안녕하세요. 조경완입니다. 어제 카톡 방에 이런 질문이 올라왔습니다. mutable한 객체를 키 값으로 넣었고, 맵이나 셋을 넣은 키를 어디선가 변경했는데, 왜 맵이나 셋 계열의 containsKey가 제대로 동작하지 않을까요? 사실, String을 키 값으로 삼으면 문제는 없습니다. 이것은 immutable 하기 때문입니다. 뮤터블의 반대 말이죠. im이 붙으면.
아래 예제 프로그램을 보겠습니다. 코드에서 필요 없는 부분은 생략하였습니다.
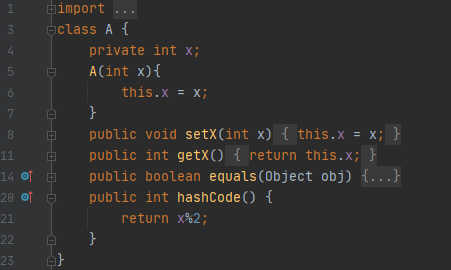
equals는 x 값이 같으면 true를 리턴하게 되어 있습니다. 그리고 hashCode는 x를 2로 나눈 나머지를 돌려줍니다.
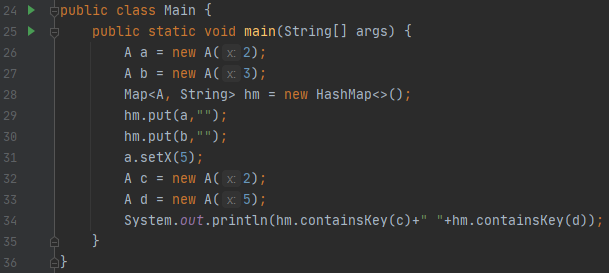
Main 함수를 보겠습니다. x에 2, 3을 넣은 객체 a, b를 hashMap에 넣습니다. 그리고, 객체 a의 x값을 2에서 5로 바꿉니다. 다음에, x에 2가 setting된 객체, 5가 setting된 객체가 있는지 찾습니다.

결과는 어떻게 나올까요? 둘 다 false가 나옵니다. 왜 이 둘이 false가 나왔는지 디버깅을 해 보겠습니다.

먼저, 객체 2개가 hashMap에 들어갔습니다. 여기까지는 그리 어렵지는 않습니다. 단지, 0번 버킷에 2, 1번 버킷에 3이 들어갔기 때문입니다. 문제는, a.setX를 하고 난 후입니다.

다시 hm을 보면, key값이 x가 2인 객체는, x가 5인 객체로 바뀌었음을 알 수 있습니다.
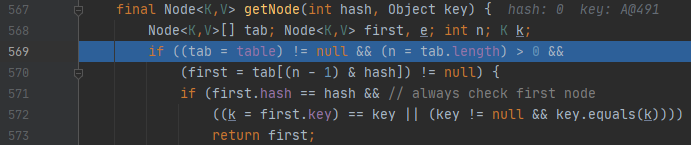
이제, containsKey로 들어가 봅시다. 이 메서드는 내부적으로 getNode를 호출하는데요. hashMap의 569번째 line에서 브레이크 포인트를 걸어보겠습니다.

그러면, 다음과 같이 변수가 들어가 있는데요. 여기서 중요한 것은, hash 값입니다. 이제 계속 안으로 들어가 봅시다.

572번째 줄을 보면, key.equals(k)가 있습니다.

여기까지 상황입니다. first가 slot_4였고, key는 A@488이였습니다. 이것은 x가 5인 상황이였습니다.
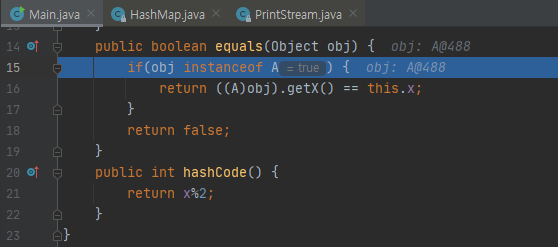
그러면 내부적으로 equals를 호출하게 되는데요. 트레이스를 따라가 보면, A의 equals를 호출함을 알 수 있습니다.
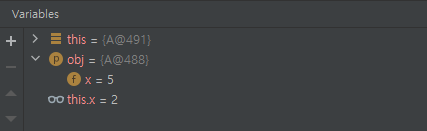
그런데, x 값이 다르네요. false가 나옵니다. 같지 않기 때문에 해당 버킷의 내부를 계속 돌 겁니다.

574번째 줄과 do while loop를 보면 알 수 있습니다. 여기까지 상황을 정리하면, 2가 들어가 있는 hash 값인 0을 토대로, 버킷에서 탐색하는데, 값이 없어서 null을 리턴했다 정도가 될 겁니다. 이것은 상식적으로 맞아 보입니다.
그런데 왜 5를 찾는 연산은 실패할까요?

다시 해당 상황으로 들어와 보겠습니다. 일단, hash 값은 1입니다. 1과 n-1을 and 연산한 값은 버킷 번호가 되는데요.

여기서 중요한 것은 first입니다. 당연하게도 첫 번째 요소부터 검사를 해야 겠지요.
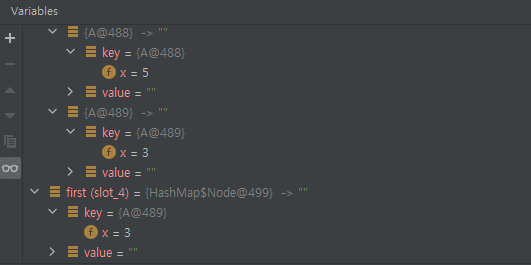
first는 A@489의 3입니다. 그리고 이것은 1번째 버킷 {A@489}에 있음을 알 수 있습니다. 정확히 말하면 List 정도가 되겠습니다. 문제는, 5라는 값은 엉뚱한 버킷인 {A@488}에 있기 때문에, 엉뚱한 바구니에서 값을 찾습니다. 따라서 없다고 나올 겁니다. 여기까지 상황을 정리하면 아래 그림과 같습니다.

처음에, 테이블에 아래와 같이 저장이 되어 있었습니다. 각각의 원소들은 버켓 (List)를 의미합니다.

a.setX(5)를 했더니, 요래 바뀌었습니다.

다음에, x가 5인 객체를 해시맵에서 찾으려고 하니, [1]번 버켓에서 찾아야 합니다. 왜냐하면 x가 5인 객체의 hashCode 값은 1이고, 이것을 토대로 버킷 번호를 계산하면 1이기 때문입니다. 그런데, 5인 객체는 없습니다. 왜? rehashing이 일어나지 않았기 때문입니다. 재해싱이 일어나면 올바르게 들어가는가는 이 글에서 중요하지는 않습니다.
단지, 우리는 hashCode 값에 영향을 끼치는 factor를 바꿔버리면 이상하게 들어가 버릴 수도 있다. 정도만 알고 있으면 됩니다.
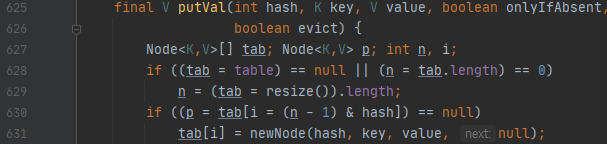
putVal을 보면, key는 참조 값임을 알 수 있습니다. 바깥에서 해시맵에 들어간 키 a를 a.setX(5); 이런 식으로 바꿔 버리면, 참조값은 안 바뀌지만, 그것이 가리키는 객체가 바뀐다는 것이 문제입니다. 얕은 복사라고 하면 좋을지는 잘 모르겠습니다만. 그렇다면, 자료구조에 대격변이 일어나지 않는 이상 잘못될 가능성이 있다는 이야기입니다.
아래 예제를 보겠습니다.

A를 Comparable하게 바꾸었습니다.

그리고 2, 3 순서대로 넣었습니다. 다음에, x값이 3인 키, x값이 1인 키를 찾으려고 합니다. 결과가 어떻게 나올까요?
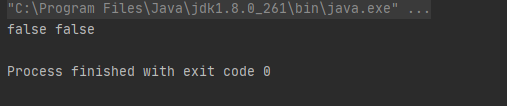
false, false가 나옵니다. 왜 그럴까요? 이것도 같은 방법으로 생각해 보겠습니다.
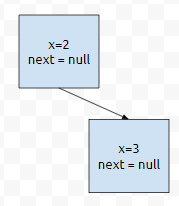
처음에 이렇게 들어갔던 상황입니다. x값이 현재 위치보다 크면, 우측으로 가게 되어 있습니다. 그런데 여기서 b.setX(1);을 수행했습니다.
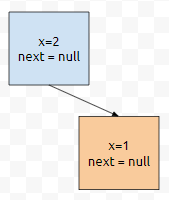
그러면 TreeMap의 규칙이 성립하나요? 아니면 깨지나요? 깨집니다. 그러면, 제대로 값을 찾을 수 있나요? Tree 계열 구조는, 현재 가리키는 값과 key와 비교해서, 크면 우측으로, 작으면 좌측으로 내려갑니다. 그런데, 우측에 있는 친구 중에, 키가 작은 것이 존재한다? 이것은 단순히 찾고 못 찾고가 아니라, 메모리 릭으로까지 이어질 수 있는 문제입니다.
이제 다시, 아래 코드를 보겠습니다.
클래스 A의 설계도입니다.
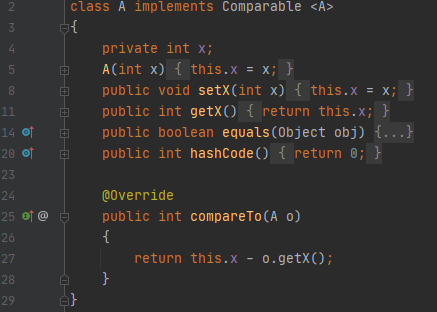
바뀐 것은 없고, 단지 hashCode 값이 무조건 0이라는 것만 바뀌었습니다.

테스트 코드를 설명해 보겠습니다. hm에 객체 key 10만개를 넣습니다. 그러면 같은 버킷에 바바바박 들어갈 겁니다. 이 키들 중에 딱 하나의 x값을 바꿉니다. 다음에 43 ~ 44번째 줄에서 2*U+1를 제외한, 1보다 크거나 같고, 200001보다 작거나 같은 홀수들이 있는지를 검사합니다.
여기서 중요한 것은 not found가 뜨면 안 된다는 겁니다. 테스트는 성공할까요?
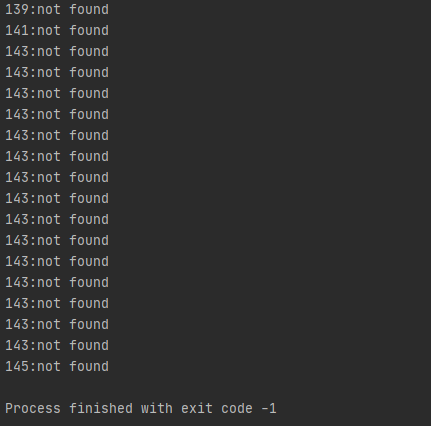
유감스럽게도 둘 다 false가 나오는 경우가 존재합니다. 왜냐하면, 키가 한 버킷에 바바바박 쌓였을 때 java8부터는 balanced Tree로 관리하게 되는데, 중간에 키 하나의 내용이 변하면, 그리고 그 즉시 업데이트가 되지 않는다면, 트리의 규칙이 깨질 수도 있습니다. 이것을 올바르게 잡기 위해서는 전체를 순회해서, 다시 rebuild를 해야 하는데, (하나의 키가 변경되면 그 즉시 업데이트가 일어나지 않는 이상, 키를 못 찾을 가능성도 생각해 보아야 합니다.) 이것을 수행하는 복잡도는 넣어야 할 원소 갯수가 n이라면 O(nlogn)입니다.
매번 그렇게 해야 할 이유는 없을 겁니다. 심지어, 업데이트는 안 했고, 단지 참조하고 있는 객체 내부에 있는 값이 바뀌는 건데. 이는, factor가 효율적인 비교를 위해서 Comparable<A>를 implements 한 compareTo까지 걸려 있기 때문입니다. 결론은, 제일 좋은 것은, 변할 수 있는 객체를 키 값으로 삼지 말고 (사실 그렇지 않은 것을 키로 삼으면 조심해야 할 것이 상대적으로 많으니) , 만약에 변할 수 있는 객체를 키 값으로 삼았을 때에는, 조심해야 한다는 것입니다.
'레퍼런스 > 분석' 카테고리의 다른 글
| Java의 String.valueOf 메서드의 동작과 lombok의 ToString 어노테이션의 스택 오버플로우 (0) | 2020.11.05 |
|---|---|
| 잘못 알고 있었던 java for each 구문과 modcount 필드 (2) | 2020.10.17 |
| java toLowerCase toUpperCase 를 수행하면 길이가 항상 같을까요? (4) | 2020.09.27 |
| 파이썬의 list.pop(0)을 쓰면 안 되나요? (0) | 2020.09.25 |
| 언급이 좀 되는 모 자료구조의 보조 해시 함수에 대한 이야기 (0) | 2020.09.02 |


최근댓글