안녕하세요. chogahui05입니다. 최근에 코딩 테스트를 개최하면서, 다중 정렬을 람다로 구현한 풀이를 보고 배울 점이 많다고 느꼈어요. 람다는 정렬할 때도 쓰고, stream에서도 많이 써 먹긴 합니다. 그런데, 이 글에서는 따로 언급해 드리지는 않겠습니다. 대신에, 람다를 이해할 때 필수적으로 이해했으면 좋을만한 apply 메서드만 언급해 보겠습니다.
제가 computeXXX 시리즈를 설명할 때도 언급이 되었습니다. 그러니, 이 포스팅을 보고 오셔도 좋겠네요.
[관련글]
map 인터페이스에 있는 computeIfAbsent와 computeIfPresent를 예로 들어 설명해 보겠습니다. 이 메서드 들을 이해하면, 어느 정도는 람다가 이런 것이구나. 이해는 할 수 있기 때문이에요.

이 메서드를 분석해 봅시다. computeIfAbsent인데요. key 값이 들어오고요. value 값이 들어올 때, computeIfAbsent를 호출하고 있어요. 1번째 인자는 그대로 key를 받고, 2번째 인자는 k->new HashSet<>() 이라는 이상한 인자를 받는데요. 안으로 들어가 봅시다.

일단 key는 크게 어려울 건 없어요. 그리고 955번째 줄에 key 값이 null인 경우에, if 블록 안으로 들어가 버려요. 그리고, 957번째 줄에, mappingFunction.apply(key)가 있어요. apply에 대한 설명을 보겠습니다.

보면, Applies this function이라고 되어 있어요. 해당 함수를 적용한다. 이겁니다. 그런데, to the given argument라고 되어 있으니, 함수 인자로 주어진 것을 가지고 적당히 적용시켜서 결과값을 내 버린다는 이야기가 됩니다.
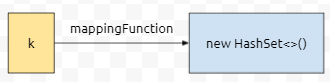
이 함수는 k값에 상관 없이 무조건 new HashSet<>()이 리턴되어 버립니다. 그래서 apply된 결과는 new HashSet<>()이 됩니다. 만약에 키가 존재한다면, 그에 대응되는 값인 HashSet<>()을 리턴할 겁니다. 여기서 질문. 키 값이 있으면 어떻게 될까요? 그러면 이 매핑 apply 함수 자체가 호출되지 않을 겁니다. 왜? 955번째 줄에 걸린 if 블록이 수행되지 않기 때문입니다. key, value 쌍을 (1, 1), (1, -1), (-1, 3)을 차례로 넣어 봅시다.
키 값이 Integer이고, value가 hashSet인 해시맵이 있다 해 봅시다. 처음에 해시맵은 비어 있을 겁니다. 따라서, 어떤 키 값이 들어와도, 957번째 줄이 수행되서 mapping Function이 적용된 값인, new HashSet<>()이 newValue로 들어갈 겁니다.

그리고 이 새로운 객체가 958번째 줄에 의해서 put이 될 겁니다. 키 값이 1이고, value 값이 새로운 hashSet 객체겠죠.

즉, 파란색으로 칠한 객체가 리턴됩니다. 그러면 이 위치에 뭘 추가하면 되나요? 1을 추가하면 됩니다.

그래서 computeIfAbsent의 리턴값에 add(1)을 해 주면 됩니다.
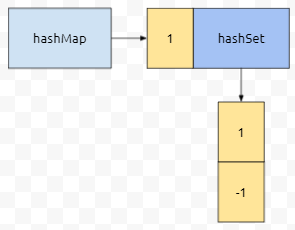
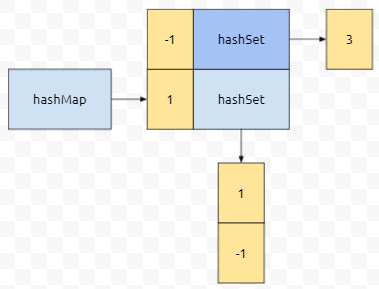
다음에 키가 1이고 값이 -1인 정보가 추가되면 어떨까요? 이 때에는 이미 1이 있는 상황이므로, 군청색 객체가 리턴됩니다. 그러니, 이 군청색 hashSet에 -1을 넣으면 되겠네요. 다음에 키가 -1이고 값이 3인 정보가 추가될 겁니다. 어떻게 그림이 그려질까요?

마찬가지로 생각하시면 됩니다. 이전에 해시맵에 -1은 없었으므로, mappingFunction에 의해서 새롭게 만들어진 hashSet 객체가 리턴될 겁니다. -1, 새롭게 만들어진 객체가 hashMap에 들어가게 됩니다.

computeIfAbsent는 군청색 객체를 리턴하므로, 군청색 객체에 3을 추가하면 됩니다.
computeIfPresent는 어떤가요? 보시면, 키 값이 없는 경우는 상관이 없어요. 키 값이 있는 경우에 뭔가 처리를 더 하는데요.

newValue를 보시면, key와 oldValue 이렇게 2개를 받아요. oldValue는 뭐에 대응되나요? 1016번째 줄을 보면, key값에 대응되는 값인데요. Integer를 키로 가지고 HashSet을 value로 가진다면, newValue는 키 값이 k인 value들의 집합 정도를 의미할 겁니다. 이제, 1017번째 줄을 보면, apply(key, oldvalue)가 있는데요. 이것은 그냥, 현재 key와, key에 대응되는 값 value를 함수 인자로 받아먹겠다는 의미입니다.

그러면 이것은 무엇을 하냐면요. 인자 2개를 받아서, 리턴값을 받아먹는다는 의미입니다. 1021번째 줄의 else 절은 이 mapping 함수의 리턴값이 null인 경우에 발동하게 되는데요. 그냥 키 값을 Map에서 지워버리죠?

그래서, k에 대응되는 값 집합이 공집합일 때 삭제하려면 이렇게 computeIfPresent를 작성하시면 됩니다. 이건 대체 무엇인가? 2개의 인자를 받아요. k와 v를 받겠죠? 이것은 key에 mapping 되는 값입니다. 예를 들어서 인자 key에 -1이 들어왔다. 그러면 매핑 함수에 들어오는 k는 -1이고 v는 -1에 대응되는 군청색 부분일 거에요.
그러면 이 두 인자가 들어왔으면 어떻게 처리해야 하나요?

일단 v.remove(value);를 해야 합니다. v는 hashSet, 즉 집합일 겁니다. 이 집합에서 value를 제거해 보아야 합니다. 그리고 나서, v.size()를 체크해서 0이면 null 값으로 리턴해 버리고, 아니면 그냥 v를 리턴하면 됩니다. 보시면, apply는 인자가 1개일 때, 혹은 2개일 때 결과를 적용해서 리턴값을 돌려주는 역할만 하고 있어요. 인자 n개를 받아서 결과를 리턴하는 함수랑 매우 유사해요. 그렇게 해석하시면 조금 더 쉽게 이해를 할 수 있을 듯 해요.
'코딩 > Java' 카테고리의 다른 글
| java threadlocal 클래스에 대해서 간단하게 알아봅시다. (0) | 2021.12.29 |
|---|---|
| 토이 프로젝트를 하면서 느꼈던 광범위한 예외의 위험성 (9) | 2021.10.08 |
| java UnsupportedOperationException 예외를 copiesList를 보면서 알아봅시다. (2) | 2021.06.22 |
| java switch 문 : string에 대해서 어떻게 쓰는지 예제로 알아봅시다. (0) | 2021.06.06 |
| java visual vm 으로 메모리 사용량을 간단하게 파악해 봅시다. (0) | 2021.04.13 |


최근댓글