numpy에서 indexing 연산은 생각보다 많이 써먹곤 했습니다. 그런데 numpy의 indexing에 걸리는 오버헤드가 어마어마하다는 것을 최근에야 알게 되었습니다. 상세 분석에서 분석할 기회가 있을 듯 싶습니다만 언제 할 지는 모르겠습니다. 여기에서는 간단하게 문제 상황을 정의하고, 어떻게 개선해야 하는지만 주로 잡도록 하겠습니다.
먼저 문제 상황을 정의해 보겠습니다. 간단한 점화식이 있습니다.

이 때, dp[19999]를 구하는 게 제 목적입니다. 누적합을 이용해서 매우 쉽게 풀 수 있지만, 저는 dp[n]을 구하기 위해 dp의 0번째 인덱스에 있는 값부터 n-1번째 인덱스에 있는 값까지 모두 접근을 한 다음에, 이들의 합을 계산해서, mod로 나눈 나머지를 취할 겁니다. 그리고, 이 값을 다시 dp[n]에 넣을 겁니다.

안쪽 for loop는 i번 루프가 돌고 있음을 알 수 있어요. 바깥쪽 루프에 의해서, 안쪽 루프는 1 + ... + i번 돌 테니, i^2에 비례하는 횟수만큼 31 ~ 32번째 줄이 수행됩니다.
문제는, 이 Integer도 객체인 만큼, loop를 돌 때 마다 계속 새로운 객체가 생성이 된다는 것입니다. 시간 복잡도는 n^2이겠지만, 실제 수행 속도는 굉장히 느립니다.

새로운 객체를 생성하는 비용도 크고, 접근하는 비용 또한 클 수 밖에 없습니다. 객체를 몇 개나 만드는지는 잘 모르겠습니다. 그런데, 31번째 줄을 수행하기 전에 dp[i]의 id값을 출력하고, 31번째 줄을 수행한 후에 dp[i]의 id 값을 출력하면, id 값이 달라짐을 알 수 있습니다.

이를 통해 추정해 볼 수 있는 것은 + 연산이 일어날 때, 객체가 새로 만들어 진다던지, 혹은 특정 위치에 있는 객체가 업데이트 된다는 것 정도만 추정해 볼 수 있습니다. 2억번 가량 접근하는 데 29초가 걸린 걸 보면 상당히 느리네요.
그러면 아래 함수는 어떨까요? numpy structure를 찾아보면 이런 그림을 많이 볼 수 있어요. 이 문서를 보면 명확할까요?

python의 List와 npArray를 비교해 놓았는데요. 후자는 메모리 상에 연속적으로 이어진 무언가를 가리킨다고 되어 있습니다. 그래서, 행렬 연산에 특화 되어 있다고 알려져 있기는 해요. 문제는 이런 경우입니다.

보면, 안쪽 for loop에서 dp[i]와 dp[j]에 접근합니다. 접근 하는 것 까진 좋은데, 더하기 연산까지 해 버립니다.

20번째 줄을 수행하기 전에 dp[i]의 id값을 출력하고, 20번째 줄을 수행한 후에 dp[i]의 id 값을 출력하게 하였습니다. 보니까, before하고 after에 찍힌 id 값이 다르네요. 주소가 다른 객체에 접근하였다는 의미입니다.

실행 결과를 보면 113.18초가 나왔음을 알 수 있는데요. 이를 통해 알 수 있는 점은 list의 indexing 보다 numpy의 indexing이 훨씬 무겁다는 점입니다.
그러면 어떻게 해야 할까요? 사실 numpy는 indexing보다는 행렬을 통으로 연산하는 것을 잘 합니다. 해결책은 간단합니다. 원소 하나 하나 개별로 하지 말고 통으로 연산을 하게 하면 됩니다. 하나 하나씩 indexing 해서 처리하지 말고요.

통으로 연산을 해야 할 부분은 주황색으로 칠한 부분입니다. 그리고 주황색으로 칠한 부분은 slicing으로 가져올 수 있는데요. dp[0:n]은 0번째 원소부터 n-1번째 원소까지 가져온다는 의미입니다.

다음에 1차원 배열에서 np.sum을 할 수 있습니다. axis를 주면, elements들의 합을 구합니다. 1차원 배열을 더하는 것이니 dp[0:n]을 np.sum의 인자로 넘기면 됩니다. 아래와 같이 구현할 수 있습니다.

이제 이 함수의 실행 시간을 측정해 봅시다.
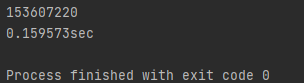
0.15초. 상당히 빠릅니다. numpy를 왜 쓰는지, 언제 제대로 된 퍼포먼스를 내는 지 아는 것이 중요함을 다시 한 번 느끼게 되었습니다.
'중급 레퍼런스 > numpy' 카테고리의 다른 글
| numpy append 메서드 : matrix 뒤에 덧붙인다. (0) | 2021.08.26 |
|---|---|
| numpy reshape 메서드로 행렬 모양을 바꿔 봅시다. (0) | 2021.08.06 |
| list를 numpy array로 바꾸고 numpy array를 list로 바꾸는 방법을 알아봅시다. (0) | 2021.05.19 |


최근댓글