시간 복잡도를 어떻게 대강 분석할까요? 실행 시간을 보고, 추정을 하시면 됩니다. 정말 괴랄한 복잡도가 아니라면, O(n), O(n^2), ... 등은 어느 정도 맞아 떨어집니다. 저는 java에서 메서드를 실행하는 데 걸린 시간을 측정할 때, System.nanoTime()을 이용하는 편입니다. 이것은 정밀한 시간 측정을 해 주지는 못합니다만, 어느 부분에서 시간 초과가 날 수 있는지 후보해를 추릴 수 있습니다.
질문이 하나 들어왔습니다. M자리 수와 N자리 수를 BigInteger로 곱하였습니다. M, N은 30만 자리 정도 되었다고 합니다. 10진수로 M자리 수라면, 32bit 2진수가 10진수 9자리와 대응이 됩니다. 그래서, bit 연산을 잘 이용하면 M과 N이 최대 30만자리까지 나오니까, (3.4)^1.5를 계산하면 600만 정도밖에 나오지 않을 겁니다. 그런데 오래 걸린다는 겁니다.
어느 부분에서 오버헤드가 걸린 걸까요?
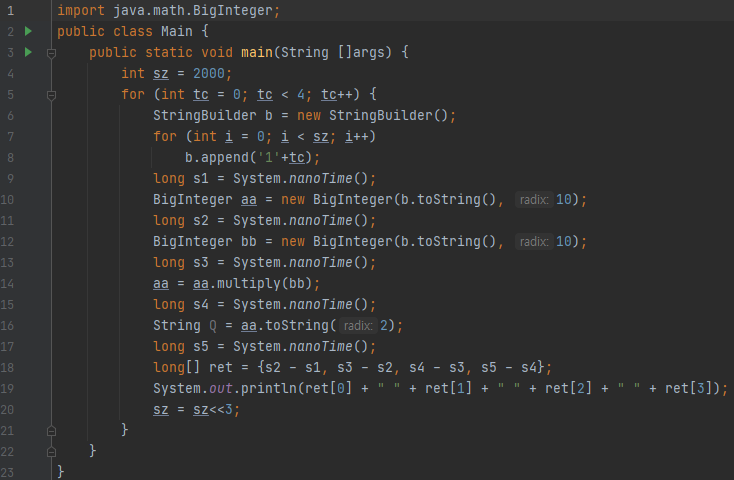
BigInteger에서 곱셈을 하기 위해서, 새로운 BigInteger 객체를 생성하고, multiply를 하고, toString으로 꺼내 옵니다.

시간 측정을 해 보니, 위와 같았습니다. 이 중 마지막 케이스는 자릿수가 100만을 조금 넘긴 케이스입니다. 출력된 숫자들만 보도록 하겠습니다. 51142602800, 51402952400, 722012600, 835430100. 이 중에 앞에 2개는 500억을 넘어갑니다. 뒤에 2개는 각각 7억, 8억이니, 그리 크지 않습니다. 즉, 앞에 2개의 작업의 오버헤드가 매우 컸다는 이야기입니다.
이 둘은 String을 인자로 받는 BigInteger 생성자였습니다. 케이스가 증가할 때 마다 데이터 size는 8배로 커지는데요. 3번째 케이스와 4번째 케이스를 보았을 때, 앞에 두 수는 대략 40배에서 90배 가량 커짐을 알 수 있습니다. 인자로 넘겨준 string의 길이에 제곱 비례한다는 것이 강력하게 의심이 드는 상황입니다.
String을 BigInteger로 받는 생성자는 내부에서, String과 radix를 받는 생성자를 호출하게 됩니다.

이 함수의 내부를 천천히 봅시다. numBits가 있는데요. 이 복잡한 식이 무엇을 의미하는지는 잘 모르겠지만, 2진수로 표현된, 32개씩 묶은 배열의 크기를 얻기 위해서 그러한 계산을 함을 알 수 있습니다. 이 부분은 알고리즘의 복잡도를 분석하는 데, 그리 중요하지 않습니다. 상수를 분석하는 데에는 중요할 수 있겠네요.

477번째 줄에 while loop가 있습니다. 이게 뭘 하는 것인지는 잘 모르겠습니다. 그런데, 이것은 cursor 값에 따라서 빠져 나올 것인지, 그렇지 않을 것인지 결정이 된다는 것을 알 수 있습니다. 그러면, 이 커서가 어떤 것에 의해 변하는지 봐야 하는데요. digitsPerInt 배열을 보면 알 수 있을 듯 싶습니다.

10진수인 경우에는 이 값이 9임을 알 수 있습니다. while loop는 10진수인 경우 cursor가 9씩 증가하고, radix가 2진수일 경우에는 32만큼 증가함을 알 수 있어요. 즉, 32진수로 표현된 string이 들어오는 경우에는, 2진수로 표현된 string이 들어오는 경우보다 대략 5배의 사이클을 더 돔을 알 수 있어요.
다음에 루프를 돌면서, substring이랑 parseInt를 호출하는데요. 이것은 별 문제가 되지 않습니다. destructiveMulAdd가 문제가 되는데요. 1번째 인자인 magnitude를 보겠습니다.

magnitude는 배열입니다. 그리고 이것의 길이는 (numBits + 31)에 32를 나눈 값과 관련이 있습니다.

그리고 이 numBits는 bitsPerDigit와 관련이 있는데요.

2진법의 string이 들어왔을 때 보다, 32진법의 string이 들어왔을 때, numBits가 대략 5배 가량 크다는 것을 알 수 있습니다. 이것은 magnet의 길이와도 연관이 되어 있습니다.
이제 이 메서드 내부로 들어가 보겠습니다.

자세한 알고리즘 말고, 주요 루프만 보도록 하겠습니다.
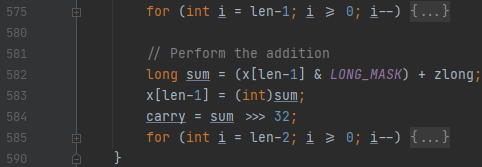
보니까, 그냥 len만 보입니다. 이 len은 magnitude의 길이를 의미합니다. 이 루프 안을 보시면 단순한 bit 연산으로만 이루어져 있음을 알 수 있습니다.

이 둘을 종합해 보면, 블록 자릿수와 관련이 깊음을 알 수 있습니다. 그리고 while이 바깥에서 1번, 그 안에서 부르는 함수 내에서 for 루프가 2번 돌아가니, 제곱 비례한다는 것을 코드로도 확인할 수 있었습니다. 묶여진 자릿수가 크면 클수록 오래 걸릴 거고요. 해당 메서드에 넘기는 2번째 인자인 superRadix는 intRadix[radix]로 계산이 되는데요.
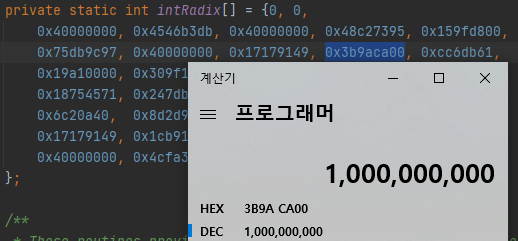
10진수인 경우만 봅시다. 0x3b9aca00은 10억임을 알 수 있습니다. 이는 9자리 단위로 끊었기 때문에, 10억 단위로 저장했다는 이야기가 됩니다.
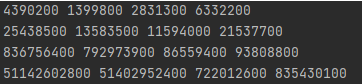
다시 2번 그림을 봅시다. 4번째 줄은 10진법으로 표현한 길이 100만이 조금 넘는 데이터에 대해서 51.1초가 걸렸다는 이야기입니다. 100만을 제곱하면 대략 1조가 될 텐데. 상수가 꽤나 작았던 모양입니다?
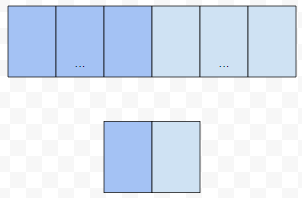
이는 2중 순회 대상인 배열을 덩어리 별로 묶어서, 압축을 해 놓았기 때문입니다. radix가 10일 때에는 9개가 한 개의 원소로 압축되고, 특히 radix가 2일 때에는 32개가 하나의 원소로 압축이 되어 버립니다. radix가 10이였고, 9개가 하나의 원소로 퉁쳐졌기에, for loop, 575나 585번째 줄에 있는 for loop 안쪽 연산을 수행하는 횟수는 생성자로 넘어온 string의 길이 제곱에 81을 나누어야 합니다. 1조에서 81을 나누면 대략 100억 가량이 됩니다. 거기에 비트 연산은 무겁지 않으니, 꽤 큰 길이의 string이 들어와도 생각보다 빠르게 동작합니다.
그런데, 기본적으로 상수가 낮아졌을 뿐이지, 복잡도가 string 길이의 제곱이라는 것은 변하지 않습니다. 매우 긴 string을 BigInteger의 생성자로 넣는 것은 신중해야 한다는 사실도, 테스트 케이스의 수를 변화시키면서, 실행 시간을 측정함으로서 알 수 있었습니다.
'자료알고 > 알고리즘' 카테고리의 다른 글
| 트리 dp : 스크루지 민호 문제로 간단한 것만 풀어 봅시다. (2) | 2021.04.25 |
|---|---|
| 백준 배열 돌리기 5 : 전략적인 브루트 포스로 풀어봅시다. (0) | 2021.04.04 |
| 여러 트릭에 응용되는 트리에서의 dfs ordering을 알아봅시다. (0) | 2021.03.07 |
| 백준 최소 환승 경로 : 허브와 노드를 생각하자. (0) | 2021.02.07 |
| functional graph 에서 사이클을 어떻게 묶어낼까요? (0) | 2021.01.26 |


최근댓글