안녕하세요. chogahui05입니다. 유니온 파인드 (Union find)는 2가지 연산을 지원하는 자료구조입니다.

a와 b를 같은 집합에 넣는 것은 merge 연산으로 합니다. 같은 집합에 있는지 검사하기 위해서, find 함수를 호출합니다. 이 둘을 수행하는 구조인데요. 이 중에서 오늘은 경로 압축에 대해서 알아보겠습니다. 이것만 적용해도 상당히 빠르게 수행할 수 있습니다. 얼마나 빠르게 수행하는지는, 추후에 작성을 하도록 하겠습니다.
먼저 find 함수부터 보겠습니다.

되게 간단해 보이는데요. 여기서, p[x]는 x에서부터 타고 올라갔을 때, Root를 의미합니다. x의 부모가 x라면, 즉 자기 자신이라면, -1입니다. 3번째 줄은, 기저 조건입니다. 만약에 x의 부모가 -1인 경우에 바로 x를 리턴해 버립니다. 그렇지 않은 경우에, 어떻게 동작하는지 봅시다.

먼저 3의 부모가 2였고, 2의 부모가 1이였다고 해 봅시다. find(3)을 호출한 경우에, 3의 부모는 있습니다. 따라서 5번째 줄의 p[3] = find(2)가 호출이 됩니다.

다음에, 2의 부모는 1이므로, find(2)는, p[2] = find(1)을 호출합니다.

콜스택을 그려보면 오른쪽과 같습니다. find(2)를 호출했을 때, 2의 부모가 있었기 때문에, find(1)을 호출합니다.
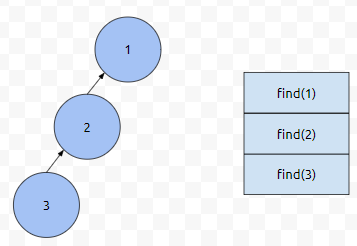
그러면, find(1)이 호출이 될 텐데요. 여기서 1의 부모는 없습니다. 따라서, 1이 리턴됩니다.

이 값이 연쇄적으로 리턴이 되게 됩니다. 즉, p[2]도 1이고, p[3]도 1이 됩니다. 왜냐하면 find(2)의 리턴값도, find(3)의 리턴값도 1이였기 때문입니다. find 함수가 수행되고 난 후에, 상태를 그려보면 아래와 같습니다.

3에서 1로 가는 경로가, Compress 되었음을 알 수 있어요. 이를 path compression이라고 합니다. 유니온 파인드 코드를 보면 제일 많이 보이는 코드이기도 합니다.
find 함수를 언급했으니, 이제 merge 연산을 언급할 필요가 있겠네요. 사실, 우리는 단순하게 a와 b를 merge 한다고 하면, 그냥 b의 부모를 a로 취하면 되는 것 아니냐고 생각하실 수 있습니다. 틀린 이야기는 아닌 듯 해 보입니다.
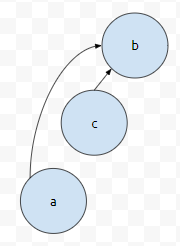
이런 경우를 하나 생각해 봅시다. a의 부모가 b입니다. 그런데, b의 부모를 a로 취한다고 하면, 그래프가 아래와 같이 그려질 겁니다.

이 상황에서 find(a)를 호출하면 어떻게 될까요? a의 부모는 b이고, b의 부모는 a이고, 계속 무한 루프를 돌 겁니다. 이는 모순입니다. 쉽게 말하면 내 부모님이, 내 자식이다. 랑 동급이니까요. 이런 상황을 방지하려면, a와 b가 같은 set에 속해있을 때, merge 작업을 수행하면 안 됩니다. 그러면 이것은 어떻게 판단하면 좋을까요?
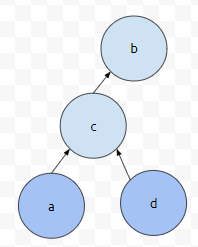
a의 Root는 b입니다. d의 root도 b입니다. 이 둘은 같은 요소에 있나요? 네. 따라서, find(a)와 find(d)가 같기 때문에, a와 d는 같은 요소에 속해있다고 답을 해도 됩니다. 이 경우에는 쿨하게 무시하시면 됩니다. a의 Root와 d의 Root가 다른 경우가 문제인데요.
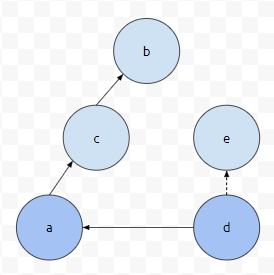
이 때 무작정 d의 부모가 a다. 라는 정보로 업데이트 하면 문제가 발생합니다. 이미 d의 부모는 e였기 때문입니다. 그리고 이렇게 되어버리는 경우에, e의 Root와 d의 Root는 같지 않습니다. 분명한 것은, 이 연산이 일어나기 전에는 d의 Root가 e였습니다.
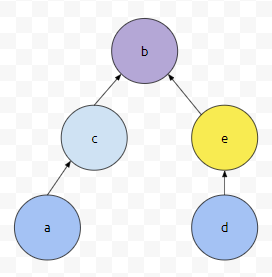
그러므로, d의 루트를 rd라 하고, a의 루트를 ra라고 하면, p[rd] = ra 이런 식으로 업데이트 해야 합니다.

이를 코드로 나타내면 위와 같습니다. 그러면 두 쿼리에 대한 처리는 다 끝났습니다. 두 원소가 같은 집합에 있는 것을 물어보는 쿼리와, 두 원소를 Merge 하는 연산은 크루스칼 알고리즘에서도 많이 쓰이니, 알아두면 좋겠습니다.
'자료알고 > 자료구조' 카테고리의 다른 글
| 랜덤 접근이 가능한 deque 자료구조를 chunk로 구현하면 어떤 이점이 있을까요? (6) | 2020.04.07 |
|---|---|
| 세그먼트 트리 구조에서 lazy propagation을 적용하는 코드를 뜯어봅시다. (0) | 2020.03.31 |
| 누적된 변환과 lazy propagation 알고리즘 (4) | 2020.02.29 |
| c++ set이나 map을 전체 순회하는 데 시간 복잡도는 얼마일까요? (4) | 2020.01.31 |
| 균형 이진 트리 : 제약 조건이 맞지 않으면 추가적인 연산을 한다. (2) | 2020.01.11 |


최근댓글