삽입 정렬의 복잡도는 O(n^2)입니다. 물론 평균 복잡도 또한 O(n^2)입니다. 물론, memcpy 등으로 실행 시간을 빠르게 할 수 있는 여지는 있지만, 거기까지일 뿐입니다. 다만, insertion sort의 장점도 있는데요. 거의 정렬된 데이터에 대해서는 상당히 빠르게 동작한다는 장점이 있어요. 하지만, 한 번에 한 요소씩. 비교 1번 할 때 마다, 1요소씩만 move 하기 때문에 효율적이지 않은데요. 이를 보완하기 위해서 gap이라는 변수를 둡니다.
그러면 먼저 init 함수를 봅시다.

먼저, si 라는 벡터가 있습니다. 여기에 무슨 값들이 들어있는지 봅시다.
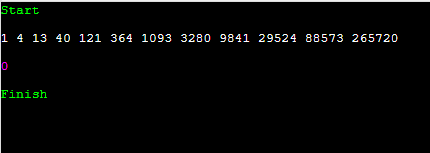
1, 4, 13, 40, 121, 361, 1093, 3280, ... 네. 이런 값들이 들어 있는데요. gap으로 쓸 겁니다. 예를 들어서, 길이가 10만 짜리인 배열이 있으면 29524, 9841, 3280, 1093, 364, 121, 40, 13, 4, 1 이 순으로 갭을 잡을 거에요. 이것을 gap sequence라고 이야기를 합니다.
이 때, 최악의 경우 O(n^1.5)정도라는 것이 알려져 있기는 합니다. 물론, O(n^1.33)이 되게끔 만드는 방법도 있는데요. 거기까지 깊숙하게 들어가지는 않겠습니다.

배열이 이렇게 있다고 가정해 봅시다. 그러면 gap을 어떻게 잡는 게 좋을까요? 일단, 29524, 9861, ... , 13은 너무 큽니다. 4는 적당한가요? 네. 2에다가 갭을 곱한 값이, 배열의 크기인 8보다 크지 않기 때문이에요. 사실 이렇게 처리하는 게 속 편하기도 하고요. 물론, 갭이 크기보다 작으면 subsort 하게끔 처리해도 됩니다.
하튼 저는 2에 gap을 곱한 것이 배열 크기보다 작거나 같다면 돌린다는 조건을 걸어놓았기 때문에, gap = 4부터 보도록 하겠습니다. 그러면 이걸 어떻게 해 줄 것이냐면요. 일단, 0번째 위치부터 4개 간격으로 잡아 보겠습니다.
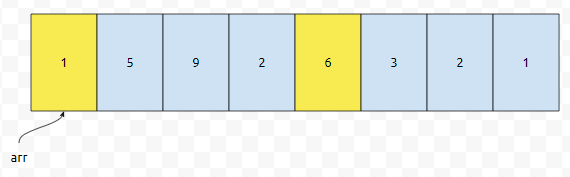
노란색으로 칠한 것에 대해서 insertion sort를 합니다. 오름 차순으로 정렬한다면, {1, 6}이니까 이 부분은 변화가 없을 거에요. 다음에 1번째 위치부터, 4개 간격으로 잡아보겠습니다.
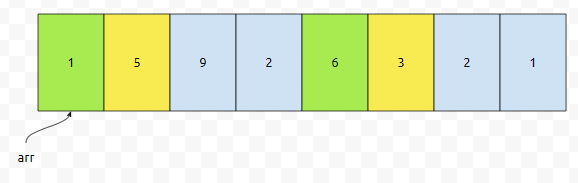
그러면 {5, 3}이 선택됩니다. 이것을 insertion sort를 하면, {3, 5}가 됩니다. 두 개의 수를 바꿔주면 되겠군요.
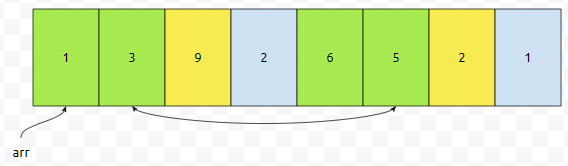
다음에, 2번째 위치부터 4간격으로 잡습니다. 그러면 역시나 노란 부분이 잡힐 거에요. {9, 2}가 선택이 되는데요. 오름 차순으로 정렬을 하려면 이 두 녀석의 순서를 바꿔줘야 합니다. insert sort를 수행하면 {2, 9}가 됩니다.
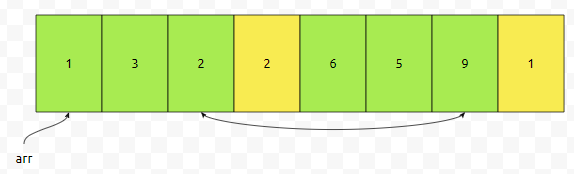
다음에, 3번째 위치부터 4간격으로 잡습니다. 그러면 어떻게 되나요? 역시 노란색 부분이 선택될 건데요. {2, 1}이 읽히는군요. 오름 차순으로 넣으려면, {1, 2} 순으로 되어야 합니다. 따라서 3번째 원소와 7번째 원소를 바꿉니다.

1회전이 완료되었습니다. 그 다음에 gap = 1인데요. 이 때에는 어떻게 하면 될까요?
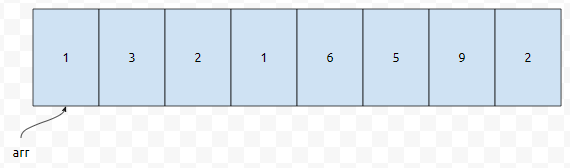
이 상태에서는 그냥 삽입 정렬 알고리즘을 수행하면 됩니다. {1, 5, 9, 2, 6, 3, 2, 1}의 경우에는 원소들의 이동 횟수가 어떻게 되나요? 16번이 되나요? 그런데 위 배열에서는 단 7번만 수행하면 된다는 것을 알 수 있어요. 일반적인 insert sort의 저격 케이스인, 내림차순 data로 비교해보면 더 극적인데요.

이 데이터에 대해서, 그냥 깡으로 하면, 비교 횟수는 (1+...+7) = 28회입니다. 그런데, 셀 정렬을 하면 이야기가 달라집니다.

먼저 갭4짜리에 대해서 sort를 하면, compare 횟수는 4입니다. 이 상태에서, 1회전을 또 돌리면 어떻게 될까요?
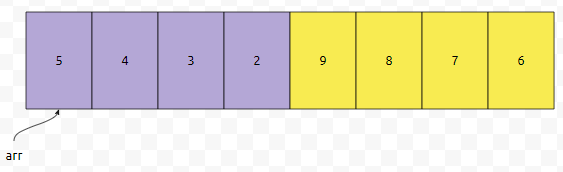
두 부분에 대해서 비교 횟수는 각각 6회입니다. 총 비교 횟수는 16입니다. 28에서 16으로 줄어든 것은 꽤 큽니다.
이제 코드를 봅시다.

먼저, 26번째 줄을 보면, gap에다가 2를 곱한 게 배열의 크기보다 크면 continue 하게끔 했어요. 만약에 그렇지 않다면, j를 기준으로 si[i]만큼 jump한 것을 부분 배열로 삼아서 subsort를 돌렸습니다.
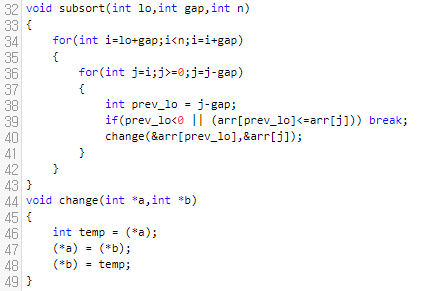
이 함수의 내부를 들여다 보면, 별 게 없습니다. 우리가 흔히 아는 insertion sort를 그대로 응용한 것 뿐입니다.
'자료알고 > 알고리즘' 카테고리의 다른 글
| 피보나치 수열 : 왜 깡재귀로 구하면 지수 복잡도일까? (9) | 2019.10.30 |
|---|---|
| 그리디 알고리즘 : 매 순간 최적의 해를 선택한다. (6) | 2019.10.26 |
| 팬 케이크 정렬 : 위에서부터 k개를 뒤집는다. (10) | 2019.09.17 |
| 라빈 카프 알고리즘 : 그래도 비벼볼 만한 문제가 있다. (6) | 2019.09.06 |
| 조화 급수 : ps에서 간간히 나온다. (8) | 2019.09.05 |


최근댓글