파이썬에는 ==와 is가 있습니다. 이 둘의 차이를 알아봅시다.
먼저 is 연산자는 identity를 비교합니다.

설명을 보면 알 수 있습니다. 같은 오브젝트를 가리키면 x is y가 참값을 가집니다. 그렇지 않으면, false가 됩니다. 반면에 ==는 동등성을 비교하는 것인데요. 이것만 보면 헷갈리실 수 있으니, 예제를 보겠습니다.

dog 객체가 2개 있습니다. a와 b는 'cho'라는 정보를 담고 있는 강아지 객체입니다.
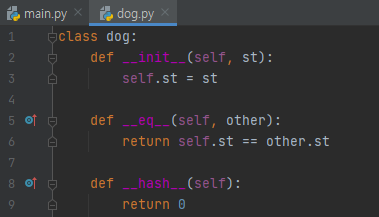
보시면 __eq__하고 __hash__가 재정의 되어 있음을 알 수 있습니다. __eq__는 단지, st만을 가지고 비교하게 됩니다. a와 b의 필드 st의 값은 'cho'로 같았습니다. 그리고, 문자열은 내용이 같으면 참입니다. 어찌 되었던 Dog('cho')와 Dog('cho')는 내용이 같다고 할 수 있습니다. 문서를 보시면 ==이 __eq__를 호출한다고 되어 있습니다.

그런데, a is b가 출력되지 않았습니다. 이는, a와 b가 같은 내용을 가지고 있지만, 같은 객체가 아니기 때문입니다.
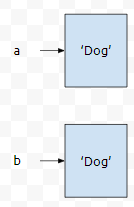
이 상황을 그림으로 그려보면 위와 같습니다.
그런데, __eq__를 구현하면 항상 귀신같이 따라 나오는 것이 있습니다. 바로 __hash__입니다. 자바에서 equals를 구현하면, 어떤 메소드를 재정의 하라고 많이 하나요? hashCode였습니다. 파이썬에서는 __hash__입니다. 이것을 구현하지 않는다면 어떤 일이 일어나는지는 조금만 찾아보셔도 나올 듯 하니, 다른 이야기를 해 보겠습니다. 자바에서 equals를 구현했는데, hashCode를 구현하지 않은 경우에 어떤 일이 일어날 수 있는지는 설명을 드렸습니다. 상당히 중요하니, 짚고 넘어가시는 게 좋겠습니다.
[관련글]
equals를 구현했는데 hashCode를 구현하지 않으면 어떻게 될까요?
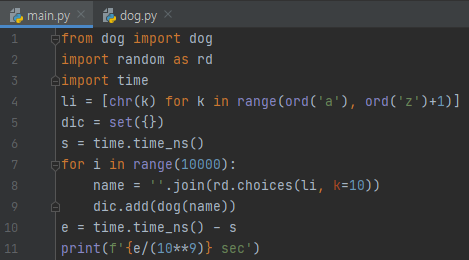
위 프로그램은 이름을 random하게 뽑은 Dog 객체를 set에다 넣는 모습입니다. __hash__의 리턴값이 0으로 되어 있었습니다. 1만개를 넣었는데요. 시간이 얼마나 걸렸을까요?

6.339999초가 나왔습니다. 2만개를 넣으면 어떻게 될까요?

27.9034565초가 걸렸습니다. 대략 4.4배 차이인데요. 2의 제곱이 4입니다. set에 넣은 원소의 갯수를 n이라 할 때, 이 프로그램의 시간 복잡도는 대략적으로 O(n^2)임을 알 수 있어요. 그런데 잘 생각해 보면, 파이썬의 dictionary라던지, set은 키 값을 효율적으로 찾기 위해 만들어진 구조입니다.
그런데, 해당 프로그램의 복잡도가 O(n^2)였다는 이야기는 찾는 연산이 효율적이지 않았다는 이야기가 됩니다. 한 버켓에만 바바바박 몰려 있으니 당연할 수 밖에 없을 겁니다. 키가 중복되지 않게 하려면 키를 추가할 때, 해당 키가 있는지도 검사해야 할 겁니다. 그런데 한 버킷에 충돌이 많이 일어나면 어떨까요? 바바바박 충돌된 것들에 대해서 다 검사를 해 줘야 할 겁니다. 엄청난 비효율의 냄새가 납니다.
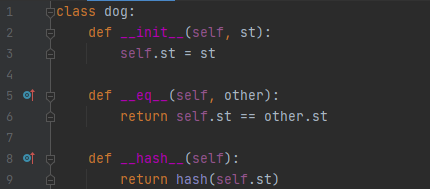
그런데, hash 메서드를 이용하면 이야기가 달라집니다.

1만개의 아이템에 대해서 단 0.015초만에 추가가 완료되었음을 알 수 있습니다. 이는 한 버킷에 너무 많이 skew가 되지 않기 때문입니다. 해당 문서를 조금 더 읽어 보시면 어느 정도 이해가 되실 듯 싶습니다. 왜 ==을 설명하면서 __eq__을 설명했고, __hash__를 설명했는지 천천히 보셔도 좋을 듯 싶습니다.
'코딩 > 파이선' 카테고리의 다른 글
| 내가 쓰고 있는 파이썬 버전과 구현체를 알아봅시다. (0) | 2021.04.17 |
|---|---|
| 큐를 사용할 때 이용하는 파이썬 collections deque (2) | 2021.04.15 |
| 파이썬 dict vs OrderedDict : 예전에는 후자만 순서가 유지되었다. (0) | 2021.03.30 |
| 파이썬 sample vs choices 의 차이를 알아봅시다. (0) | 2021.03.23 |
| 파이썬 삼항 연산자 : 간단한 조건 판단에 쓰면 유용하다. (0) | 2021.03.18 |


최근댓글