요새 이모지를 많이 씁니다. 여기서 질문. 이모지가 있는지 어떻게 검사해야 할까요? 사실 저는 정규 표현식만 있는 줄 알았습니다만, emoji 관련한 패키지가 있어서 그것을 이용해 보기로 했습니다.

먼저 emoji 패키지를 깔아주세요.

emoji 1.7.0 기준으로, core의 replace_emoji 한 줄이면 이모지가 제거됩니다. 첫 번째 인자는 string, 2번째 인자는 이모지가 나오면 어떤 것으로 replace를 할 것인가입니다. 저는 빈 문자열로 두었기 때문에, 이모지가 제거됨을 알 수 있어요. 결과를 보면 아래와 같습니다.

cho 가가 나오네요. 정규 표현식을 쓰면 몇 줄이 될 것이 단 한 줄에 끝나버리니, 생각보다 괜찮지 않나 싶습니다. 그리고, 내부를 보면, 정규표현식이 아니라, 이모지 문자 집합들의 딕셔너리를 가지고 옵니다. 이 딕셔너리를 처음 초기화 할 때만 구축하게 되는데요.
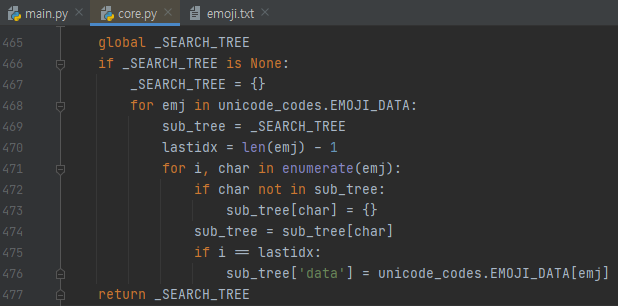
그렇기 때문에, 실제로 이모지 관련 데이터들은 한 번만 구축되게 됩니다.
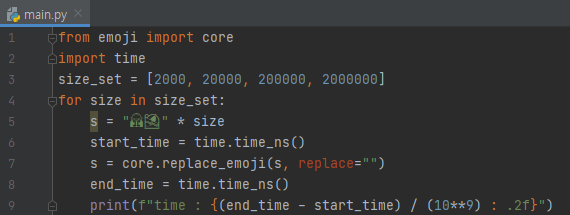
수행시간은 어떻게 될까요? 딕셔너리에서 값을 저장해 두고, 각 문자, 혹은 연속된 무언가에 대해서 검사하기 때문에 상당히 빠르게 동작합니다.

사이즈 40만에서 400만으로 증가했을 때, 10배가 더 걸린 것으로 미루어 보아 O(n)에 동작함을 알 수 있습니다. 그러면, 이모지들은 잘 제거할까요?

해당 테스트 케이스 파일을 받아 돌려보니, 잘 동작함을 알 수 있습니다.
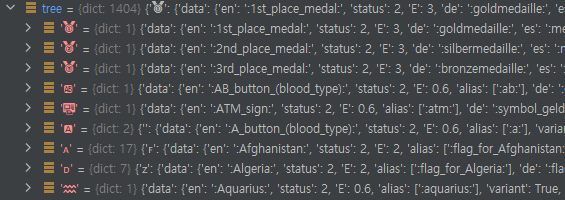
해당 딕셔너리를 보겠습니다. tree에 키들은 각각의 이모지들이 있습니다. 그리고 value에는 또 딕셔너리가 담기게 되는데요. 이를 서브라고 해 봅시다. 서브에 "data" 키를 가지는 것들이 있고, 그렇지 않은 것들이 있습니다. 이들의 차이는 무엇일까요?

대표적으로, 귀마개 이모지는 서브트리의 키에 바로 "data"가 들어옵니다. 그런데 그렇지 않은 경우가 있는데요. "KR"과 같은 것이 대표적인 예입니다. 이 때, K와 R과 같은 것들을 "REGIONAL INDICATOR SYMBOL LETTER" 라고 합니다. 이들은 어떻게 동작할까요?
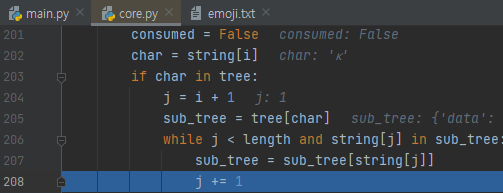
먼저 국가 구분자 K가 들어왔습니다. 203번째 줄로 들어가면, j가 i+1이 될 거니, K 다음에 오는 문자를 뽑을 겁니다.

이 때 뒤에, R이 오지 않고 바로 끝나버린다면, 어떻게 될까요?
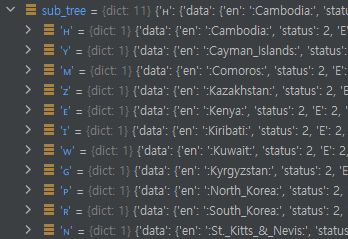
딕셔너리에 "data"라는 키가 없기 때문에, 바로 237번째 줄로 가는데, consumed가 처음에 false로 설정되었고, filtering 되는 문자가 아니기 때문에 국가 구분 코드 "k"가 그대로 추가됩니다.
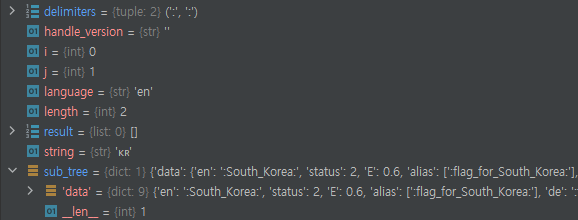
그렇지 않고, 뒤에 국가 구분 코드인 'R'이 오면 어떨까요? 이미 "R"은 한국이라는 정보가 들어가 있기 때문에, "KR"을 하나의 이모지로 인식하게 됩니다. 즉, subtree는 K 뒤에는 무슨 문자들이 와서 하나의 이모지를 구성한다. 라는 정보를 주기 위해, 둔 장치인 셈입니다. 이러한 것도 제거하려면 core의 _get_search_tree를 이용하면 되긴 합니다만, 권장하는 방법일지는 모르겠습니다.
'레퍼런스 > 예제' 카테고리의 다른 글
| java stream filter 함수에 대해 알아봅시다. (0) | 2022.08.19 |
|---|---|
| java stream range 메서드와 rangeClosed 메서드에 대해 알아봅시다. (2) | 2022.08.15 |
| 파이썬 폴더 재귀 탐색에 쓰이는 os.walk 함수에 대해 간단하게 알아봅시다. (0) | 2022.06.14 |
| 파이썬 os.scandir 함수는 언제 사용하면 좋을까요? (2) | 2022.06.12 |
| 파이썬 확장자를 얻을 때 쓰는 os.path의 splitext 함수를 알아봅시다. (0) | 2022.06.01 |


최근댓글