자료구조는 어떻게 공부해야 하는가? 사실 명확하게 답을 드리지는 못하겠습니다. 문제 상황이 다르게 바뀌었을 때, 어떤 구조로 어떻게 optimize를 시켜야 하는지 생각해 보면, 생각보다 도움이 많이 될 듯 싶어요. 프로그래머스에는 '큰 수 만들기' 라는 문제가 있는데요. 이것을 어떻게 해결해야 하는지. 그리고 들어올 수 있는 문자 집합이 커지면 또 어떻게 해결해야 하는지 천천히 보도록 하겠습니다.
문제는 아래와 같습니다.

단, 남은 수들의 순서는 바뀌면 안 됩니다. 이 문제의 조건만 조금 바꿔서, 소문자로만 이루어진 길이 ? 이하의 문자열에서 ?개를 지워서, 사전순으로 가장 앞선 것을 만들라는 문제가 코테에 출제 되었습니다. 문자 집합만 다를 뿐이지, 풀이 자체는 동일하다는 거 보이시나요? k개를 일일히 선택해서 지우는 방법으로는 당연하게도 시간 초과를 피할 수 없을 겁니다. 그러면 어떻게 해야 할까요?

4자리 숫자가 있다고 해 봅시다. 이 중 2개를 지웠을 때, 최대한 크게 만들려고 합니다. 그러면, 4-2 = 2자리 숫자를 만들기 위해서, 선택 가능한 집합이 어떻게 될까요?

노란색 중에 선택할 수 있을 겁니다. 만약에 7을 선택하면 어떨까요? 이걸 먼저 select 하면 2자리 수를 만들 수 있을까요? 아닙니다. 그러니, {2, 1, 4} 중 하나를 택하면 되는 것입니다.
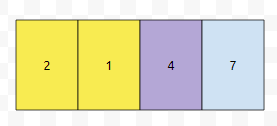
4를 선택했습니다. 그러면 그 다음에 선택 가능한 집합은 어떻게 될까요? {2, 1}은 선택 가능할까요? 아닙니다. 4가 selected 되었기 때문에 그 앞에 있었던 수들은 선택 불가능합니다.
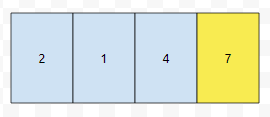
그러면, 7만 선택 가능합니다. 따라서, "2147"이 들어왔을 때, 2개의 수를 지워서 만들 수 있는 가장 큰 수는 47이 됩니다.

그러면 이 경우에는 어떨까요? "7675" 입니다. 1번째 자릿수로 가능한 후보해는 7, 6, 7 이렇게 3개입니다. 그러면, 이 중, 7을 선택해야 하는 것은 자명한데요. 어디에 있는 7을 선택해야 할까요?
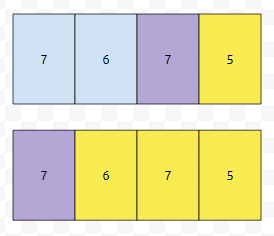
당연하게도 앞에 나오는 7을 선택해야 합니다. 앞에 나오는 7을 선택했다면 2번째 자리에 넣을 수 있는 집합이 6, 7, 5가 되는데요. 뒤에 있는 7을 택했다면, 넣을 수 있는 집합이 5밖에 없기 때문입니다. 이를 종합해서 코드를 작성하면 아래와 같습니다.

먼저 처음에, 가능 집합을 초기화 합니다. n개 중 k개를 지운다는 것은 n-k를 선택한다는 것과 동치이므로, select는 n-k가 됩니다. 그러면, 첫 자리가 될 수 있는 위치는 [0, n-select)일 거에요. n-select만큼 돌면서, 먼저 적절한 자료구조에 넣는데요. 문자열에 나오는 문자 집합이 10개밖에 되지 않기 때문에, count 배열에 넣어도 됨을 알 수 있어요.
다음에 f 함수는, 가능 집합에서, 우리가 택해야 하는 최댓값을 선택하는 함수입니다. 예를 들어 "8453"에서, k = 2일 때, 1번째 자리를 택하기 위해서, 8, 4, 5 중에서 골라야 할 것인데, 그 중 8을 선택하는 것입니다. 그리고 del 함수를 잘 보아야 하는데요. 현재 pos는 가능 집합의 시작 위치를 나타내고 있습니다. 이게 어떠한 값으로 업데이트가 되는데요.

이것은 문제의 숫자를 만난 처음 위치입니다. 그러면, 현재 pos부터 순회하면서 보면 될 거에요. 시간 복잡도는 O(10|s|)입니다.
문제는 나올 수 있는 문자 집합이 10개, 26개가 아니라, 10^5개, 이렇게 커지는 경우를 생각해 봅시다.

이 경우 40번째 줄에 int i = 9대신, i = 100000이 들어갈 겁니다. 그러면 1번 f 함수를 호출할 때 마다 10만번 루프를 돌고, 문자열의 길이가 100만이라면, 대략 1000억번의 연산을 해야 할 겁니다. 이건 매우 비효율적입니다. 그런데 우리는 사실 이 문제의 답만 구하고 나면, 가능 집합을 update 하는 것은 단순히 순회만 잘 하면 되기 때문에, 문제의 답을 구하는, f 함수를 optimize 할 필요가 있다는 것을 알 수 있습니다.
그러면, 이걸 어떻게 보는 게 좋을까요? 다시 f 함수의 목적을 잘 생각해 봅시다.

초록색 부분을 우선 순위가 가장 높은, 최적의 해로 바꿔 봅시다. 이 집합의 크기는 많아봤자, |s|를 넘어가지는 않을 겁니다. 그러면, 삽입, 삭제, 가장 높은 priority를 가진 item을 빼는 연산이 O(log(|s|))만에 된다면, 시간 내에 돌아갈 수 있을 거에요. 즉, 우리는 우선 순위 큐를 써서, 최적화를 할 수 있다는 것을 알 수 있어요.
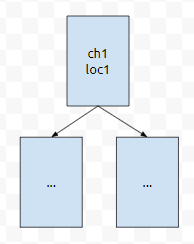
우선 순위는 어떻게 판단해야 할까요? 사전 순으로 뒤에 있는 것이라면, 문자가 크면서, 위치가 작은 것이 priority가 높아야 할 거에요. 앞에 있는 것이라면, 문자가 작으면서, 위치가 작은 것이 우선 순위가 높아야 할 거에요.
그렇다면, 15번째, 19번째 줄은 co 배열에 넣는 것 대신에, priority_queue에다가 <character, loc>에 대한 정보를 넣으면 될 거에요. 여기까지는 크게 어렵지 않아요. 그리고 del 함수도 크게 바뀌는 것이 없습니다. 아니, 오히려 del은, 더 간단해 질 수 밖에 없습니다.

왜냐하면, string의 x번째 원소가 우리가 찾는 ch인가만 확인해서, 시작 position 값을 업데이트 하기만 하면 되거든요.
f함수가 많이 바뀌는데요. 우선 순위를 결정하는 1차 기준이 ch, 2차 기준이 loc입니다. 여기서, loc1이 [pos, ~] 구간에 속하면 그냥 선택하면 됩니다. 문제는 loc1 < pos인 경우인데요. 이 때에는 invaild한 것이 되어 버립니다.
따라서, 이 경우, pop을 하면 됩니다. pq의 top의, loc1이 pos보다 크거나 같게 될 때 까지.

f 함수를 대략적인 슈도 코드로 표현하면 위와 같습니다. 자료구조는 이렇게 문제 상황을 바꿔가면서 고민해 보시는 것도 도움이 많이 되는 듯 싶습니다.
'자료알고 > 자료구조' 카테고리의 다른 글
| 우선순위 큐 : 부모가 자식들보다 rank가 높다. (0) | 2019.12.16 |
|---|---|
| k번째 숫자 구하기 : 트라이(Trie) 구조를 이용해 봅시다. (2) | 2019.12.05 |
| 완전이진트리 vs 포화이진트리 : 이 둘에 대해 알아봅시다. (7) | 2019.11.09 |
| 전치 행렬 (Transpose matrix) : 왜 중요한가? (2) | 2019.10.13 |
| 희소 행렬 (sparse matrix) : 어떤 정보가 중요한가? (6) | 2019.09.27 |


최근댓글