안녕하세요. 이번 시간에는 ConcurrentHashMap을 간단하게 보도록 하겠습니다. 이 글에서는 왜 이 친구를 쓸까? 정도만 보아도 되지 않을까 싶어요.
먼저 Collections의 SynchronizedMap는 이 글에서도 개략적인 구조를 설명해 드린 적이 있습니다. 간단하게 다시 보도록 하겠습니다. 먼저, mutex라는 잠금용으로 쓸 객체를 하나 둡니다.
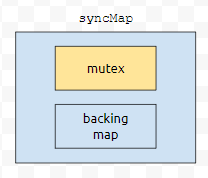
다음에 실제 map을 하나 두는데요. 여기서 mutex는 언제 쓸까요?

map에 접근할 때 동기화 용으로 쓰게 됩니다. get 메서드를 봐도 mutex에 synchronized를 걸어놓았어요.

그리고 put 메서드를 호출할 때에도 mutex에 synchronized를 걸어놓았어요. 그런데, Hash 기반에서의 자료 구조를 잘 생각해 봅시다. 얘네들은 버킷 단위로 돌아가는 자료구조입니다. map에 버킷 0번에 객체 0이 들어가고, 버킷 2번에 객체 2가 들어가야 한다고 해 보겠습니다.
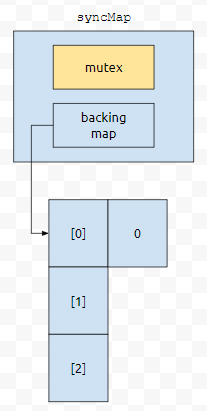
그러면 0번 객체를 0번 버킷에 넣는 동안에, 다른 쓰레드는 backing map에 접근하지 못합니다. 이미 mutex 객체를 가지고 잠궈 버렸기 때문입니다. 0번 객체에 넣는 작업이 끝난 후에, 2번 버킷에 2번 객체를 넣는 작업이 수행될 수 있을 거에요.

이렇게 말입니다. 그런데, 같은 버킷에 동시에 넣는 작업이면 동기화가 필요할 수도 있을 거에요. 왜?
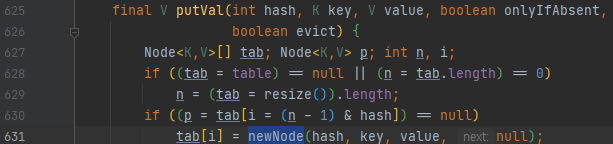
비어 있는 버킷에 대해서 두 쓰레드가 동시에 접근한다고 해 봅시다. 그러면, 이런 순서대로 수행이 될 수 있을 겁니다.

버킷이 비어 있다면 두 쓰레드가 630번째 줄을 수행할 때 true가 될 것이니, 두 쓰레드 모두 631번째 줄을 수행할 겁니다. 그런데, 631번째 줄은 해당 버킷이 가리키는 Node 객체를 대입하는 것입니다. 그래서, 쓰레드 1이 0번 객체를, 쓰레드 2가 3번 객체를 추가한다고 하면, 최종적으로 요래 나오게 될 겁니다.

0과 3이 추가되어야 하는데 3만 추가된 상황이 나타났어요. 그런데 잘 생각해 보면, 0번 버킷에 추가하는 것과 2번 버킷에 추가하는 것은 병렬로 수행해도 되는 부분입니다. 그런데, map 전체 단위로 동기화를 하다 보니, 병렬로 수행될 수 있을 거 같은 0번 버킷에 추가하는 연산과 2번 버킷에 추가하는 연산을 동시에 병렬로 수행하지 못하게 됩니다.
그러면, concurrentHashMap은 어떤 친구를 기준으로 lock을 걸까요? 중간에 expand가 되거나, table이 초기화가 된다던지 하는 복잡한 상황은 빼겠습니다. 대신에 이들은 추후에 다시 언급을 하도록 하겠습니다. 그냥 버킷에 들어가기만 하는 상황을 생각해 봅시다.
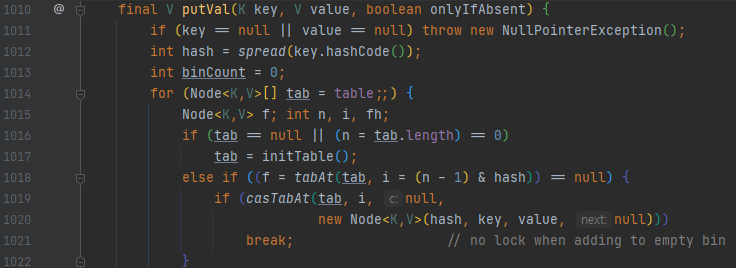
f가 보이는데요. 1018번째 줄을 보시면, (n - 1) & hash가 보입니다. 이 부분은 계산된 해시값을 가지고 몇 번째 버킷에 접근할 것인지를 계산해서, 접근해야 할 버킷을 돌려주는 역할을 합니다.
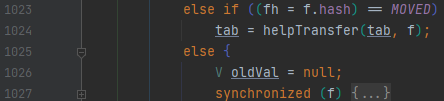
그리고 밑에 else 절을 보면 synchronized(f)가 있는데요. 이를 통해서 f를 기준으로 lock을 건다는 것을 알 수 있어요. 여기서 f는 버킷 하나를 의미합니다. 락이 걸리는 단위가 맵 전체에서 버킷 단위로 줄어들었습니다. 테이블이 초기화 된 상태입니다. expand가 되지 않고 단지 버킷에 키 하나만 추가되는 상황이라면 어떤가요?
0번 버킷에 0이 추가되는 상황이라면 lock이 요래 걸리게 될 겁니다.

이 때, map 전체에 lock이 걸린 게 아니라 0번 버킷에만 락이 걸린 상황이므로 그 후에 2번 버킷에 뭔가가 추가될 때에도 무리 없이 put 메서드를 수행할 수 있게 됩니다.
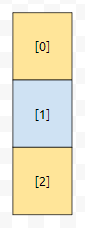
그러면, 그림이 요래 그려지게 됩니다. 그러면, 0번 버킷에 객체를 추가하는 것과 2번 버킷에 객체를 추가하는 작업을 동시에 수행할 수 있게 됩니다.
'OS > 이론' 카테고리의 다른 글
| spring boot logback MDC는 어떤 식으로 동작하는지 간단하게 분석해 봅시다. (0) | 2022.01.02 |
|---|---|
| python gil이 있으니까 thread safe 할까요? (4) | 2021.05.22 |
| race condition 을 이용한 toctou 에 대해서 알아봅시다. (0) | 2021.05.01 |
| java future 에 대해서 간단하게 이해해 봅시다. (4) | 2021.04.01 |
| java arrayblockingqueue : 고정 크기를 가지는 생산자 소비자 문제에 써 봅시다. (2) | 2021.02.13 |


최근댓글