sql에서 with 절은 해당 쿼리 내에서 임시 결과를 정의하고 쓸 때 유용하게 사용됩니다. sql 코딩 테스트에서 꽤 어려운 문제가 나왔을 때, 잘 써먹으면 유용하지 않을까 싶어요. 사용 방법 보다는 문제 상황을 하나 정의하는 게 좋을 듯 싶네요. 그러면서 이해를 해 보도록 하겠습니다.

먼저 salaries를 보겠습니다. 이 테이블에는 1년마다 계약을 할 때 각 일꾼들의 연봉을 나타냅니다. 테이블을 조회해 보겠습니다.

그러면, 10001번 일꾼에 대해서, 각각 60117, 62102, 66074, ... 등의 근로 계약을 했음을 볼 수 있어요. 연봉 하니까 무슨 생각이 드나요? 해당 테이블에 근로자가 n년간 계약한 데이터가 있다고 해 봅시다. 그러면, 회사에 다니는 동안의 평균 연봉도 있을 겁니다. 이것을 가지고 장난을 쳐 보겠습니다.

그럴려면, emp_no를 기준으로 groupping을 해야 합니다. 구해야 하는 것은 무엇인가요? salary의 평균 값입니다. 그러면 해당 쿼리는 어떤 것을 구하는 것인가요? 각 근로자가 이 회사에 속해 있는 동안 평균 연봉이 얼마나 변했는지를 나타냅니다. 아. 제가 한 가지 제약 조건을 말하지 않았는데, 1년 단위 계약 동안에 퇴사하는 일은 없고, 해당 레코드에는 1년 단위의 계약만 등장한다는 것입니다. 같은 시기에 같은 근로자가 둘 이상의 계약을 하지 않습니다. 대충 이 정도 전제를 깔면 되겠군요.

그러면 이런 테이블이 나오는데요. 자. 우리는 이 회사에서 근무하는 동안 평균 연봉이 1만달러 대, 2만달러 대, ... , 20만달러대 그룹 등이 있을 겁니다. 이 그룹들 중에 가장 높은 연봉을 받는 사람들을 구하는 것이 목표입니다. 이 결과를 R1이라 합시다.
문제가 복잡해 보이니 쪼개 봅시다. 먼저, 그룹에서 가장 높은 연봉의 평균 값을 구해 봅시다. 그럴려면, 각 근로자 별로 평균 연봉값을 구한 결과값 R1에서 무엇을 기준으로 group by 해야 하나요? floor(average/1만)을 기준으로 그룹핑 해야 합니다. 다음에, 어떤 값을 집계해야 하나요? average의 max 값. 그러므로 요구하는 부분을 가져오기 위해서 아래와 같은 쿼리를 작성하면 됩니다.

요렇게 작성하면 결과는 아래와 같이 나옵니다.
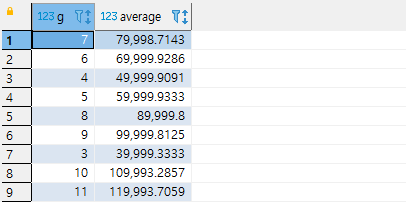
복잡하지는 않네요. 이 결과를 R2라 합시다. 이제, R1과 R2를 가지고, 그룹 별로 가장 높은 연봉을 받는 사람들과, 연봉을 출력한다면 어떻게 해야 할까요? 결국 R1과 R2를 join을 해야 하는데, R1.average와 R2.average가 같은 것만 가져오면 됩니다. 문제는 R1을 가져오기 위한 쿼리도 복잡하고, R2를 가져오는 쿼리도 복잡하다는 것입니다.
하나 더 중요한 점은 R2를 얻어오기 위해, R1을 썼다는 것입니다. 그렇다면, 미리 계산된 결과를 T로 두면 어떨까요? 즉, T는 근로자 별 회사에 근무하는 동안 평균 연봉을 구하는 쿼리를 의미합니다. R1을 의미합니다. 문서에서는 Common Table Expression에 가깝습니다. 아래에 있는 with 절을 보겠습니다.

문서에서 with cte_name(col_name, ... ) as subquery라고 되어 있는데요. 대응해 보면 cte_name은 T를 의미하고, emp_no와 average를 컬럼으로 가집니다. 다음에 subquery로, salaries 테이블로부터 emp_no 별로 평균 salary 값을 구하라는 쿼리가 주어졌어요. 이 subquery의 result set이 T가 됩니다. 정말 그런지 보겠습니다.
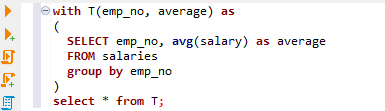
T에 있는 모든 데이터들을 출력해 봅시다.

그러면, 각 근로자 별로 회사에 근무하는 동안의 평균 연봉을 가져온 결과 T가 됩니다. 물론, 이것은 바로 이어지는 쿼리에서의 임시로 사용할 수 있는 결과가 됩니다. 이제 이것을 가지고 1만달러대, 2만달러대, ... , 20만달러대 그룹 중에 가장 많은 연봉을 가지는 사람들과 얼마나 받는지를 알아내 봅시다.

먼저, T는 근로자의 평균 연봉을 의미합니다. T1은 근로자의 평균 연봉인 T를 가지고 다시 집계를 한 결과를 나타냅니다. 어떻게 집계를 했을까요? floor(average/10000)을 기준으로 group by를 했어요. 그래서 무엇을 집계했나요? 평균의 max값이요. T는 근로자 번호와 평균, T1은 그룹과 평균이 나올 겁니다. where 절에서 T1.average와 T.average가 같은 경우만 가져오면, 각 그룹마다 average의 max 값만 가지고 오게 될 겁니다.

실행 결과는 위와 같습니다.
'코딩 > Sql' 카테고리의 다른 글
| postgresql pg_sleep 함수를 이용해서 쿼리를 delay 시켜봅시다. (0) | 2021.12.09 |
|---|---|
| 계층형 쿼리에 쓰일 법한 with recursive 절에 대해 알아봅시다. (0) | 2021.12.02 |
| mysql substring_index 함수를 이용해서 tokenize를 해 봅시다. (0) | 2021.09.30 |
| jdbc에서 connection을 close 해 주지 않았을 때 어떤 일이 일어나는지 실습해 봅시다. (0) | 2021.09.29 |
| postgresql sequence permission denied 오류를 dbeaver로 해결해 봅시다. (0) | 2021.08.17 |


최근댓글