수 x가 추가되고 제거됩니다. k번째로 작은 수를 구해야 하는 쿼리가 있습니다. 아니면, 수 x가 있는지 찾아야 합니다. 어떻게 해야 할까요? 물론, offline이 가능하면 정렬하고 좌표 압축한 다음에 세그먼트 트리를 돌릴 수 있어요. 하지만, online으로 해결해야 하는 경우, 정렬 후 좌표압축 스킬이 통하지 않습니다.
이 때, 우리는 수 x를 32bit 범위 내라면 32, 64bit 범위 내라면 길이 64의 2진수 문자열로 변환할 수 있습니다. 이 때, 우리는 Trie라는 자료구조를 생각할 수 있습니다. 이 Trie는 올해 카카오 4번에 나왔던 structure 이기도 합니다. Skip List는 상대적으로 구현하기 까다로우니, 논외로 합시다.
예를 들어서, 13을 넣는다고 생각해 봅시다.
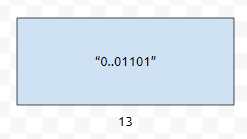
그러면, 이것은 문자열로, "0...01101"로 표현할 수 있습니다. 이 때, 문자열에 나타날 수 있는 문자 집합은 {'0', '1'}, 이 둘 뿐입니다. 편의상 0과 1이라고 합시다. 그러면, 32bit 내에 있는 수에 대한 쿼리가 Q개 들어왔을 때, 노드는 32Q개만큼 할당하면 되고, 64bit 내에 있는 수에 대한 쿼리가 Q개 들어왔다면 64Q만큼의 공간을 할당하면 됩니다. 그러면, node 1개당 크기를 b byte라고 하면, 32bit 내에 있는 수들만 들어왔을 때에는 32bQ, 64bit면 64bQ가 됩니다. 노드 당 byte인 b가 12여도, Q가 10만인 경우 76M, int 내에 들어오는 경우에는 38M가 나옵니다. 이 부분은 고려를 잘 하실 필요가 있습니다.

수 x가 추가되고 제거되면서 k번째 수를 구해야 하는 쿼리가 들어오는 자료구조를 구현하기 위해 Trie를 생각해 보았다고 하였습니다. 그러면 노드가 중요할 텐데요. go[2]는 각각 어느 노드로 가야 하는지를 가리킵니다. 상태가 0인 경우 go[0]로 가면 될 것이고, 1인 경우 go[1]로 가면 될 거에요.
그런데, 이거 pointer로 선언해야 하지 않나요? 라고 물어보실 수 있어요. 우리는 trie에 매겨져 있는 특정한 노드 번호만 알고 있어도 됩니다. 그러면 해당 공간에 접근이 가능합니다. 굳이 주솟값으로 타고 들어갈 수 있는 건 아니에요. 예를 들자면 배열 arr이 있는데요. 3번째 원소에 접근하기 위해서 *(arr+i) 이렇게 접근하기도 하지만, 그냥 i번째에 접근하겠다. 해서 arr[i] 이렇게 하기도 하지 않나요? 기준 위치로부터 몇 번째에 있는 것이냐만 저장해도 된다는 것을 알 수 있어요.
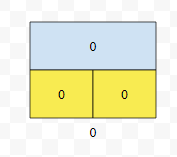
먼저 0번 노드는 Root입니다. 아직 추가된 노드는 없는 상태입니다. 따라서 cur_node의 값은 0입니다. main 함수의 cur_node는 노드가 추가될 때 마다 하나씩 증가를 할 거에요.
먼저, k번째로 큰 수 연산이 동적으로 지원이 되기 위해서는 "10xxxx" 가 몇 개, "1xxxxx"가 몇 개 있는지를 알려줘야 합니다. 그러면, 트라이의 value에 이 값을 저장해야 합니다. "10"이 추가되는 상황인 경우를 생각해 봅시다.

Root인 0부터 시작합니다. 그리고 "10"을 추가해야 하므로, 0.go[1]의 값이 0인지 봅니다. 0인가요? 따라서, 새롭게 노드를 추가합니다. 추가된 노드는 1입니다.

이 때 "1x"꼴 데이터 또한 하나가 증가했다는 사실을 주목해 봅시다. 다음에 현재 탐색하고 있는 노드의 위치는 0번이 아닌 1번이 됩니다. "10"의 2번째 문자는 0이므로, 1.go[0]이 0인지 봅시다. 0인가요? 이 경우, "10"꼴 데이터가 없다는 겁니다.

따라서 2번 노드를 추가합니다. "10"을 추가하는 과정에서 탐색한 노드들은 0, 1, 2입니다. 따라서, 이들의 val 값을 하나 증가시킵니다. 그러면 아래와 같이 될 거에요.

이는 탐색 과정에서 해도 됩니다. for loop 안에서 하는 게 조금 더 편한 듯 싶어요. 다음에 "11" 패턴을 추가해 봅시다.

역시 root에서부터 출발을 할 건데요. 이 때, 0.go[1]은 1로 가라고 되어 있으므로, 1로 갑니다. 다음에 나오는 문자는 1인데요. 1.go[1]이 있나요? 없습니다. 따라서 3번 노드를 추가하고, 1.go[1]은 3이 됩니다.
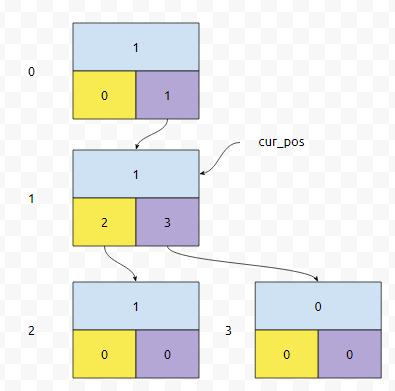
따라서, 이렇게 연결하면 됩니다. "11"을 추가하는 과정에서 탐색한 노드는 0, 1, 3이므로, 이 노드들의 val 값을 1씩 증가시킵니다. 그러면, 이들의 val 값은 2, 2, 1이 됩니다.
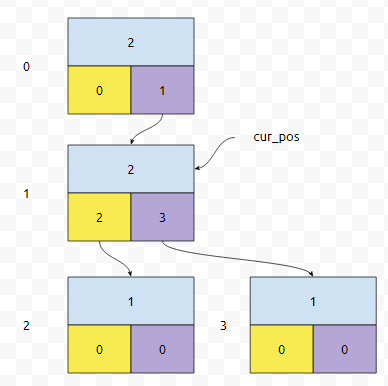
그러면 이렇게 추가하면 될 겁니다. 이건 1개가 추가될 때이므로 변화량이 1인 경우입니다. 1개 삭제가 되는 경우, 변화량은 -1, 10개 추가되는 경우 dx는 10이 됩니다. 그렇다면 add, delete 등을 따로 구현하지 않아도, 그냥 dx에 따라서 Trie에 값이 update 되게만 만들면 add랑 delete 정도는 쉽게 커버할 수 있음을 알 수 있어요.
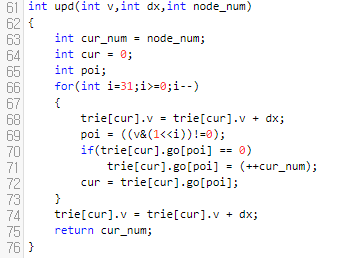
제가 했던 설명을 모두 적용한 upd 함수는 위와 같습니다. node_num을 주목해서 볼 필요가 있는데, node_num은 현재, 할당된 노드의 갯수를 받습니다. 그리고 이것을 cur_num이 받고 있다는 것을 알 수 있는데요. cur_num은 70번째 if문이 걸릴 때 마다 증가하고 있어요.
그러면, cur_num은, 연산을 모두 적용했을 때, 추가된 총 노드 갯수이다. 정도로 유추를 해 볼 수 있어요. cur_num을 리턴하게 되면, 연산을 모두 적용했을 때, 추가된 노드의 총 갯수를 돌려주는 셈이 될 거에요. 그러면 삭제가 되어 있는데 데이터에 남겨진 경우 문제가 될 수 있지 않느냐고 생각하실 수 있어요. "10"을 삭제했다고 해 봅시다. 그러면 0, 1, 2번 노드의 val 값은 하나씩 감소합니다.

위 그림과 같은 상황입니다. 이 때, "10"에 접근한다면, 접근은 가능해요. 2번 노드로. 그런데, val 값이 0입니다. 따라서, "10"은 없다. 정도로 보시면 됩니다. 물론 중간에 찾지 못하는 경우도 not found 입니다.
찾기 연산은 어렵지 않으니, k 번째 요소를 구해라. 라는 쿼리를 생각해 봅시다. 당연하게도 k>0.val인 경우, 즉, 자료구조에 있는 수의 갯수보다, k가 더 큰 경우에는 없다고 보시면 됩니다. 그 예외처리는 잘 하시면 좋고요. 저는 2가지의 변수를 정의할 겁니다. 목표, 그리고 현재 검사하고 있는 패턴, 예를 들어, "111xxxx"를 검사한다면, 이 패턴들의 집합보다 확실히 작은 것들의 갯수를 cur_th로 정의할 겁니다.
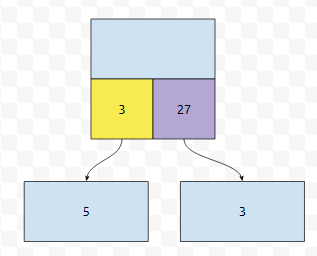
현재 노드가 1, 1, 0, 1을 거쳐서 왔다고 생각해 봅시다. 그러면, 1101xxxx인 상태인데, 여기서 11010xxx로 가야 하는지, 11011xxx로 가야 하는지가 문제입니다. 그렇다면, 1101xxxx보다 무조건 작은 수의 갯수를 cur_th라고 합시다. 그러면, 11011xxx로 가려면, 최소한, 임의의 11010xxx보다는 커야 합니다. 이 11010xxx의 갯수는, 현재 노드에서 go[0]으로 갔을 때 val의 값이 됩니다.

예를 들어 cur_th가 3이고, k가 8이라고 해 봅시다. cur_th에 노란색으로 칠한 수의 합은 8입니다. 이것이 k보다 작거나 같아요. 따라서, 이 경우, go[0]으로 가야 합니다. 그렇지 않다면 어떻게 해야 할까요? 예를 들어 cur_th가 3이고 k가 9인 경우에는? 이 때에는 왼쪽으로 가 봤자 5개밖에 없기 때문에, 오른쪽으로 가야 합니다.
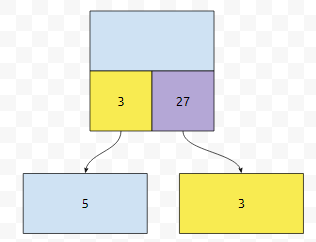
즉, 현재 노드에서 go[0], 그러니까 <현재상태>0xxxx 꼴인 갯수를 구한 다음에, 그걸 토대로 조건 판단을 해야 함을 알 수 있어요. 제가 설명한 내용을 코드로 봅시다.

먼저 cur_th는 건너뛴 수들의 갯수, 그러니까 어떠한 패턴보다 확실히 작은 수들의 갯수입니다. 예를 들어 1xxxxx에 있다면, 0xxxxx의 수들의 갯수가 cur_th가 될 거에요. for loop를 돌 때 마다, rr 이라는 것을 계산을 하고 있음을 알 수 있는데요. 여기서 foo(cur)는, cur번 노드에서 go[0]으로 갔을 때 있는 노드에 있는 val입니다. 즉, <어떠한 상태> 0xxxx 꼴의 수의 갯수입니다. 이 rr의 값보다 x가 더 작다면, 왼쪽에 수가 있는 겁니다. 그렇지 않다면, 오른쪽으로 가야 될 거에요.
그런데, 오른쪽으로 갈 때 조심해야 할 점이 있어요. cur_th가 rr이 되어야 한다는 것입니다.
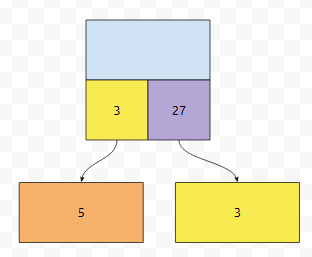
위 예제에서, rr의 값은 cur_th + 5인데요. 우측으로 가는 경우, 5개의 수는 건너 뛴 것이라고 보아도 되기 때문입니다.

이제, foo 함수를 봅시다. 이것은 현재 노드에서 go[0]으로 갔을 때 val의 값을 리턴해 주는 것인데요. 이 trie[node_num].go[0]의 값이 0이라면, go[0]과 연결된 노드가 없는 것입니다. 따라서 0을 출력합니다. 그렇지 않다면, go[0]으로 이동해서, 거기에 저장이 되어 있는 value 값을 리턴해 주면 될 거에요.
그러면 찾기 연산은 어떻게 해야 할까요? 아래 그림에서 "01"을 찾는다고 해 봅시다. Root의 번호는 0이니까 0번부터 출발합니다.
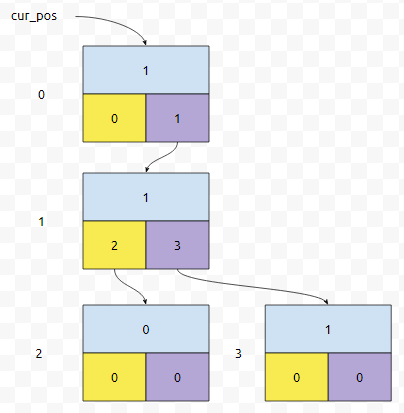
"01"에서 첫 번째 '0'을 봅시다. 현재 위치는 0번이니까, 0번의 go[0]을 봐야 할 건데, 이 값이 0입니다. 더 이상 탐색할 수 없습니다. 따라서, 이 경우 없습니다. 2진수 문자열을 기준으로 탐색하는데, 가야 할 번호가 0번이다. 그러면 없다고 하시면 됩니다. 실제로 데이터는 있지만 val 값이 0인 경우에도 존재하지 않는 것입니다. 삽입, 삭제가 일어나는 상황에서 k번째 수를 구하기 위해서, Offline 쿼리를 쓴다면 정렬하고 좌표압축 한 다음에 세그 트리를 쓸 수 있었어요. Online으로 처리해야 하는 경우 문제가 될 수 있는데요. Q랑 써야 하는 비트수 b의 곱인 bQ의 값이 커버할 만 하다면, 충분히 쓸 만 하다는 것을 알 수 있어요. 예를 들어, Q가 10만이고, b = 32라면 bQ의 값이 320만이니 충분히 고려해 볼 만합니다.
'자료알고 > 자료구조' 카테고리의 다른 글
| 스파스 테이블 (sparse table) : 2의 거듭제곱 단위로 점프한다. (4) | 2019.12.20 |
|---|---|
| 우선순위 큐 : 부모가 자식들보다 rank가 높다. (0) | 2019.12.16 |
| 프로그래머스 크게 만들기 : 쿼리 특징을 잡아봅시다. (4) | 2019.11.27 |
| 완전이진트리 vs 포화이진트리 : 이 둘에 대해 알아봅시다. (7) | 2019.11.09 |
| 전치 행렬 (Transpose matrix) : 왜 중요한가? (2) | 2019.10.13 |


최근댓글