안녕하세요. 이번 시간에는 map의 merge 메소드에 대해서 간단하게 알아보겠습니다.
먼저 예제 프로그램을 하나 보겠습니다. 이 예제는 매우 간단한 프로그램인데요.
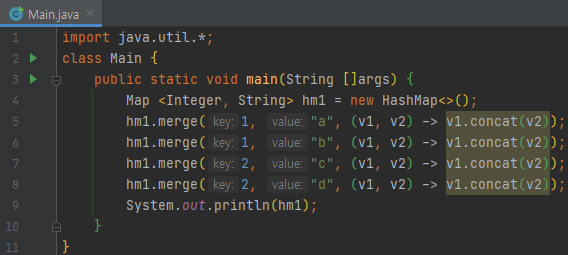
3번째 인자에 이상한 람다 식이 들어가 버립니다? 뭔지는 모르겠지만, 키에 대응되는 value 값에 concat를 시키는 모양입니다.

그러면 결과가 어떻게 나올까요? 키 값이 1인 것의 Value는 "ab", 키 값이 2인 것의 Value는 "cd"가 나오게 됩니다.

메서드 설명을 봅시다. key가 없는 경우라면 v값을 넣어버리고, 그렇지 않으면 remapping function에 의해서 나온 값으로 replace 한다고 되어 있어요. 이 메서드는 결정적으로 multiple value에 대해서 값을 combining 하기 위해 쓴다고 되어 있는데요. 위 예제에서는 키 값이 1인 것에 대해서 "ab"로 combining 되었고, 키 값이 2인 것에 대해서 "cd"로 combining이 된 셈입니다.
로직은 대충 알았으니, 어떻게 동작하는지 봅시다. 먼저, 저는 HashMap의 merge를 호출하였습니다.

그러니, HashMap의 merge 메소드가 수행되는데요. 흐름을 따라가 봅시다.

먼저 old가 보입니다. TreeNode로 Chaining이 된 경우에 뭔가 키 값을 찾을 거고, 찾은 키 값에 대해서 매치되는 value의 값이 있을 겁니다. 찾은 키 객체는 old가 되겠네요. Node는 Key와 Value로 이루어져 있는데요.

이 old 객체를 찾게 되면, 그 안에 있는 key 값과 value 값이 있을 겁니다. key가 있을 때, old.value는 key에 대응되는 값이 됩니다. 다음에 1754번째 줄에 remappingFunction.apply가 나왔는데요. 2개의 인자를 받습니다.

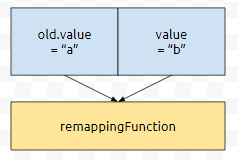
예를 들어 키 값이 1인 것의, 대응되는 value 값이 "a"라 하겠습니다.

이것은 old.value에 대응됩니다. 다음에 apply의 2번째 인자에 value가 넘어가는데요.

merge 내부를 보시면 1254번째에서 apply로 넘어가는 value와 merge 메서드로 넘어오는 value가 다르지 않음을 알 수 있어요.

그러면 제가 이런 식으로 merge를 호출하면 remappingFunction에는 어떻게 넘어갈까요? v1은 old.value였고, v2는 value였습니다. 그러니, 아래와 같이 그림이 그려질 겁니다.
이제 람다로 넘어간 (v1, v2) -> v1.concat(v2)를 봐야 하는데요. 일단 BimappingFunction 같은 경우, 인자로 2개가 넘어가고 결과값이 있는 형태에요. v1.concat(v2)가 결과값을 의미합니다.

이 부분을 보시면 알 수 있습니다. 우리는 (t1, t2) -> t1.concat(t2)를 정의함으로써, mapping Function을 정의했어요. 이 의미는 1번째 인자가 t1, 2번째 인자가 t2라면, t1 뒤에다가 t2를 concat 한 결과값을 리턴하라는 의미입니다.
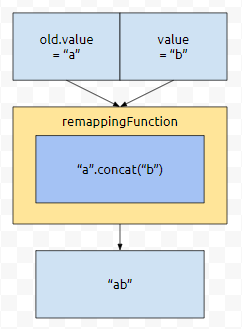
그림으로 그리면 요래 되겠군요. 이제 왜 예제 프로그램의 결과값이 키 값이 1인 value 값은 "ab", 키 값이 2인 value 값은 "cd"가 되는지 이해가 가실 듯 싶네요.
'레퍼런스 > 예제' 카테고리의 다른 글
| 파이썬 itertools starmap 함수 : 원소들에 대해 병렬적으로 변환을 적용한다. (0) | 2021.12.16 |
|---|---|
| java removeif : 조건에 만족하는 원소를 필터링 해서 제거한다. (0) | 2021.12.12 |
| 파이썬 json dumps loads 메서드를 간단하게 알아봅시다. (0) | 2021.11.15 |
| python requests 모듈 사용 방법을 간단하게 알아봅시다. (0) | 2021.11.11 |
| java string 내부에 있는 문자들을 hex value로 보는 방법을 알아봅시다. (0) | 2021.10.28 |


최근댓글