제 토이 프로젝트는 postgresql 12.9를 사용하고 있어요. 특정 api를 호출했을 때 쿼리가 실행이 될 텐데요. 쿼리가 실행될 때 어떤 lock이 걸리는지 간단하게 보기로 하였습니다. 데드락이 생길 수 있을까? 라는 의문이 들었기 때문입니다. 만약에 생긴다면 적당한 방법으로 회피를 해야 하기도 하고요. 그러면 어떤 식으로 lock이 걸리는 지 알아야 할 겁니다.
데이터가 그리 크지 않아서, 쿼리 수행이 매우 순식간에 끝나게 됩니다. 그래서, 쿼리가 실행되는 도중에 잠깐 sleep을 시켜야 됩니다. 이를 위해서 pg_sleep 함수를 이용하였습니다.

사용법은 간단합니다. 안에 몇 초 동안 sleep를 시킬 건지 넣기만 하면 됩니다.
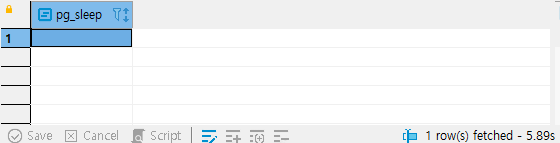
1 row(s) fetched가 있는데요. 옆에 5.89초가 있습니다. 대략 5초 정도 쿼리가 sleep 되었다고 봐도 될 듯 해요. 더 오래 sleep를 시키려면 당연하게도 pg_sleep에 들어가는 수를 더 늘려버리면 됩니다.
제 토이프로젝트의 mapper xml 파일 안에는 여러 쿼리들이 있습니다. 이 중에 하나만 뽑아서 보도록 합시다.

이 쿼리는 책을 빌릴 때 수행되는 쿼리입니다. 도서관에서 책을 빌리려고 하는 api가 수행되어서 postgresql에 쿼리가 넘겨졌을 때, 어떤 LOCK이 걸려버리는지 체크해 보겠습니다. pg_sleep에는 적당히 큰 수인 50을 넣겠습니다. 그런데, 이 pg_sleep을 어디에 넣어야 할 지 문제인데요. 앞에 explain을 넣으면, 쿼리가 어떻게 실행되는지 Query plan을 보여줍니다.

앞에 exlpain을 넣어보았습니다.

그러면 user에서 Seq scan을 돌리고, 다음에 book에서 찾은 결과를 가지고 또 filter를 걸어버림을 알 수 있어요. 저는, 이 exists 안에 있는 서브쿼리가 실행될 때, sleep을 걸어버리려고 합니다. 그런데 이상하게도, select 부분에서 pg_sleep을 써 버리면 쿼리가 delay가 되지 않았습니다.
이미 record가 존재하거나, 그렇지 않은데 굳이 pg_sleep의 결과를 쓸 이유가 없어서 최적화를 한 것이 아닐까 싶기도 합니다.

대신에 from 절에 pg_sleep(50)을 걸어버렸습니다.

Query plan을 보면, Function Scan on pg_sleep이 보이네요.
어떤 락이 걸려 있는지는 postgres의 상태일 것이니, pg_catalog에서 적당한 테이블들을 찾아야 합니다.

보니까 pg_locks가 있습니다.
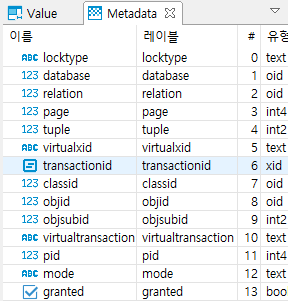
필드들을 봅시다. 뭔가 중요한 것들이 있어 보이는데요. 저는 이 중에서 locktype, relation, pid, mode 정도만 뽑겠습니다.

다음에 pg_stat_user_tables에는 relid가 있는데요. 이것은 릴레이션 id를 의미합니다. pg_stat_user_tables와 pg_locks를 join하면 되겠네요.

카티션 곱한 결과에서 relid와 relation이 같은 필드만 뽑아 보겠습니다.

그러면, 결과가 요래 나오는데요. 테이블 user와 book에 대해서는 S-lock이, borrow에 대해서는 Row X-lock이 걸렸음을 알 수 있어요.
'코딩 > Sql' 카테고리의 다른 글
| dbeaver erd diagram 을 손쉽게 생성하는 방법을 알아봅시다. (0) | 2022.05.26 |
|---|---|
| 집계된 결과를 concat 하는 mysql group_concat 함수를 알아봅시다. (0) | 2021.12.14 |
| 계층형 쿼리에 쓰일 법한 with recursive 절에 대해 알아봅시다. (0) | 2021.12.02 |
| mysql with 절 : 임시 결과를 정의하는 with 절을 알아봅시다. (2) | 2021.11.20 |
| mysql substring_index 함수를 이용해서 tokenize를 해 봅시다. (0) | 2021.09.30 |


최근댓글