c++에서 string을 처리할 때, 구분자가 여러 개 붙어 있는 경우 split를 어떻게 할까요? c의 string.h에서는 strtok으로 된다고 하는데. 한 가지 방법 중 하나는, 문자열을 순회하면서, 해당 문자가 구분자인지 검사하는 것입니다.

제 목표는 token_ret 메서드를 구현하는 것입니다. 2번째 인자는 delimiter들을 넘깁니다. 쉽게 말해 구분자인데요. :과 -와 공백을 넘겼습니다. 이들을 기준으로 split 하겠다는 의미입니다.
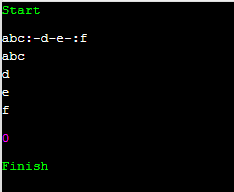
실행 결과는 위와 같이 나와야 해요.

인풋이 이렇다고 해 봅시다. 양 끝단 처리가 어려울 듯 하니, 더미 2개를 넣읍시다. 하나는 문자열 시작 위치 바로 전인 -1, 다른 하나는 문자열의 끝인 size of string length를 넣을 겁니다.

이 둘은 더미 역할을 하게 될 겁니다. 이제 맨 처음 위치부터 끝 위치 전까지 탐색을 해 보도록 하겠습니다.
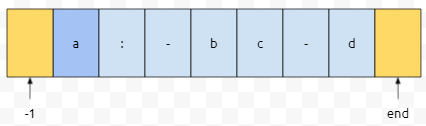
먼저 0번째 원소인 a는 구분자에 속하지 않아요. 그냥 넘겨도 무난하겠죠.

1번째 원소는 :인데요. 이것은 구분자에 속해요. :가 구분자에 속하고, a가 구분자에 안 속하는지 검사하는 것은 delimiter string에서 찾으면 되는데요. for loop를 돌면서 찾는 방법이 있습니다. 그런데, 레퍼런스에 이미 그 기능을 수행하는 find 메서드가 있습니다. 문서를 보시면 char를 넘겼을 때에는 문자의 최초 위치를 찾는다고 되어 있어요. 만약에 이 값이 -1이 아니라면 있다는 소리입니다.
-1이 아니라면 어떻게 할까요? 그냥 해당 위치에 구분자가 있구나. 표시만 하시면 됩니다. 예전에 이에 대해서 글을 쓴 적이 있는데요. 참고해 주시면 되겠습니다.
[관련글]

1이라는 위치를 따로 저장해 놓습니다. 다음에 2번째 원소인 -를 볼 건데요. 이것 역시 구분자에 속합니다. 따라서, 2번에도 구분자가 있다고 표시해 주면 됩니다.
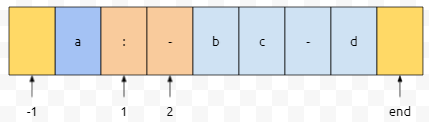
대충 이렇게 말입니다. 2번째까지 보았을 때 알 수 있는 것은 -1, 1, 2, end번째에, 구분자가 있다는 것입니다.
이제, 끝까지 순회해 보면 어떨까요?

그러면, 5번째 위치에도 구분자가 있다는 사실을 알게 될 겁니다. 이제, 우리는 -1, 1, 2, 5, end에 delimiter가 있다는 사실을 어딘가에 저장하고 있다가, substring을 뽑을 때 쓰기만 하면 됩니다.
이제, 코드를 보도록 하겠습니다.

먼저, ori는 원본 스트링을 의미합니다. d는 구분자들을 모아놓은 것들을 의미합니다. 다음에 de는 delimiter가 나타난 위치를 모아놓은 벡터입니다. 9번째 줄에 -1을 넣고, 16번째 줄에 ori.size()를 넣었는데요. 더미 처리를 위해서입니다. 12번째 줄에, d.find(ori[i]) == -1인 경우에 continue를 틀었는데요. ori[i]가 delimiter에 있는 문자가 아닌 경우에는 구분자가 아닙니다. 따라서, de에 넣을 필요가 없습니다.

이제 이 de를 가지고 어떻게 하면 될까요? de는 delimiter가 나타난 위치입니다. 따라서, 이전에 구분자가 나타난 위치를 p라 하고, 현재 구분자의 위치를 c라 하면, p+1부터 c-1까지 뽑으면 됩니다. 19번째와 20번째는 이를 의미합니다. 21번째 줄에 s가 e보다 크다는 것은 무엇을 의미할까요?
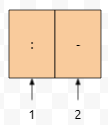
de[i-1]이 1이고 de[i]가 2라 해 봅시다. 그러면 de[i-1]+1은 2이고, de[i]-1은 1일 겁니다. 이 때 s > e가 됩니다. 즉, 구분자가 연속해서 나타났다는 의미인데요. 이 때에는 결과 벡터에 넣을 이유가 없으므로 continue를 해 버린 것입니다. 생각보다 긴데요. 이 방법 말고도, regex를 이용하는 방법이 있어요. 그것을 이용하면 코드의 길이를 꽤 많이 줄일 수 있으니, 참고하셔도 좋겠습니다.
'레퍼런스 > 예제' 카테고리의 다른 글
| c++ tuple 사용법을 예제와 문제를 통해서 알아봅시다. (2) | 2021.06.28 |
|---|---|
| c++ multiple delimeters에 대해 tokenize를 regex를 이용해서 해 봅시다. (0) | 2021.06.18 |
| 파이썬 randint randrange : 랜덤하게 수를 뽑을 때 쓴다. (0) | 2021.05.17 |
| c++ stoi 함수 : string to int를 할 때 많이 이용한다. (0) | 2021.05.05 |
| java treemap ceilingkey higherkey floorkey lowerkey 를 써 봅시다. (6) | 2021.05.04 |


최근댓글