질문이 하나 들어왔습니다. 아래에 있는 foo 함수의 시간 복잡도는 어떻게 되나요?
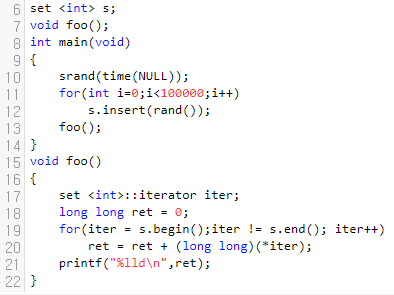
쉽지 않은 질문입니다. c++에서 map이나 set은 self balanced binary Tree로 되어 있습니다. 흔히 '균형 트리' 라고 이야기를 합니다. 중요한 것은 어느 기준 점을 기준으로 왼쪽은 작은 것이, 오른쪽은 큰 것이 저장이 되어 있다는 것입니다.
set이나 map이 Binary Tree의 속성을 가진다는 것은 시간 복잡도를 계산하는 데 굉장히 중요한 정보입니다.
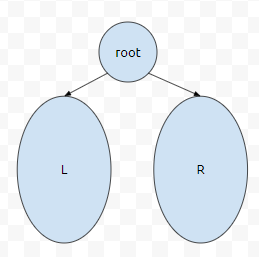
즉, root를 기준으로 작은 것은 L, 큰 것은 R 부분에 있습니다. 그렇다면, iterator를, s.begin()부터, s.end()에 도달할 때 까지, 순회한다고 생각해 봅시다. 즉, 작은 것부터 큰 순서대로 순회를 한다고 하면 어떻게 하면 될까요?

먼저 root에 방문을 합니다. root의 왼쪽으로 향하는 것이 있습니다. 그렇다면 L로 들어갑니다.
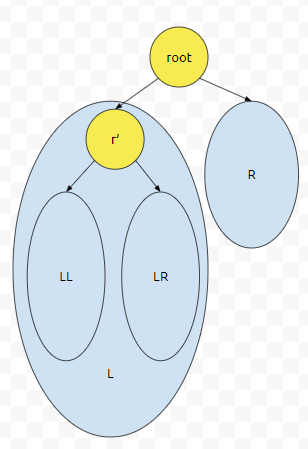
L의 root를 r'이라 해 봅시다. r'에서 왼쪽 부분에 있는 subTree를 LL이라 하고, 우측에 있는 subTree를 LR이라 합시다. 그러면, 처음 탐색을 시작하는, s.begin()은 어디에 있을까요? LL 안에 있을겁니다. 자. 그러면 r'은 언제 방문을 하나요? root에서 r'으로 내려올 때. 그러니까 위의 상황입니다.

다음에 LL을 방문한 다음에 r'을 방문할 겁니다. 이 때, r'는 탐색중이 아닌, 방문 check가 됩니다.

그런데, r'의 오른쪽 자식인 LR을 방문하지 않았습니다. 그렇기 때문에 LR도 탐색을 해야 합니다.
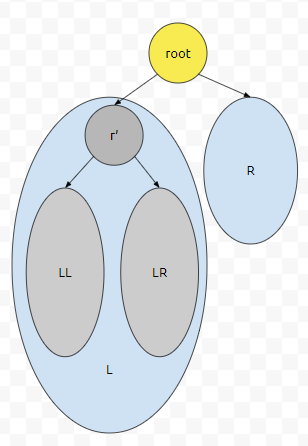
다음에 LL과 LR을 모두 탐색한 경우를 생각해 봅시다. LR의 마지막 원소의 다음 원소를 찾으라는 Query가 떨어진 경우에, 일단 r'까지 올라옵니다. 다음에 r'으로 올라올 건데요. LR의 마지막 원소보다는 r'이 작습니다. LR에 속해있는 것들은 r'보다 크기 때문입니다. 그러므로 parent로 올라갑니다.
root는 어떨까요? LR은 L에 속해있고, L에 속해있는 모든 원소들은 root보다 작습니다. 따라서, LR의 마지막 원소의 다음 원소는 루트 (root) 입니다.
그러면, foo 함수가, 모든 노드를 최대 small_visit 이하로 visit를 할까요? small_visit는 대략 10 정도로 잡아 봅시다. 노드 K는 최악의 경우에 2개의 자식을 가지고 있을 겁니다. 그러면 순회를 할 때, 3가지 상태가 나올 수 있습니다.

r을 방문했는데, 자식들을 모두 방문하지 않은 경우가 있습니다. 이 경우에는 왼쪽 자식으로 내려갈 겁니다.

왼쪽 자식만 방문한 경우. 이 경우, 오른쪽 자식으로 내려가면 됩니다.
둘 다 방문한 경우에는, r 밑에 있는 노드들을 모두 방문했다고 표시하고, 위로 올라가면 됩니다. 즉, r 최초 방문 - 왼쪽 - r - 오른쪽 - r - 부모. 이런 식으로 올라가기 때문에, 많아봐야 한 노드는 3번 이상 방문하지 않습니다. 따라서 복잡도는 O(3n) = O(n)으로 표시할 수 있습니다.
set에서 next 연산은 최악의 경우에, O(logn)임은 자명합니다. 예를 들자면, 이런 경우가 있을 수 있어요.

예를 들어, 트리가 이런 식으로 있는 경우에, a는 최악의 경우 깊이가 log(n)에 비례합니다. a가 r의 왼쪽 subTree에서 제일 큰 수일 때, a의 다음 수는 r입니다. a가 정말 깊이 있다면, iter가 a를 가리키고 있고, 그 다음 원소를 찾는 연산인 next를 호출했을 때에는 로그, 대략 log(n) 정도가 걸릴 거에요.
그런데, begin부터 end까지 전수 탐색을 했을 때에는, O(nlogn)이 아닌, O(n)이 걸립니다. 이는 n개의 원소를 제일 작은 것 부터 제일 큰 것 까지 탐색했을 때, 총 3n번 visit를 하기 때문입니다. 그러면, 제일 작은 것을 찾는 데 걸리는 시간에 따라서, 복잡도가 결정이 될 건데요. 흔히 알려진 self balanced Tree에서는, 그것을 찾는데 O(logn)입니다. n이 커지면, n에 비해 logn은 극단적으로 작기 때문에, logn은 무시됩니다. 제가 분석한 방식을 총계 분석이라고 합니다. 그리고 이는 분할 상환 분석을 하는 방법 중 하나입니다.

'자료알고 > 자료구조' 카테고리의 다른 글
| 유니온 파인드 (union find) : 병합 연산과 루트를 찾는 연산만 있다. (2) | 2020.03.14 |
|---|---|
| 누적된 변환과 lazy propagation 알고리즘 (4) | 2020.02.29 |
| 균형 이진 트리 : 제약 조건이 맞지 않으면 추가적인 연산을 한다. (2) | 2020.01.11 |
| 비트 배열 : 공간을 1/8, 1/32, 1/64로 압축한다. (9) | 2019.12.24 |
| 스파스 테이블 (sparse table) : 2의 거듭제곱 단위로 점프한다. (4) | 2019.12.20 |


최근댓글