오늘은 read commit와 repeatable read 격리에 대해서 간단하게 알아보겠습니다.

세션 1에서 다음 쿼리들을 수행할 겁니다. Query1, Query2, Query3을 수행합니다.

다음에 세션 2에서 쿼리 4만 수행합니다. 중요한 것은 Query1과 Query2 사이에 Query4를 수행합니다.

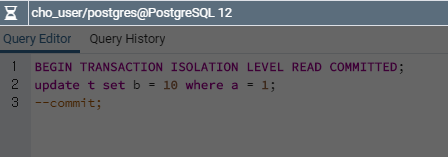
처음에 테이블 t에 들어있는 데이터는 다음과 같습니다. Session 1이 query1까지 수행하고, Session 2가 update를 수행하고 커밋을 했을 때, 다시 t에 있는 내용들을 출력해 보겠습니다.

어? 똑같군요. 이제 세션 1의 t1을 commit를 한 다음에 다시 t에 있는 데이터들을 모두 출력해 보겠습니다.

그제서야 a가 1인 레코드의 b의 값이 10으로 업데이트가 됩니다.

즉, 우리는 스케쥴을 다음과 같이 set 했을 때, 세션 1이 Query2을 수행하고 commit이 된 후에야, 결과값에 반영이 됩니다. 여기서 알 수 있는 사실은, 어떠한 트랜잭션이 시작되고, select 연산을 해서 값이 두 번 읽어지는 동안, 다른 트랜잭션이 값을 업데이트 하였습니다. 이 때 읽어들여진 데이터 값이 바뀌지 않았다는 것입니다.
Thread 를 할 때 우리는 이런 것을 배웠습니다. 두 쓰레드가 동시에 shared data에 write를 하면 문제가 생길 수 있다. 그렇기 때문에 적절한 lock을 걸지 않으면 문제가 생길 수 있다.

다음 스케쥴을 생각해 보겠습니다. Session 1이 a가 1인 레코드를 업데이트 하는 동안에, Session2도 a가 1인 레코드를 업데이트를 하고 있습니다. 어떻게 될까요?
일단 세션 1에서 Query1까지 수행하였습니다.

이 상태에서 T2가 update문을 수행하는 경우, waiting을 하게 됩니다. 무언가에 의해서 lock이 걸렸다는 것을 암시합니다.
다음에 Session 1에서 commit을 해 봅시다. 그리고 Session 2의 Message를 보면 아래와 같은 메세지가 있습니다.

동시 업데이트 때문에 순차적인 access가 불가능하다. error가 발생했기 때문에, s2의 Transaction은 롤백이 되어야 합니다. 당연하게도, rollback이 되면 error 상태가 되기 때문에, exception이 발생하면 해당 쿼리를 다시 실행하던, 어떻게 하던 처리하면 될 겁니다. 즉, 트랜잭션 1이 해당 record에 대해 업데이트를 수행하고 commit을 하지 않았습니다. 그 상태에서 다른 t2가 들어와서 update를 하려고 하면, 동시 업데이트를 못하게 t2를 막아버립니다. 따라서, t1이 수행한 갱신이 손실되는 일이 발생하지 않습니다. 그러면, 이런 경우에는 어떨까요?
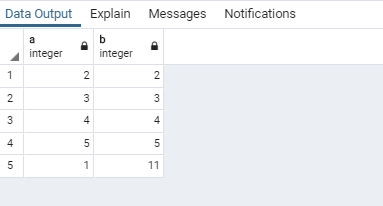
다시, t의 테이블 내용을 (1,1), (2,2), (3,3), (4,4), (5,5)로 초기화를 시키고 다음 스케쥴을 수행해 보겠습니다.

이번에는 두 트랜잭션이 다른 record를 업데이트 하는 상황입니다. 마찬가지로 session 1에서 Query1을 먼저 수행합니다.
다음에 Session 2에서 Query4, update 문을 수행하는데요. 어랏? commit이 되었습니다. 다르게 동작하는 것을 알 수 있습니다. 이는 세션 1과 세션 2의 업데이트 대상이 되는 레코드가 다르기 때문입니다. 만약에 테이블 전체를 lock 했다면, lock이 걸렸을 겁니다만, 서로 다른 레코드를 update 하는 데, 굳이 막을 필요는 없습니다. 오히려 더 비효율적일 거에요.

다음에 session1에서 query2를 수행합니다. 그러면, a가 1인 레코드만 업데이트 되었다는 것을 알 수 있습니다.
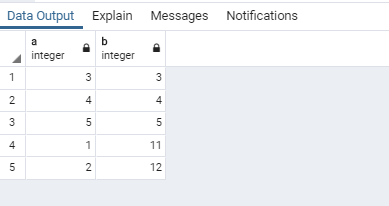
다음에 session1이 commit을 날린 후에는 a가 2인 레코드도 12로 업데이트 되었음을 알 수 있습니다.

스케쥴을 다음과 같이 해보겠습니다. 두 트랜잭션은 모두 Read committed로 하겠습니다.

세션 1에서 Queyr1을 수행하고, 세션 2에서 update문을 수행했는데, Session2에서 commit이 떨어졌습니다. 같은 레코드에 접근하는 연산임에도 불구하고요. 이는 무엇을 의미할까요?

2번째 줄에 있는 쿼리를 Q1, 5번째 줄에 있는 쿼리를 Q2, 8번째 줄에 있는 쿼리를 Q3이라고 해 보겠습니다. session1에 있는 Q1까지 실행한 후에, session의 Q2를 실행하려고 하는 경우 block이 일단 걸립니다. 다음에, 세션 1의 Q3을 수행하고 commit을 걸어버린 경우에, Q2가 실행이 되는데요.
세션 1이 commit가 될 때 까지 수행이 되지 않습니다. block이 걸려버립니다. 그러면 session1은 a가 1인 레코드에 30을 업데이트 하고 커밋 상황이였고, 다음에, session2가 a가 1인 레코드에 10을 업뎃한 상황입니다. 그리고 커밋을 하면, 이미 session2보다 먼저 들어와 있었던 session1이 30을 update 한 정보가 지워져 버립니다.
즉, 저는 S1을 먼저 수행시켰고, 이것이 차례로 a = 1인 레코드의 b값을 20으로 업뎃을 수행했는데, 갑자기 S2가 끼어들어서 a = 1인 값을 10으로 업뎃을 수행하라는 Query가 들어온 경우에, update 값이 10으로 덮어씌워져 버리는 문제가 발생하였습니다.

그렇다면, 이런 경우는 어떨까요? 역시 세션 1은 Query1과 Query3을 수행합니다. 그리고 Session2가 Query2를 수행합니다. 쿼리 2는 쿼리1과 3 사이에 수행됩니다.
일단 Query1을 수행해 보았습니다.
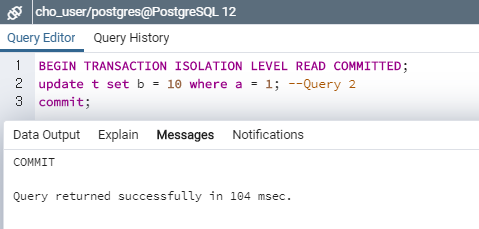
그리고, 다른 세션에서 Query2를 수행합니다.

다음에 Q3을 수행한 결과를 출력합니다. commit이 일어나기도 전에, 변경된 값이 반영되었다는 것을 알 수 있습니다.
'코딩 > Sql' 카테고리의 다른 글
| sql union 연산자 : 결과를 합친다. (2) | 2020.06.09 |
|---|---|
| sql injection과 jdbc PreparedStatement (2) | 2020.06.02 |
| sql group by 2개 이상 : 나눌 기준을 select 절에도 똑같이 적어주면 된다. (1) | 2020.05.10 |
| sql rollback commit 연산과 작업 단위 (2) | 2020.05.05 |
| sql null 값이 왜 필요할까요? (0) | 2020.04.27 |


최근댓글