BinarySearch에 대해서 잘못된 부분을 수정하기 위해서, 프로그램을 작성하게 되었습니다. 코드 제너레이터를 이용해서, 게터, 세터, equals, hashCode 등을 자동으로 생성하게 되었습니다. 중요한 부분만 코드로 보도록 하겠습니다.
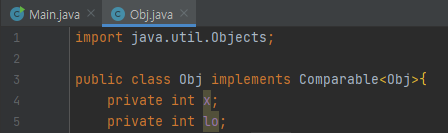
Obj 클래스입니다. binarySearch를 할 때, key가 여러개 나올 때 lower_bound나 upper_bound를 이용할 수 없다고 없다고 하였습니다. 그것이 가능하게 하려면, unique 한 속성으로 떨어트려야 하는데요. 키가 등장한 위치 lo는 unique 합니다. 따라서, (x, lo) 쌍도 unique 할 겁니다.
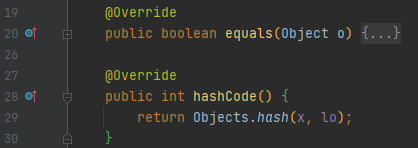
hashCode를 재정의 한 것을 보니까 Objects.hash(x, lo); 가 보이는데요. 이것이 무엇을 하는지는 모르겠지만, x와 lo를 가지고 hash 값을 생성하는 역할을 하는 것은 분명해 보여요.

내부를 보시면, Arrays.hashCode(values)라고 되어 있는데요. 이 values는 x와 lo를 가지고 있습니다. 안으로 들어가 봅시다.
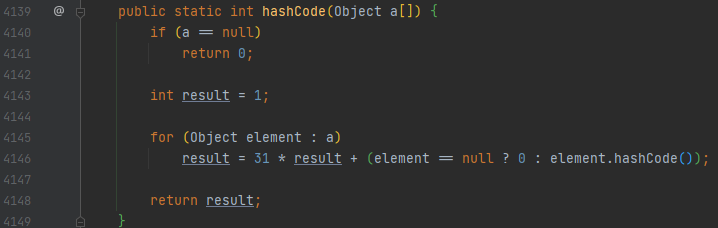
Object 배열 a를 모두 돌면서, 뭔가를 하는 것을 볼 수 있어요. element.hashCode()가 중요한데요.

이는 배열 내에 있는 객체들의 hashCode 값들을 모두 취합한다는 이야기입니다. 예를 들어 a[0]은 Obj1을, a[1]은 Obj2를 가리킨다고 해 봅시다.

그러면 Obj1의 hashCode 값을 구합니다.

다음에 Obj2의 hashCode 값을 구합니다. 이렇게 구한 hashCode의 값을 합산해서 리턴하게 됩니다. 재귀 비슷하게 돌아간다고 보시면 됩니다. x와 lo가 넘어갔는데요. int형이므로, Boxing이 되어서 Integer로 들어갑니다. Integer는 hashCode랑 equals가 구현되어 있는데요.

Integer x와 Integer y의 value가 같으면, 같은 hashCode 값을 리턴합니다. 따라서, 두 Obj 객체가 lo와 x가 같다면, 문제의 메서드인 Objects.hash(lo, x)도 같은 값을 리턴할 거고, Obj에 오버라이딩이 된 hashCode도 같은 값을 리턴하게 됩니다. 당연하게도 lo와 x에 hashCode가 정의되어 있지 않으면, 엉뚱하게 동작할 겁니다. 사실, 저는 잘 쓰지는 않지만, 여러 필드가 있을 때, 유용하게 쓰일 듯 싶어요.

그런데 메서드 설명을 보면, Warning이 떡하니 있는데요. single로 넘겼을 때, hash랑 hashCode가 같지 않을 수도 있다. 뭐 이런 내용이 있습니다. 요약하자면, hashCode랑 hash 값이 다를 수도 있다는 말입니다.
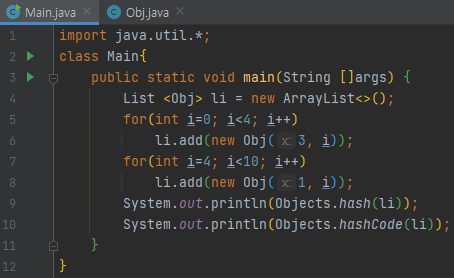
위 프로그램을 보면, list li의 hash 값이랑 hashCode 값을 찍고 있어요. 같은 결과가 나올까요?

다른 결과가 나옵니다.
'레퍼런스 > 분석' 카테고리의 다른 글
| java retainAll 메소드를 간단하게 분석해 봅시다. (0) | 2021.11.29 |
|---|---|
| python dictionary는 최악의 경우에 정말로 시간 복잡도가 선형일까요? (0) | 2021.11.06 |
| java list removeall vs clear : 언제 쓰는지 정확하게 알아봅시다. (0) | 2021.08.09 |
| java string strip 메서드에 대해 제대로 알아봅시다. (0) | 2021.07.31 |
| java string trim 메서드에 대해 제대로 알아봅시다. (4) | 2021.06.20 |


최근댓글