문제 출제 작업을 할 때, 데이터를 random하게 생성하는 것은 매우 중요한 일 중 하나입니다. 제가 출제한 코딩테스트 문제들은 생각보다 제약 조건이 단순하지 않아서 choices에 weights 인자를 넣어서 생성할 일은 거의 없었습니다. 그런데, 나중에 출제를 할 때 알아두면 좋을 듯 해서 정리하게 되었습니다.
옛날에 문제를 출제했을 때, A, B, C 쿼리가 일정 비율로 나오게끔 generate하는 코드도 꽤 제작했던 걸 보면, 안 필요할 거 같지는 않기 때문입니다.

list에 count는 리스트 내에서 value가 출현한 횟수를 세어줍니다. 예제에서는 이 함수를 많이 쓰니, 미리 언급하고 넘어가겠습니다.

기본적으로, choices는 복원 추출을 하게 됩니다. 같은 원소를 여러 번 뽑는 것이 가능합니다. 예를 들어, 'ADD', 'DELETE'가 들어있는 상자에서 100번 복원 추출을 한다고 하겠습니다.

그러면, 'ADD'와 'DELETE'가 2번 이상 나오게 됩니다. 이 경우는 50 : 50으로 나왔네요. 기본적으로 weights나 cum_weights에 아무런 인자도 주지 않으면 같은 확률로 'ADD', 'DELETE'를 뽑게 됩니다. 만약에 'ADD'와 'DELETE'만 있는 상황에서 비복원 추출로 100번 뽑으면 어떻게 될까요?

이 코드는 'ADD'와 'SUM'이 있는 상자에서 100번 비복원 추출을 하는 예입니다.

결과는 아시다시피 예외가 떨어집니다. 왜냐하면, 상자에 있는 아이템 갯수보다 많이 뽑아버렸기 때문입니다. sample과 choices의 차이는 이 글에서도 언급을 한 듯 하니 보시면 좋겠습니다.
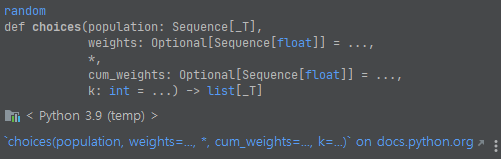
그런데, choices를 보면, weights와 cum_weights가 있음을 볼 수 있습니다. weights가 가중치이니까, 뽑을 때의 상대적인 가중치와 관련이 있어 보이는데요.

'ADD'와 'DELETE'가 있었습니다. weights를 각각 10, 90으로 두었는데요. 이는 ADD가 뽑힐 확률이 10이라면, DELETE가 뽑힐 확률은 90이라는 의미입니다. 즉, 'ADD'와 'DELETE'가 약 10:90의 비율로 뽑힌다는 의미입니다. 쉽게 풀어 설명하면 그렇습니다. 결과를 보겠습니다.

'ADD'는 7번, 'DELETE'는 93번 뽑혔습니다.

cum_weigths는 누적 가중치를 의미합니다. [10, 100]을 넣었는데요. 'ADD'가 10번 뽑히면, 'ADD'와 'DELETE'가 100번 뽑힌다는 의미입니다. 즉, 이 말은 'DELETE'가 90번 뽑힌다는 의미와 동치임을 알 수 있습니다. 문서에서도 비슷한 설명이 있습니다. 읽어보면, cum_weigths는 누적 가중치 정도로 생각하면 좋아요.
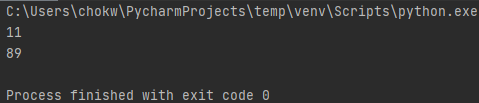
'ADD'가 11번 나오고 'DELETE'가 89번 나왔음을 볼 수 있습니다. 대략 10:90 정도 비율이라고 생각해도 좋겠습니다.
'레퍼런스 > 예제' 카테고리의 다른 글
| java map set에 특정한 원소들이 모두 있는지 containsAll 메소드로 확인해 봅시다. (0) | 2022.04.03 |
|---|---|
| python list count 함수를 이용해서 리스트 내 원소의 빈도수를 세어 봅시다. (0) | 2022.03.29 |
| c++ list insert 함수 사용법을 알아봅시다. (0) | 2022.03.21 |
| c++ list erase 함수 사용법을 간단하게 알아봅시다. (0) | 2022.03.15 |
| 파이썬 decimal : 고정 소수점을 쓸 때 이용해 봅시다. (0) | 2022.02.11 |


최근댓글