ps를 하시다 보면, 좌표 압축이라는 이야기를 심심치 않게 들으실 수 있습니다. 간단하게 말해서, 데이터를 정렬해서, 다시 순서를 부여하는 것을 말합니다. 특히 쿼리 문제에서 많이 보이는데요. 구간이 10^10개, 10^18개가 있는데, 쿼리가 단지 10만개라면, 10^18개를 다 들고 있지 않고, 중요한 구간이나 숫자만 들고 있는 기법입니다. 그러면 압축이 될 거에요. 이런 문제를 생각해 봅시다.

자. 여기서, Lv랑 Rv, 그리고 k는 [0, 10^10]에 속하는 정수라고 해 봅시다. 그리고 n과 Q가, 구간 [1, 10^5]에 속하는 정수라고 해 봅시다. 그러면, k와 Lv, Rv가 [0, 10^10] 범위에 속하는데, 어떻게 하면 좋을까요?
오프라인 처리가 가능하다면, 그냥 k값하고, Lv, Rv를 적절히 잘 잡아서 처리하면 될 거에요. 그런데 문제는, Lv, Rv, k는 [0, 10^10]의 범위를 가지기 때문에, 단순히 깡으로 좌표에 때려 박으면, 공간 복잡도가 O(10^10)이 됩니다. 예를 들어, 쿼리가 2개가 들어왔고, 1번째 1번 쿼리는 arr[4]을 3억으로 변경하는 거였고, 2번 쿼리는 Lv가 1억, Rv가 100억이였다고 해 봅시다. 그리고 n은 10^5였다고 해 봅시다. 이 때 상황을 그려보도록 하겠습니다.
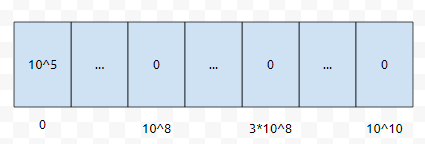
먼저, 초기 count 배열은 위와 같습니다. count[0]에 10만이 들어간 상황입니다.
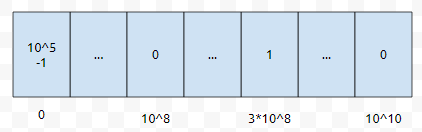
다음에 count[3억]의 값을 1로 업데이트를 하고, count[0]을 10^5-1로 업데이트를 합니다.
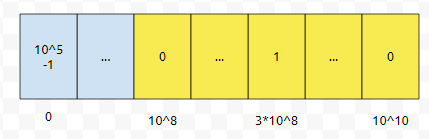
그 다음에 우리는 구간 [10^8, 10^10]에 있는 count 배열의 총 합을 구했습니다. 그런데, 이거를 그냥 10^10개의 크기를 가지는 배열을 선언하면, 꽤나 큰 낭비일 거에요. 그런가요? bitset으로 어떻게 잘 압축을 한다고 해도 1024MB가 넘어갑니다. 심지어 누적합을 구한다. 그러면, 누적합에 대해서도 10^10개의 int형을 저장하는 배열을 선언해야 하는데요. 그러면, 10^6이 대략 1MB이니까, 10^4에 4를 곱한, 40GB 정도를 써야 합니다.
여기서 한 가지 생각을 해 봅시다. 어짜피 쿼리 Q번을 하는 동안에 계속 count값이 0인 것들은 들고 있을 필요가 없습니다. 즉, 의미 없는 구간입니다.
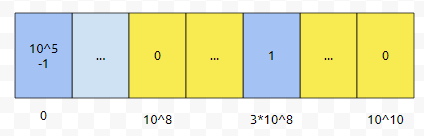
그러면, 그 많은 구간 중에서, 0과 3억을 제외하고는 의미가 없다는 겁니다. 그렇기 때문에, 파란색 부분만 봐도 무난합니다만, 구간 쿼리 Lv, Rv도 생각해 봅시다.
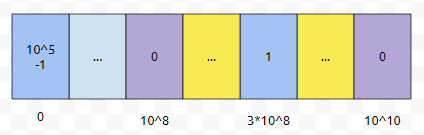
보라색 부분은 Lv, Rv가 들어온 수들인데요. 10^8, 10^10 이렇게 2개가 있습니다. 그러면, 군청색으로 표시한 것과, 보라색으로 표시한 것 외에는 의미가 없는 구간이라는 것을 눈치 채셨을 겁니다.
그러면 이것을 어떻게 압축할까요? 간단합니다.
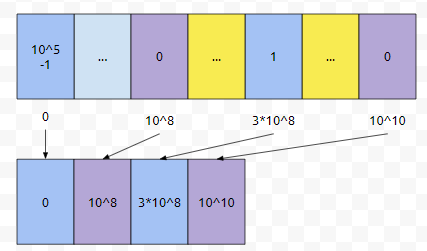
배열의 값을 k로 변경하라는 쿼리가 들어오면, k를 v에 넣고, Lv에서부터 Rv 이하인 뭔가를 구하는 쿼리가 들어오면, Lv와 Rv를 v에 넣습니다. 그리고 정렬을 한 다음에, 중복을 제거하면 됩니다. 이것을 코드로 구현하면 아래와 같습니다.
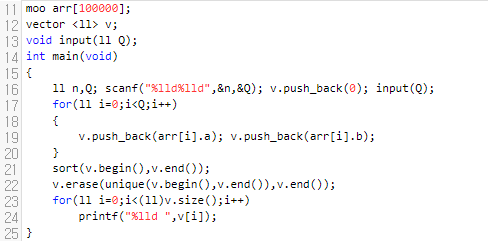
21번째 줄에서, sort를 하고 있어요. 사실, op가 1일 때, 2일 때 구분 안 해도 되느냐고 물어보실 수 있는데요. 전역 변수인 경우에는 0으로 초기화가 되니, 걱정하실 필요는 없어요. 설령 쓰레기 값으로 초기화 된다고 해도, 문제 푸는 데 지장은 없다는 것을 알 수 있어요. 그러면 v를 sort를 하고, unique 함수랑 erase를 이용해서 중복된 데이터를 제거하고 있어요.
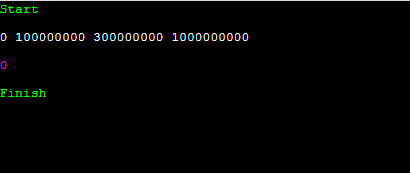
그러면 v에는 다음과 같은 데이터가 들어갑니다. 그러면, 이걸 어떻게 활용할까요? 일단 압축된 데이터가 4개짜리 배열이고, 벡터 v에 [0, 1억, 3억, 100억]이 있는데요.
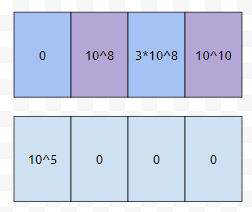
먼저 count 배열은 위와 같이 초기화가 되어 있습니다.
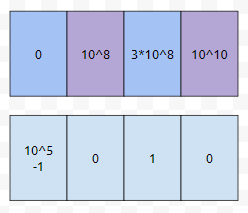
다음에, arr[4]에 3억이 들어갔습니다. 이는 arr[4]가 2로 변했다고 처리하면 됩니다. 왜냐하면 압축한 것에 의하면, 0, 1억, 3억, 100억 이외에는 쿼리에 등장하지 않기 때문입니다. 그러면, co[0]은 하나 감소하고, co[2]는 하나 증가했다고 처리하면 됩니다.
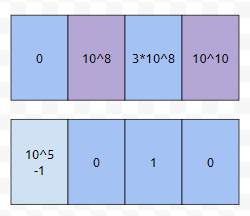
다음에 구간 [10^8, 10^10]을 처리해야 하는데요. 이는 어떻게 하면 좋을까요? 10^8은 v의 1번째, 10^10은 3번째 원소입니다. 따라서, 압축된 배열에서 [1, 3] 구간에 있는 합을 구하는 것과 동치입니다. 쿼리를 아래와 같이 바꿀 수 있습니다.

이것은, vector v에서 3억, 10^8, 10^10이 각각 몇 번째에 있는지 찾는 연산을 빠르게 하면 가능합니다. lower_bound는 정렬된 벡터에서 이러한 연산을 효율적으로 수행합니다.

23 ~ 27번째 줄이 어떤 일을 수행하는지 주의깊게 보시면 좋겠습니다. v에는 최대 2Q + 1개의 자료가 들어가기 때문에, 구간을 10^10개를 보는 게 아니라, 2Q + 1개만 보아도 됩니다.
'자료알고 > 알고리즘' 카테고리의 다른 글
| 플로이드 알고리즘 : 어떻게 최단거리가 갱신되는가? (9) | 2020.03.03 |
|---|---|
| 백준 화성지도 : 구간에 장벽을 세운다. (5) | 2020.02.24 |
| 백준 balanced cow subsets : 반으로 잘 쪼개 봅시다. (6) | 2020.02.10 |
| 부분 문제 그리고 메모이제이션 : 다이나믹 프로그래밍 할 때 많이 나오는 데 무엇일까요? (11) | 2020.02.07 |
| 트리에서 최단 경로를 구하기 위한 또 다른 방법? (0) | 2020.02.02 |


최근댓글