퀵 정렬 알고리즘은 간단하게 언급만 하고 넘어가겠습니다. 사실, ps에서 그리 많이 쓰이는 정렬 방법은 아니기 때문입니다. 다만, 평균적으로는 병합 정렬보다는 빠른데, 그 이유는 다음 시간에 평균 복잡도를 분석하면서, 언급하도록 하겠습니다.

먼저 퀵 정렬은 피봇을 잡는 것부터 시작합니다. arr의 [s,e] 구간을 정렬한다고 하면, pivot을 선택해서, 그 피벗이 있는 위치와 arr[s]의 값을 교환합니다. 이는, 피봇을 선택하는 함수와, 그걸 토대로 divide 하는 것을 별개로 생각하기 위해서입니다.
여기서 저는 pivot을 5로 잡았습니다. 그리고, 우리는 2개의 포인터를 잡을 겁니다.

이는 각각 le와 ri 포인터입니다. 어떤 식으로 교환이 일어나는지만 보시면 되는데요. 우리는 ri 포인터가 s+1부터 e까지 이동할 겁니다. 일단, le를 pivot이 있는 위치를, ri는 le가 가리키고 있는 위치로부터 1칸 뒤의 원소를 포인트 합니다. 그러면, 우리는 arr[ri]의 값이 pivot보다 작은 경우에, le를 하나 증가시키고, arr[le]와 arr[ri]의 값을 교환할 거에요.

예제를 봅시다. [5, 1, 2, 7, 3]을 5를 기준으로 나눠봅시다. 그러면 처음에 le와 ri가 노란색으로 표시한 지점을 가리킬 겁니다. 그런데 이 값은 5보다 작습니다. 따라서 le를 하나 증가시킵니다.

그리고 arr[le]와 arr[ri]의 값을 change 하고, ri를 하나 증가시킵니다. le와 ri의 값이 1로 같았으니까, 바뀔 일 없겠네요.

이제 arr[ri] < 5인지 검사해 봅시다. 네 맞네요. 그러니까 le의 값을 하나 증가시킵니다.
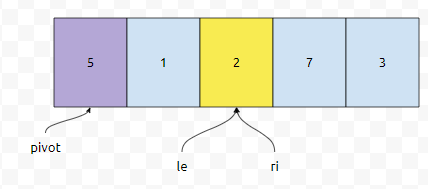
그러면 le가 노란색을 가리킬 겁니다. 다음에 arr[le]와 arr[ri]의 값을 change 하는데요. 두 개가 포인트 하는 원소가 같기 때문에, 변하지는 않습니다.
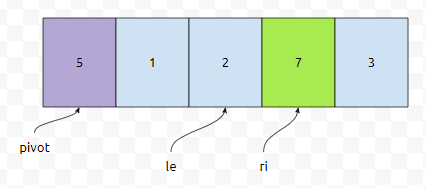
다음에 ri는 초록색으로 칠한 부분을 가리킵니다. 그런데 이 값은 피벗 값보다 작지 않습니다. 그렇기 때문에, 아무 일도 일어나지 않습니다. ri 값이 증가합니다.

그러면 이 값은 5보다는 작은데요. 피벗 값보다 작으면 어떤 일이 일어난다고 했나요? le 값이 하나 증가합니다.
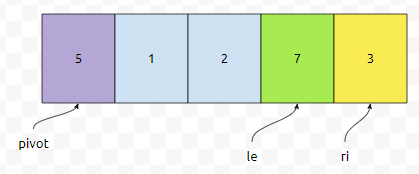
그리고 arr[le]와 arr[ri]가 교환이 됩니다. 교환이 되면 아래 그림과 같이 됩니다.
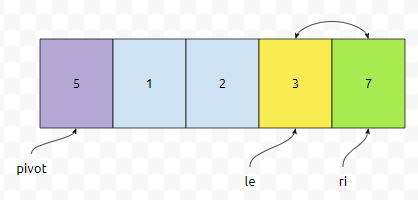
이제 ri가 하나 증가하는데요. 하나 증가하니까, 제가 정렬할 부분을 ri가 가리키고 있지 않습니다. 따라서, 여기서 끝내고 pivot 값과 어떠한 값을 교환을 할 겁니다. 보통, 피벗을 기준으로 왼쪽에는 작은 값을, 오른쪽에는 크거나 같은 값을 놓을 거에요. [5, 1, 2, 3, 5, 7, 2]를 같은 방식으로 partition 해 보시면 아실 거에요.
그러면 어떻게 하면 좋을까요? arr[le]와 arr[pivot]을 교환하면 되지 않을까요?

그러면 5를 기준으로 딱 2개의 부분으로 분할이 되는 것을 알 수 있어요.

그 다음에 노란 부분과 초록색 부분을 다시 sort 하면 되겠네요.
그러면 대체 무엇을 한 것일까요? 원리 자체는 복잡하지 않아요.
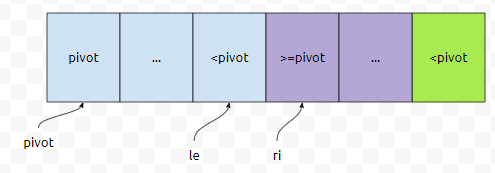
le가 포인트하고 있는 원소 까지는 pivot보다 작은 게 자명합니다. 물론 피벗값 위치만 빼고요. 그러면 ri가 보라색 부분, 그러니까 기준 값보다 크거나 같은 경우에는, le가 증가하지 않고 ri만 증가하는데요. 언제까지 증가할까요?

초록색 부분을 가리킬 때 까지 증가해요. 그러면, 초록색을 가리킬 때 어떻게 되나요? le가 하나 증가한 다음에 arr[le]와 arr[le]를 바꿔치기 하지 않을까요?

그림과 같이 됩니다. 대략적으로 partition 알고리즘을 보면 이런 식입니다. 사실, 병합 정렬과 비교를 하면 추가 공간도 안 쓰고 무지막지하게 좋을 거 같은데 왜 안 쓸까요? 최악의 경우가 있기 때문입니다. 왼쪽이 너무 많이 쏠리거나, 오른쪽이 너무 많이 쏠리면 bad partition이 일어났다고 하는데요. 예를 들어보면 이런 데이터가 있다고 가정해 봅시다.

그러면, 이 때 데이터가 어떻게 쏠릴까요? 알고리즘에 따라서 partition을 해 보면, ri값이 항상 pivot보다 크기 때문에, ri값만 증가하고, le는 증가하지 않아요.

그러면 1을 기준으로 왼쪽 부분은 없고, 오른쪽 부분만 n-1개겠네요. 이제 또 2를 기준으로 나눠 봅시다.
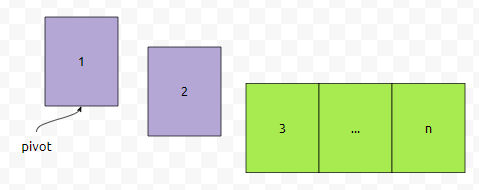
그러면 3부터 n까지는 2보다는 크기 때문에, 2를 기준으로 나눠진다면 왼쪽 것은 없지만 오른쪽 것이 n-2개로 나눠질 거에요. 파티션 함수의 시간 복잡도는 O(배열 크기)인데요. 이를 토대로 Quick sort의 최악 복잡도를 계산해 보면, 제곱이 쉽게 나와버립니다.
그렇기 때문에, 퀵 정렬이 단독적으로 잘 쓰이지는 않습니다. 피벗을 잘 선택하면 모를까. 이는 다음에 배울, 퀵 셀렉션도 같은 문제를 지니고 있습니다.
'자료알고 > 알고리즘' 카테고리의 다른 글
| k번째 수 찾기 : count sort를 응용해 봅시다. (2) | 2019.08.17 |
|---|---|
| 양방향 탐색 : 시작점과 도착점에서 동시에 탐색을 한다. (5) | 2019.08.16 |
| 슬립 정렬 : 아이디어는 좋은 거 같은데.. (8) | 2019.08.13 |
| 비교 기반 정렬 : 왜 하한이 nlogn일까? (2) | 2019.08.10 |
| 최대공약수 최소공배수 알고리즘 : 짧은 코드 이해해 봅시다. (2) | 2019.08.07 |


최근댓글