large database를 import 해 보면서, 어떤 식으로 mysql에 dump 파일을 db에 반영하는지 알아보겠습니다.
문제의 데이터 베이스는, 깃헙의 이 저장소에 들어 있습니다. test_db라고 다운을 받아보시면, dump 파일들이 있고, sql 파일이 있는데요. 이 중에, employees.sql을 열어보면 코드가 좀 길다는 것을 알 수 있습니다. 그런데, 이것을 해석해 보면 크게 2 부분으로 나눌 수 있습니다.
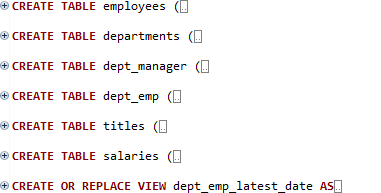
테이블과 view를 create 하는 문장이 있습니다. 이 중에서, create or replace view는 뷰를 없으면 생성하고, 있으면 대체합니다. 그런데, table은 생성하는 것만 있는데요. 해당 쿼리문 위에 drop table이 있습니다.

이것은 테이블이 존재하면 삭제하는 문장입니다. 이해하기는 어렵지 않아 보입니다.

그리고 dump 파일들을 가지고 무언가를 하는 부분입니다. 여기에 테이블에 레코드들을 추가하는 것들이 들어가 있을 겁니다.
데이터 베이스에 테이블들을 추가했습니다. 그 다음에는 테이블에 데이터를 밀어넣으면 됩니다. 이 작업을 할 겁니다.
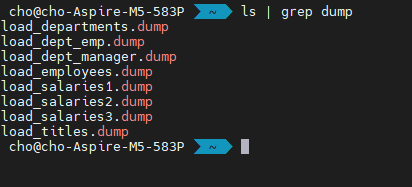
제 서버에는 dump 파일이 8개 있습니다. 이들도 각각 해당 레포에서 다운받을 수 있습니다.
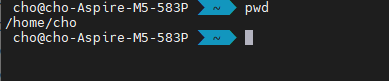
해당 덤프 파일들의 위치입니다.
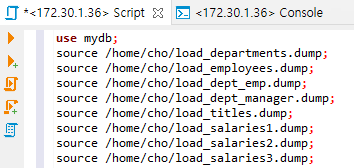
제 mysql 서버는 우분투를 쓰고 있으니, 이런 식으로 작성하시면 되는데요. 공식 문서에 보시면, 이 명령어는 mysql이 떠 있을 때, mysql 커멘드 창에서, sql 스크립트 파일을 실행하기 위해서 쓸 수 있다고 합니다. 그렇다면, source 명령어 뒤에 dump 파일의 절대 경로만 붙이면 될 듯 싶네요.
그런데, dump 파일들을 실행하는 소스 명령어를 일일히 다 치기가 귀찮습니다. 그러니, 이것을 하나로 묶을 수 있습니다.
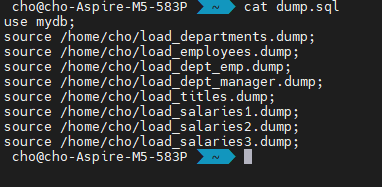
dump.sql에 적어놓았습니다. 단지, 이 파일의 목적은, load_department.dump, load_employess.dump, ... 순서대로 덤프 파일을 읽어들여서 쿼리문을 수행하게끔 하는 것입니다. 처음에 use mydb; 가 들어가 있는데요.
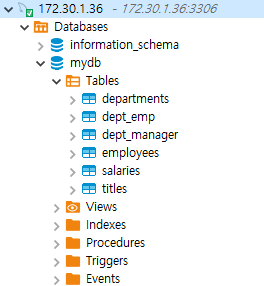
이는 제가 mydb라는 데이터 베이스에 있는 테이블에 레코드를 넣기 위해서입니다. 해당 데이터 베이스에는 titles, salaries, ... 테이블이 당연히 있어야 합니다. 이 테이블들만 추가하는 방법은, employees.sql에 있는 create table 쿼리를 수행하면 됩니다. 보통, 저는, 이런 걸 넣을 때에는 테이블 생성하는 것, 데이터를 밀어넣는 것을 따로 분리를 합니다. 헷갈리지 않게 하기 위함입니다.
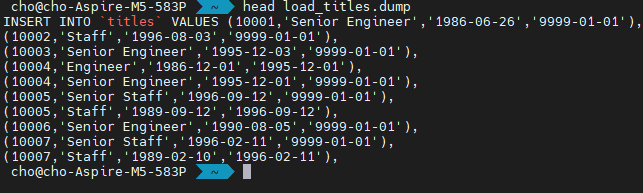
dump 파일을 봅시다. 너무 크기 때문에, head 명령어로 위에 10줄만 보겠습니다. insert 문이 있음을 알 수 있습니다. 그러면, 디비에 접속해서 덤프 파일을 넣으면 되겠네요.
cho 유저로 접속하였습니다. 이 유저는 mydb 데이터베이스에 대해서 모든 권한이 있는 상태입니다.
접속을 하셨다면, 아까 작성한 dump.sql을 실행하도록 하겠습니다.
source dump.sql을 쳤는데요. 이것은 제가 작업하고 있었던 공간이 /home/cho였기 때문에 가능했던 걸로 보입니다. 소스 뒤에 /home/cho/dump.sql을 치면, home 디렉토리에 있는 cho 디렉토리에 있는 dump.sql에 있는 쿼리문을 실행합니다.
'코딩 > Sql' 카테고리의 다른 글
| postgresql du를 이용해서 유저 확인을 해 봅시다. (0) | 2021.06.26 |
|---|---|
| mysql date_add date_sub 함수 : 날짜로부터 기간을 더하거나 뺀다. (0) | 2021.05.26 |
| mysql 외부 접속 가능하게 설정해 봅시다. (0) | 2021.02.08 |
| sql limit offset : 데이터가 크지 않다면 페이징 처리를 쉽게 할 수 있다. (0) | 2021.01.22 |
| mysql nullif 함수 : 조건을 만족할 때 null을 리턴한다. (0) | 2020.12.21 |


최근댓글