값을 처리하기 위해서, 1편에서 설명드렸던 개념이 필요했어요. 차근 차근 생각해 봅시다. 이 과정이 끝난 후에는, 현재 내가 방문한 노드에는 lazy 값이 모두 반영된 실 값이 반영됩니다. 따라서, update 연산이 아닌, read류 연산, 예를 들어서 구간의 합을 구한다는 쿼리가 주어졌다. 그러면 현재 노드 위치에서, 누적을 반영하고, 그것을 자식에게 전파시키는 delegate를 수행한 다음에 반영된 값을 결과값에 더하면 됩니다.

그러면, calc 함수는 이런 식으로 작성하실 수 있습니다. 일반적인 점 쿼리에, 부분합을 구하는 세그먼트 트리와 다른 점은, 단 1줄밖에 없습니다. 5번째 줄에 delegate가 있다는 것입니다. 이 함수를 호출해서, tree[node_num]에 누적된 변환값을 반영시키는 작업을 한다는 것만 다릅니다.
문제는, 구간의 대표 노드들에 변환 k를 누적하는, 구간 합에서는 k를 더하는 쿼리가 들어왔을 때입니다.
이 때에는 대표 노드의 변환도 업데이트가 되는데요. 예를 들어서 [1, 4] 구간을 대표하는 노드를 방문했다고 해 봅시다. 그리고 이 구간에는, lz 만큼의 변환이 누적되어 있다고 해 봅시다.

그러면 먼저 lz만큼의 변환을 현재 [1,4] 구간을 대표하는 노드 값에다가 반영을 하고 자식에 전파합니다.
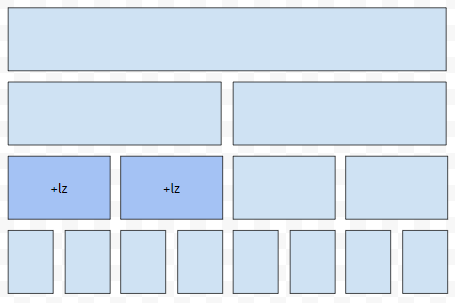
즉, 자식에 누적시킵니다. 각각 구간 [1,2], [3,4]를 담당하는 노드일 겁니다. 여기까지는 같습니다. 그런데, 우리가 현재 방문하고 있는 노드가 다음과 같은 3가지 경우 중 하나일 수 있어요. 현재 방문하고 있는 노드가 담당하는 구간과, 업데이트 해야 하는 구간이 겹치는 부분이 하나도 없다.
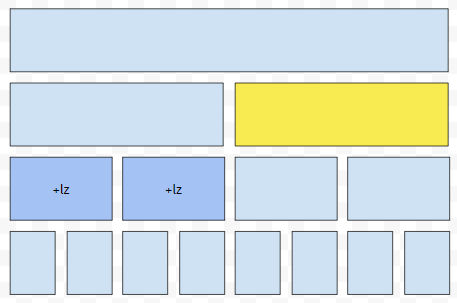
예를 들자면, 현재 [1, 4]를 방문하고 있어서, [1, 2]와 [3, 4]에 +lz만큼을 누적시켜 주었습니다. 그런데, 실제로 update 해야 하는 구간은 [5, 8]인 경우입니다. [1, 4]와 [5, 8]은 겹치는 것 조차 없어요. 그 경우에는 그냥 0을 리턴하고 나오면 됩니다.
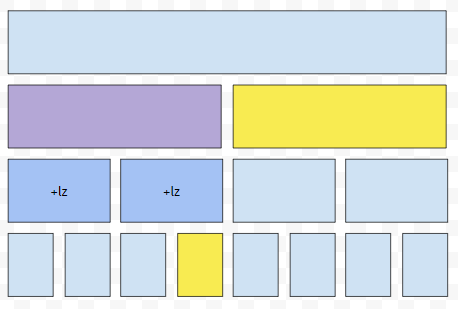
두 번째, 현재 방문하고 있는 노드가 담당하는 구간과, 내가 update 해야 하는 구간 둘이 겹치는 부분이 있는 경우입니다. 예를 들어서, [4, 8] 구간을 업데이트 해야 하고, 현재 있는 노드는 [1, 4]를 담당합니다. 그러면 [1, 4]와 [4, 8]은 겹치는 부분이 있기 때문에 파란색으로 칠한 자식 둘도 봐야 합니다.
그런데, 이 때에도 보라색으로 칠한 부분에 k만큼의 변환을 반영하지 말아야 합니다. 왜냐하면, 보라색 구간에 k만큼의 변환을 반영한다면, 이러한 의미이기 때문입니다.

업데이트 되지 말아야 할 1번, 2번, 3번에도 +k만큼의 변환이 반영이 됩니다. 고로, 이 때에도 반영은 하지 말아야 합니다. 반영을 하지 않고, 자식들을 재귀 탐색 하면 됩니다. 그러면 자식들도 반영이 될 거고, 반영된 자식값들의 합을 보라색으로 칠한 노드에 반영하면 됩니다.

세 번째, 현재 방문하고 있는 노드가 업데이트 해야 하는 구간에 포함되는 경우입니다. 예를 들어 구간 [1, 6]에 k만큼 더해야 하는데, [1, 4]를 방문하고 있는 경우입니다. 이 때에는, 어렵지 않습니다. 그냥 누적된 변환인 k를 현재 방문하고 있는 노드 [1, 4]의 누적 값에 넣습니다.
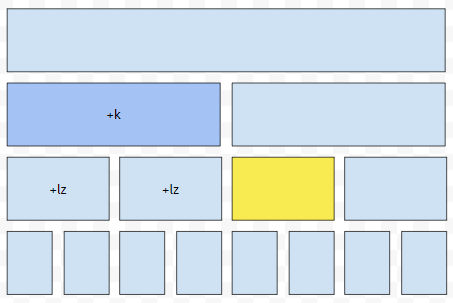
그 다음에, 이를 자식에다가 전파시켜 주고, 현재 방문하고 있는 노드에는 그 값을 반영시키면 됩니다.

그 다음에, 반영된 값을 돌려주면 됩니다. update 함수를 작성하면 아래와 같습니다.

여기서 주의깊게 보셔야 할 부분은 16번째 줄과 21번째 줄, 25 ~ 27번째 줄입니다. 패턴을 보면, delegate라는 함수는 lazy 프로퍼게이션 알고리즘에 공통적으로 들어가 있음을 알 수 있어요. 이 함수는 변환을 누적시키고, 트리에 반영시키고, 자식에 변환을 누적시키는 역할을 하는데요. convert를 쌓는다는 개념은, 1편을 보고 오시면 좋겠습니다. 사실 그 함수에 대한 이해는, 무언가를 누적하는 개념만 이해하면 무리 없이 구현하실 수 있습니다.
'자료알고 > 자료구조' 카테고리의 다른 글
| trie에서 공간을 줄이기 위해 포인터를 어떻게 쪼갤까요? (0) | 2020.05.05 |
|---|---|
| 랜덤 접근이 가능한 deque 자료구조를 chunk로 구현하면 어떤 이점이 있을까요? (6) | 2020.04.07 |
| 유니온 파인드 (union find) : 병합 연산과 루트를 찾는 연산만 있다. (2) | 2020.03.14 |
| 누적된 변환과 lazy propagation 알고리즘 (4) | 2020.02.29 |
| c++ set이나 map을 전체 순회하는 데 시간 복잡도는 얼마일까요? (4) | 2020.01.31 |


최근댓글