제목이 꽤 도발적인 거 같네요. ps를 하시다 보면 종종 듣는 이야기 중 하나는, 상수 최적화, 혹은 O(n/32)나 O(n/64)입니다. 그것이 공간이 될 수도 있고, 시간이 될 수도 있는데요. 32와 64. 무언가와 연관이 있는 듯 싶습니다. 환경에 따라 다르겠지만, 보통 우리가 흔히 알고 있는 int형, long long형의 bit 수이기도 합니다.
공간을 n/32나, n/64로 compress 하는 문제를 생각해 봅시다.

사실, trie나 set, map을 쓰셔도 됩니다. 그런데 STL을 직접 구현해야 하는 경우, 2번째 것과 3번째 것은 구현하는 데, 상당히 어렵습니다. 1번은 시도해 볼 만 합니다. 그런데 메모리 제한이 128M로 꽤 넉넉하다면 어떨까요? 이 때는 이야기가 달라질 수도 있습니다. 왜냐하면 Trie는 30개의 bit를 하나 하나씩 모두 탐색해야 하기 때문입니다.
여기서, 우리는 1byte의 공간을 차지하는 변수가 8개의 상태를 가지고 있을 수 있다는 것을 주목할 필요가 있습니다. 그러면, 10억개의 상태를 저장하기 위해서 몇 byte의 공간이 필요할까요? 이는 10억개의 bit를 저장하기 위해서 얼마나 큰 메모리 공간이 필요하느냐를 물어보는 것과 같습니다.
10억/8 = 1.25억 byte입니다. 이것은 약 120Mbyte 정도가 됩니다.

그러면 어떻게 압축을 할까요? 예를 들어 18이라는 데이터가 있다고 해 봅시다. 이것은 1번째 bit와 4번째 bit가 1입니다. 즉 18은, 정수 18이라는 값을 가집니다. 그런데 관점을 살짝 비틀어 보면 1과 4번 bit가 켜졌다는 정보를 저장하고 있다고 보아도 됩니다. 그러면, 수 5억이 있는가? 8억 7000이 있는가? 에 대한 정보는 어떻게 저장하면 좋을까요?

먼저, 배열에 저장하겠다는 아이디어를 생각해 볼 수 있습니다. 충분한 공간만 있다면, O(1)만에 접근할 수 있기 때문입니다. x가 있는지 없는지는 arr[x]의 값이 0인지, 1인지만 검사하면 됩니다. 이는 그렇게 어려운 일이 아닙니다. 그런데 10억개의 char형, 10억개의 int형. 생각보다 많은 공간을 차지합니다. 전자는 대략 1Gbyte 정도 됩니다.
예를 들어, 1byte짜리 char형 10억개를 저장했다고 해 봅시다. 그러면 1Gbyte. 생각보다 공간을 너무 많이 쓰고 있어요. 그런데, 우리에게 중요한 것은 상태 0/1이냐입니다. 0과 1은 1개의 bit로도 충분히 표현할 수 있습니다.
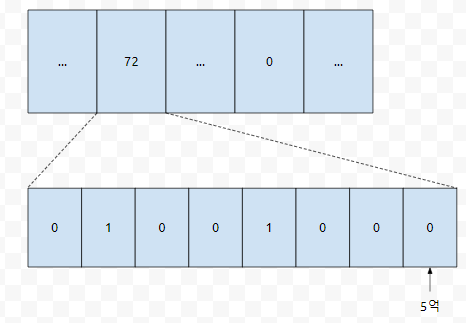
그러면 이런 식으로 8개의 상태를 하나의 char형 변수에 표현할 수 있습니다. 10억개를 선언해야 했는데, 1.25억개 정도의 char형 변수를 저장하는 배열만 할당하면 되는 셈입니다. 그렇다면 bit operation으로 어떻게 잘 비비면, 중복없이 [1, 10억] 범위에 있는 수가 들어오는 데이터에 대해서, 잘 처리할 수 있을 겁니다.
그렇다면, x가 있는지 없는지, 어떻게 접근해야 할까요? 자료형의 크기가 1byte라면 하나당 8bit씩 차지하니까, 배열의 [x/8]번째에 접근한 다음에, 그 값을 읽어냅니다. 이걸 v라 합시다. 그 다음에, v의 x%8번째 bit의 값을 읽어내면 됩니다. 4byte라면 어떤가요? 하나당 32bit씩 차지하니까, 배열의 [x/32]번째에 접근한 다음에, 그 값을 읽어냅니다. 다음에, v의 x%32번째 bit의 값을 읽어내면 됩니다. 예제를 통해서 보여드리겠습니다.

11이 있는지를 보고 싶습니다. char형 배열이라면, 하나당 8개의 bit를 가지고 있어요. [11/8]을 계산하면 1인데요. 배열의 1번째 원소에 접근합니다. 35입니다. 이 값을 읽어냅니다. 다음에 11%8을 계산하면 11을 8로 나눈 나머지이므로 3인데요. 3번째 bit의 값을 얻어오라는 의미입니다.
이 값은 0입니다. 따라서, 11은 0입니다. 그러면 11을 추가하고 삭제할 때에는, 1번째 원소의 값만 갱신하면 될 거에요. 이에 대한 코드를 작성하면 아래와 같습니다.
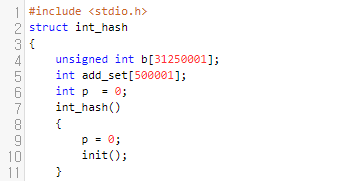
먼저, 저는 b 배열을 선언했습니다. 위에서 설명한 char형 대신에, unsigned int형을 선언했습니다. 이것도 크게 다르지는 않습니다. 한 개당 8bit가 아닌 32bit, 그러니까 32개의 상태를 가지고 있는 것만 다를 뿐입니다.

그 다음, add 함수를 보겠습니다. 이 부분은 bit 연산을 알고 있다면 크게 어렵지 않습니다만, 그래도 한 번 더 짚고 넘어가도록 하겠습니다. x>>5는 x를 32로 나눴을 때 몫, x&31은 x를 32로 나누었을 때 나머지를 의미합니다. 먼저 20번째 줄에 (1U<<(x&31)) 이라는 것이 보일 겁니다. 이것은, x를 32로 나눈 나머지를 k라 했을 때, k번째 bit만 켜져 있음을 의미합니다. 그러면 b[x>>5] |= (1U<<(x&31))은 무엇을 의미할까요? x/32번째 원소의 x%32번째 bit가 꺼져있으면 키라는 의미입니다.

그러면 제거는 어떻게 하면 될까요? 역으로 1<<(x&31)을 비트 반전한 것은 ~(1<<(x&31))이 됩니다. 예를 들어, x&31이 5였다고 하면, (1<<(x&31))은 0..0100000이 될 겁니다. 이것을 반전 시켰으니 1..1011111이 될 거에요. 25번째줄의 의미는 무엇일까요? 어떻게 되었던지 간에, x/32번째 원소의 x%32번째 bit를 0으로 만들겠다는 거에요. 어떠한 bit와 0을 and 하면 무조건 0이 나온다는 것을 이용한 것입니다.
다음, is_exist도 크게 어렵지 않아요. b[x/32]번째 원소의 x%32번째 bit가 켜져 있는지를 검사하면 됩니다.

x%32가 3이라고 한다면, mask 값이 8이 되어야 합니다. 노란색 부분만 검사하면 되는데, ? and 1 = 1이라면 ?는 1이고, ? and 1이 0이면 ?는 0이다. 라는 성질을 이용한 것입니다.
그러면 초기화가 문제가 될 수 있어요. add 수가 10만번 정도밖에 들어오지 않았는데, 3125만개의 배열을 초기화 하는 것은 낭비입니다. 코드를 보셨다면 add_set이라는 것이 있었다는 것을 알 수 있는데요.

이것은, 어떠한 수를 넣었는지만 저장하고 있습니다. add가 호출이 될 때 마다, p값도 증가합니다. 그러면 init를 호출한다면, add_set에 있는 것을 모두 제거한 다음에 p의 값을 0으로 만들어 버리면 될 거에요.
'자료알고 > 자료구조' 카테고리의 다른 글
| c++ set이나 map을 전체 순회하는 데 시간 복잡도는 얼마일까요? (4) | 2020.01.31 |
|---|---|
| 균형 이진 트리 : 제약 조건이 맞지 않으면 추가적인 연산을 한다. (2) | 2020.01.11 |
| 스파스 테이블 (sparse table) : 2의 거듭제곱 단위로 점프한다. (4) | 2019.12.20 |
| 우선순위 큐 : 부모가 자식들보다 rank가 높다. (0) | 2019.12.16 |
| k번째 숫자 구하기 : 트라이(Trie) 구조를 이용해 봅시다. (2) | 2019.12.05 |


최근댓글