안녕하세요. 백준 chogahui05입니다. 'A'를 ascii로 표현한다면 1byte로 표현이 됩니다. 그런데, '가'와 같은 것들은 ascii로 표현하지 못합니다. java에서 문자 인코딩 시간에 이야기를 조금 했었습니다. utf-8 인코딩 형식에서는 3byte로 표현이 된다고. utf-16은? 2byte였어요. 실제로, mysql에서 length는 문자열의 byte 크기를 리턴해 주는데요. 예제를 보면서 이해해 보도록 하겠습니다.
먼저 table 2개를 생성하겠습니다. 각각 utf8_table과 utf16_table입니다.

utf8mb4는 아래 글에서 충분히 설명을 드렸습니다.
[관련글]
이모티콘을 넣을 수 있었던 것이 utf8mb4, 그렇지 않았던 것이 utf8이였습니다. 채팅 서버에서 이모티콘을 쓰는 경우가 상당히 많다는 것을 고려를 할 필요가 있어요. 그것 빼고는 utf8 규격과 같다고 보시면 됩니다. 한글 하나는 3byte이고, 영어는 1byte라고 생각하시면 되겠습니다.

utf16_table의 character set은 utf16입니다. 2byte로 표현이 될 수 없는 영역은 서러게이트 영역 2 2개로 표현이 되는데요. 한글과 영어는 그렇지 않습니다. 따라서, 2byte로 표현이 됩니다.

다음에, 두 테이블에 똑같이 '조가희' 라는 데이터를 넣었습니다. 이제, mysql length 함수를 이해해 보도록 하겠습니다.
target이 되는 문자열 하나만 넘겨주면, 그 문자열이 차지하는 바이트 수를 리턴하는 함수가 length입니다.
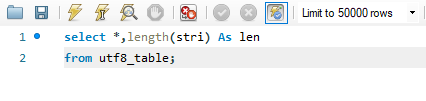
stri가 varchar(30)을 담고 있는 필드였습니다. 저는 '조가희' 라는 데이터만 넣었는데요. 실행 결과가 어떻게 나올까요?
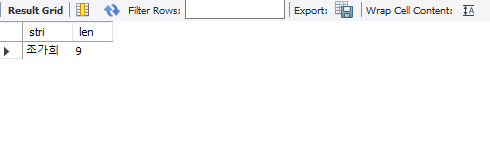
9가 나옵니다. character set이 UTF8MB4였습니다. UTF8의 속성을 그대로 따라간다고 했어요. 그러면 한글은 3byte로 표현이 될 거에요. 한글 3글자면, 3x3 = 9바이트입니다. 구구단 외우는 거 같군요.

그러면 utf16_table에서는 어떨까요? 역시 같은 데이터가 저장이 되어 있는데요.

캐릭터 셋이 utf16으로 다릅니다. 이것은, 한글이던 영어던 2byte로 표현이 됩니다. 한 글자당, 총 3글자가 있었나요? 따라서, 2x3 = 6. 6이 리턴이 됩니다. 결론은 캐릭터 셋에 따라서, 같은 데이터라도 length의 결과 값이 달라질 수 있다는 것이에요. 보통 utf8로 많이 처리하시니, 한글은 1글자당 3byte라고 봐도 무난할 듯 싶긴 하지만.. 이러한 특성은 잘 알아두시는 게 좋겠습니다.
또 다른 예제를 봅시다.
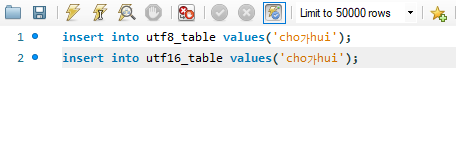
이번에는 'cho가hui'라는 것을 추가했습니다. 영어 6개, 한글 1개입니다. 그러면 캐릭터 셋이 utf8mb4일 때에는 결과값이 어떻게 나올까요? 이번에는 조금 복잡한 산술 계산이 들어갑니다.

한글 1개입니다. 개당 3byte인가요? 그리고 영어 6개인데, 1개당 1byte에요. 그러면 3x1 + 6 = 9입니다.

그런데 utf-16이 캐릭터셋인 경우에는 어떤가요? 영어나 한글이나, 유니코드로 치면 0xFFFF 범위 내에 있나요? 따라서, 한 개당 2byte가 되고, 글자수가 7개니까, 구구단을 외우면 되겠습니다. 2x7 = 14가 됩니다.
'코딩 > Sql' 카테고리의 다른 글
| mysql left join : 왼쪽 릴레이션을 보존한다. (8) | 2019.11.03 |
|---|---|
| mysql char_length 함수 : 문자열의 글자 수를 돌려준다. (7) | 2019.10.21 |
| mysql left, right, mid 함수 : 부분 문자열을 추출한다. (2) | 2019.10.08 |
| mysql auto_increment 값 얻어오기 : 어떻게 얻어올까요? (9) | 2019.10.06 |
| mysql unix timestamp 함수 : 기준 시간으로부터 몇 초나 흘렀을까? (4) | 2019.09.20 |


최근댓글