fastapi에서 UploadFile을 이용하여 파일을 올리고 제한 검사를 서버단에서 하는 방법을 알아보겠습니다.
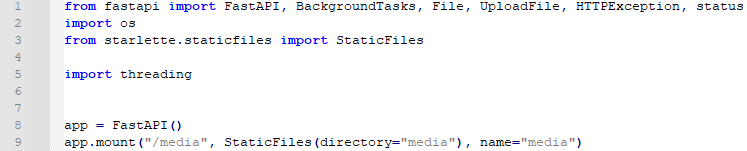
먼저 로컬에 파일을 올릴 것이므로 app.mount로 미디어 경로도 같이 설정해 줍니다. 참고로 요래 설정하면, 루트 프로젝트에 media 디렉토리가 있어야 동작합니다.
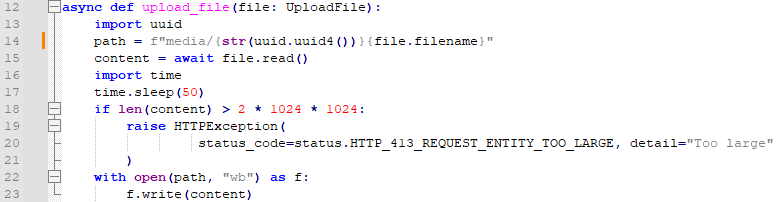
다음에 upload_file 함수입니다. file의 size 체크를 해서 2메가가 넘어가는 파일은 거부합니다. 그러기 위해, await file.read()를 호출한 다음에, content의 길이가 2메가가 넘는 경우 거부를 합니다. 그렇지 않으면, path 위치에 content를 씁니다.
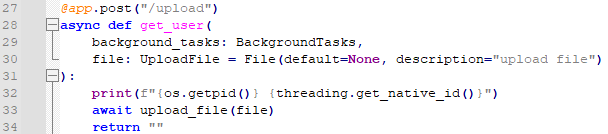
다음에, get_user 함수입니다. 함수 이름이 이상한 거 같은 건 넘어갑시다. /upload를 부르면 2메가 이하인 파일을 업로드 하게 됩니다.
프로그램은 제대로 잘 동작할 겁니다. 문제는, 3기가가 넘는 파일을 올릴 때입니다. content의 길이가 2메가가 넘기 때문에 거부가 됩니다만, 문제는 메모리가 치솟아 버린다는 것입니다.

실제로, 작업 관리자 창에서 확인해 보면, python이 3695.7메가까지 올라가는 것을 확인할 수 있습니다.
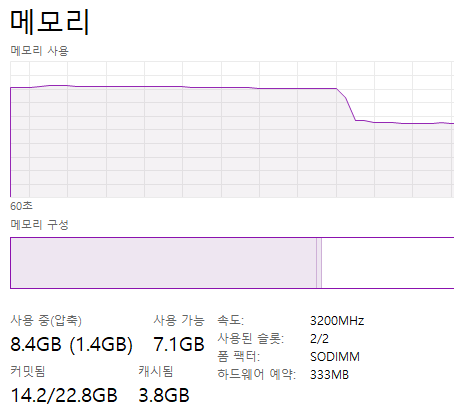
메모리를 봅시다. 상당히 급격한 변화가 있었는데요. 이는 제가 중간에 프로그램을 종료해 버렸기 때문입니다. 3기가에 비해서 2메가는 매우 작습니다. 그런데 왜 3기가가 넘는 메모리가 사용되었을까요? 비밀은 content = await file.read()에 있습니다. 파일의 전체 내용을 가지고 온 다음에, 크기를 검사하다 보니 벌어진 사단입니다.
그러면 어떻게 해야 할까요?
서버단에서 처리하는 방법은 chunk 단위로 읽어버리는 것입니다. file.file의 정체는 SpooledTemporaryFile입니다. 이를 조금씩 읽어들입니다. 이 과정에서 읽은 누적 크기가 제한을 넘어가게 되면 에러를 뱉어버리면 됩니다.
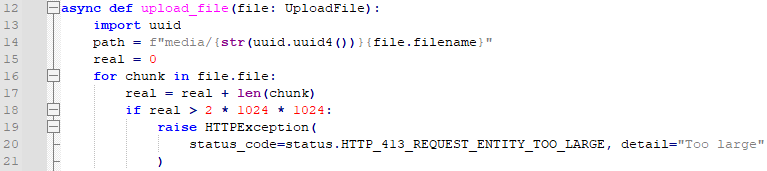
해당 코드는 위와 같습니다. real은 0입니다. 그리고, 파일을 읽어낼 때 마다, chunk의 크기를 더합니다. 크기는 파일의 끝까지 갈 때 까지 계속 누적이 되므로, 2메가가 넘어가면 중간에 에러가 나오게 됩니다.

다음에, 22번째 줄 file.seek(0)이 중요합니다. 이것은 파일의 맨 처음으로 가는 것입니다. 이것이 왜 필요할까요? file.file을 돌면서 chunk를 읽어버릴 때 마다 파일을 계속 읽어버리기 때문입니다.
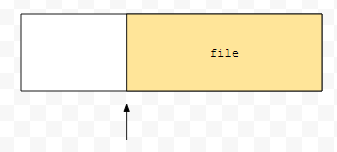
예를 들어 이 상태에서 일정 부분만큼 파일을 읽었다고 해 보겠습니다.
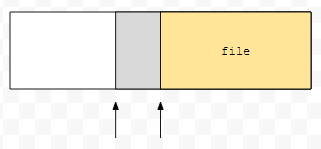
회색 부분만큼만큼 읽었기 때문에, 다음에 await file.read()를 하면 노란색 부분밖에 읽지 않습니다.
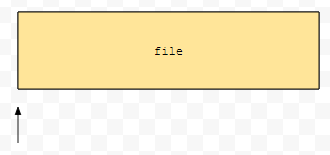
처음 부분으로 이동하게 되면 온전히 전체 파일을 읽게 되기 때문에, 정상적으로 수행됩니다.

메모리 또한 급격하게 늘어났다가 줄어들지 않음을 확인할 수 있습니다.
'웹 > FASTAPI' 카테고리의 다른 글
| fastapi pydantic root validator를 알아봅시다. (1) | 2023.06.06 |
|---|---|
| fastapi alembic revision 명령어를 쓸 때 마이그레이션 버전을 커스텀하게 생성해 봅시다. (0) | 2023.05.31 |
| fastapi background tasks를 간단하게 알아봅시다. (1) | 2023.04.25 |
| sqlalchemy nullpool과 staticpool을 설정하면서 왜 커넥션 풀이 필요한지 이해해 봅시다. (0) | 2023.03.22 |
| fastapi path parameter를 활용해 보고 조심해야 할 것도 알아봅시다. (0) | 2023.02.26 |


최근댓글