nameAB 테이블에 저장되는 레코드들은 아래와 같은 컬럼들을 가집니다. key는 하나도 없습니다.
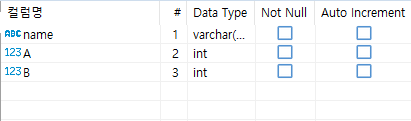
이 문제를 생각해 봅시다. name 별로 A가 최대일 때의 B값, A가 최소일 때의 B값을 가져와서 그것의 차이를 구하는 게 목표입니다. 단, A와 B는 0이상 32768 미만의 정수입니다. 그리고, 임의의 str, a에 대해서, 이름이 name이고, A값이 a인 레코드는 많아봐야 1개만 있다고 가정하겠습니다. 예를 들어서, name이 'tEq'라고 해 보겠습니다.

그러면 nameAB에서 다음과 같은 레코드들이 나옵니다. A값이 최소인 레코드의 B값은 1710이 나옵니다. A값이 최대인 레코드의 B값은 1233이 나옵니다. 이 두 값의 차이는 1233 - 1710 = -477입니다. 이 값을 name별로 가져오면 됩니다. name 필드는 최대 3자이고, 레코드는 35만개 정도가 저장되어 있습니다.
쉽지 않아 보이는데요. A를 1차 우선순위로 하면서 A와 B에 대한 정보를 같이 가져올 수 있는 방법을 고민하면 됩니다. 이 방법을 응용한다면, 백준에 있는 이 문제도 생각보다 쉽게 풀 수 있습니다. 둘 다 정수이므로, 아래와 같이 임시로 저장하면 됩니다.

B는 32768 이하이므로, B가 아무리 커 봤자, A 값이 작으면 T값이 작을 겁니다. 중요한 사실입니다. 만약에 T값을 아래와 같이 설정했다면 어떻게 될까요?
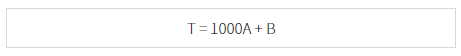
A값이 1이고 B값이 32767인 경우와 A값이 3이고 B값이 0인 경우를 생각해 보겠습니다. 1000 + 32767이 3000보다 작지 않습니다. 심지어, T 값이 1000일 때, A와 B 값을 복원할 수 없습니다. A 값이 0이고 B값이 1000일 수도 있지만 A값이 1이고, B값이 0일 수도 있기 때문입니다.
그렇기 때문에, T = MA + B 꼴로 저장했을 때, M 값은 B의 최댓값보다 크게 설정하였습니다.

그러면 쿼리를 위와 같이 작성해 볼 수 있습니다.

group by name에 의해서, name을 기준으로 grouping이 됩니다. 다음에 select를 할 때 아래와 같은 것들이 적용됩니다.
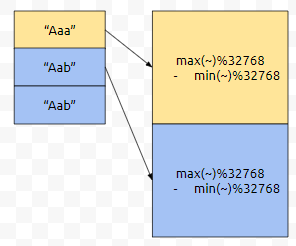
여기서, 32768*A+B가 A와 B값을 복원할 수 있는 데이터라는 것이 중요합니다. 이것을 32768로 나눈 나머지가 B값이기 때문에, 이것을 토대로 select 할 식을 작성해 주시면 됩니다.
name별로 A값이 최소인 레코드와 A값이 최대인 레코드 2개를 동시에 뽑아오려면 어떻게 하면 될까요? 수치만을 가져오는 것이랑, 레코드 둘을 동시에 뽑아오는 것은 이야기가 다릅니다.

위 쿼리는, name 그룹에 대해서 32768A + B의 최대값을 구합니다. 32768A + B의 최솟값을 구하려면 min을 집계 함수로 쓰면 됩니다. {name, 최대 As dat} 하고, {name, 최소 As dat}이 둘 다 결과에 포함되려면 union을 해야 하는데, 중복이 제거 되어야 할 필요가 없으므로, union all을 쓰겠습니다.
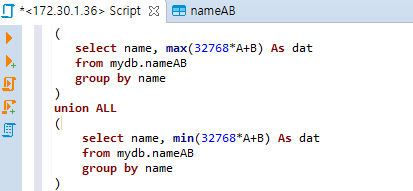
그러면 이런 식으로 작성을 할 수 있고, 결과는 아래와 같습니다.

이 결과값을 바탕으로, floor(dat/32768), dat%32768을 뽑으면 A, B값이 복원됩니다.
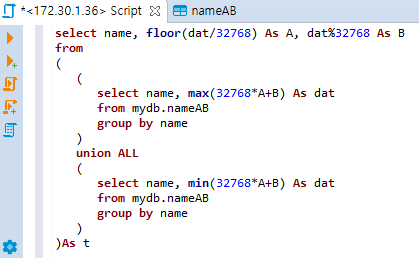
최종 쿼리는 위와 같습니다. 1~1.2초 정도 소요가 되네요.
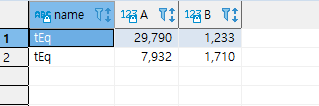
그리고 결과 값에서 name이 'tEq'인 것만 필터링 걸었을 때, name이 'tEq'인, A가 최소인 레코드와 A가 최대인 레코드 두 개가 나타남을 볼 수 있습니다. 다음에는 이 글을 쓰기 위해서 제가 어떤 삽질을 했는지 보도록 하겠습니다.
'코딩 > Sql' 카테고리의 다른 글
| mysql nullif 함수 : 조건을 만족할 때 null을 리턴한다. (0) | 2020.12.21 |
|---|---|
| mysql decimal vs double : 고정 소수점과 부동 소수점 (0) | 2020.11.16 |
| mysql db에 있는 테이블 칼럼 정보들을 모두 긁어와 봅시다. (0) | 2020.10.22 |
| mysql on duplicate key update 문으로 upsert를 수행해 봅시다. (0) | 2020.10.13 |
| 로컬에서 mysql 루트 비밀번호 재설정 하기 (0) | 2020.09.29 |


최근댓글