linux의 awk 명령어를 알아보겠습니다. 이것은 주로, 데이터를 가공해서 원하는 컬럼만 출력할 때 쓰이는데요. 어떻게 쓰는지 간단하게 예를 들어보겠습니다.
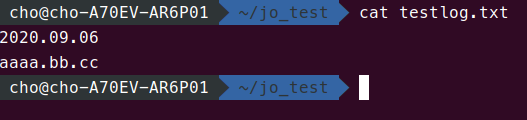
jo_test의 testlog.txt에는 2020.09.06이랑 aaaa.bb.cc가 있습니다.

awk는 'pattern {action}'으로 쓰는데, action이 print $1입니다. 이것은, 뭔가를 출력하라는 의미입니다. 여기서, $1은 구분자들로 구분된 것 중에서 첫 번째 필드를 의미합니다. 보통은, 스페이스 문자일 테니, 2020.09.06이랑 aaaa.bb.cc가 그대로 출력됨을 알 수 있습니다.
구분자를 .으로 하려면 어떻게 하면 좋을까요?

man 페이지를 보면, -F가 있습니다. 이것은 필드 구분자를 주는 옵션입니다. -F 뒤에 옵션이 붙는데요. 저는 구분자를 '.'으로 설정했으므로, 명령어는 아래와 같이 적어주면 됩니다.

그러면 .을 기준으로 분할이 되었음을 볼 수 있습니다. $1을 print 하라는 action을 주면, 2020.09.06 대신에 2020만 출력하는데요. 이는, 구분자가 .였기 때문에, 처리할 때 2020, 09, 06 순으로 필드가 들어가기 때문입니다.

그러면, 구분자가 여러개인 경우에는 어떻게 하면 좋을까요? 예를 들어서 .이나 #을 기준으로 분할하려면. 이것은 생각보다 빡셉니다. 구분자 다음에 구분자가 나올 경우에, 필드 값이 빈 문자열이 나오는 경우가 있을 텐데요. 위의 예가 그 예입니다. 저는 여기서, 2020, 09, 06과 aaaa, bb, cc로 분할하고 싶습니다.

그러면 .이나 #을 뜻하는 [.#]을 -F 옵션 뒤에 넣을 수 있습니다. 그런데, 그러면 빈 값이 중간에 출력됩니다. 어떻게 하면 좋을까요? 정규 표현식 중에는 +가 있는데, 이는 하나 이상을 의미합니다.

그러면, .나 .#나 .. 같은 것도 구분자로 취급을 합니다. 따라서 2020.#09.06에서 1번째 필드는 2020, 2번째는 09, 3번째는 06이 추출됩니다. 정규표현식을 잘 쓰면 되게 강력해 지겠군요.
이런 문제도 생각해 보겠습니다. 1번째, 2번째 필드를 개행으로 구분지어서 찍는다. 이런 문제는 어떻게 하면 좋을까요?

testlog2.txt는 다음과 같은 내용이 저장되어 있습니다.

그러면, action 부분에 print $1"\n"$2를 적어주면 됩니다. 이는 1번째 필드 + 개행 + 2번째 필드를 출력하라는 의미입니다. 여기까지 하셨다면, auth.log에 있는 접속 ip들을 출력할 수 있겠네요.

접속 시도가 찍히는 로그 패턴은 넷 중 하나였습니다. 월 일 시간 시스템 sshd: Recived disconnect from 어쩌고, 월 일 시간 시스템 sshd: Disconnected from 어쩌고, 혹은 아래였습니다.
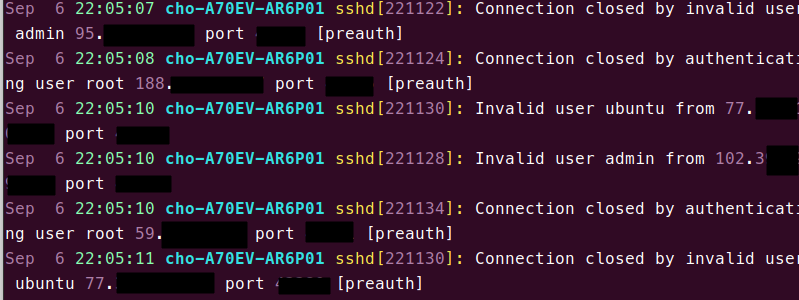
Connection closed by ~ user ~ 저쩌고, Connection closed by authenticating user ~ 저쩌고, Invalid user admin from 어쩌고. 대충 패턴을 보면, 8, 9, 10, 12번째 필드만 보면 알 수 있음을 알 수 있습니다.

이를 토대로 /var/log/auth.log로부터 8, 9, 10, 12번째 필드만 뽑아보면 위와 같이 나옵니다. 여기서 적당히 잘 필터링 하면 좋은데요. 정수.정수.정수.정수 꼴만 뽑도록 하겠습니다.

그러려면, 패턴을 ^\\d+\\.\\d+\\.\\d+\\.\\d+$로 주면 됩니다. 그러면 최소한 정수.정수.정수.정수 꼴의 패턴만 추릴 겁니다. 다음에 이를 토대로 중복된 것을 제거하려면, sort가 되어 있어야 하니, 추가로 sort랑 uniq 순서로 파이핑을 해 보겠습니다.

그러면 중복이 제거된 접속 시도 목록들이 출력됩니다. 사실 귀찮다면, 그냥 $1부터 $100번까지 쭉 뽑은 다음에 필터링 걸어서 출력해도 될 듯 싶네요. for loop를 걸어서 출력하는 건 다음에 이어서 해 보도록 하겠습니다.
'OS > 리눅스' 카테고리의 다른 글
| 터미널을 꾸미기 위해 유용하게 썼던 리눅스 cp -rp 명령어 (0) | 2020.09.19 |
|---|---|
| 리눅스 kill 명령어 : 프로세스에 시그널을 보낸다. (0) | 2020.09.10 |
| 리눅스 /etc/group 파일을 간단하게 봅시다. (2) | 2020.08.27 |
| 리눅스 history 명령어 : command 기록을 얻어온다. (0) | 2020.08.17 |
| 리눅스 readlink 명령어 : 심볼릭 파일의 경로를 읽는다. (0) | 2020.08.10 |


최근댓글