안녕하세요. chogahui05입니다. 자바의 해시맵은 hashCode를 기반으로 버킷의 어디에 들어갈지를 계산합니다. 그런데, putVal을 자세히 보셨다면 아시겠지만, hash function의 리턴값을 인자로 넣는 것을 알 수 있습니다. 이것은 어떻게 된 일일까요? java8에서 모 자료구조 코드를 조금씩 뜯어봅시다.

get 메서드를 보시면, getNode를 호출합니다. 그리고, 이 메서드는 hash(key)를 인자로 삼습니다.

이것은 put도 마찬가지입니다. 내부적으로 putVal을 호출하고, 이것 역시 hash(key)를 호출합니다.

내부를 보시면, key.hashCode 값을 h에 넣습니다. 여기서, 해시코드는, 오버라이딩이 된 hashCode 값입니다. 그리고 이것과 다른 값을 비트 xor을 하는데요. h>>>16입니다. >>은 알겠는데, >>>은 무엇인지 모르겠군요. 비트를 오른쪽으로 16만큼 이동시킵니다. 실험 프로그램에서는 Integer key 값을 0보다 크거나 같은 값으로만 넣을 겁니다. 그러니, 그냥 h xor (h/2^16)으로 봐도 되겠네요.
여기서 중요한 것은 함수 내부의 내용이 아닙니다. 아. 이런 것도 있구나입니다. 저는 이것을 바탕으로 충돌 데이터를 제작해 보고, 그럼에도 왜 빠르게 도는지 다시 언급해 보겠습니다.
Integer를 보면, Comparable<Integer>를 구현했음을 알 수 있습니다.

이는, 내부에 CompareTo가 있다는 의미입니다. 음수나 0이나 양수를 리턴하는 비교 함수가요. 이것이 어떤 역할을 하는지는 밑에서 후술하도록 하겠습니다. 1번 단락에서 정리한 내용을 토대로 그림을 그려보겠습니다.

hashCode 값을 토대로 해시 함수에서 특별한 값을 리턴합니다. 2번째 네모에서 h는 key.hashCode()로 구할 수 있습니다. 두 번째 네모에서 나온 값을 putVal에 넣습니다. load factor는 알려진 대로 0.75입니다. 그리고 초기 버켓 갯수가 16개이고, resize가 될 때 마다 2배씩 확장된다고 합시다. 그러면, 우리는 버킷이 32768개가 있을 때, 20000개의 서로 다른 Integer 키를 넣을 수 있습니다. 20000은 16384보다는 크고, 32768의 3/4보다는 작으니, 20000개의 데이터가 들어갔다면, 32768개의 버켓이 있을 겁니다.

hash값을 토대로, 몇 번 버킷에 넣을 지와, 노드의 hash값이 결정됩니다. 중요한 것은 이것은 해시코드와는 다르다는 것입니다. 정수 객체의 경우 코드값은 모두 다르므로, 인위적으로 같은 버킷에 여러개를 충돌내기 위해서는, 모듈로 연산과 저 값을 잘 이용해야 할 듯 싶습니다.
20000개의 키에 대해서 같은 바구니에 넣게 하게끔 시뮬레이션을 돌리는 코드는, 0부터 10억 정도까지만 돌려보면 됩니다. 물론, h ^ (h>>>16)이 0이 나오게끔 하려면은요. 그리고 이 작업은, 1분 이내에 끝나는 작업이니, 천천히 수행하시면 됩니다.
h ^ (h >>> 16)이 0이 되는 20000개의 Integer 값을 찾았다면, 규칙에 따라서 추가하시면 됩니다. 0부터 출발한다면, 32768, 32769를 순서대로 번갈아가면서 더하면 충돌을 매우 많이 낼 수 있습니다.

이에 대해서 확인을 해 보면, tab에 단 하나의 무언가만 있는 것을 알 수 있습니다. 이클립스에서도 확인을 해 봅시다.

다른 버켓들은 null임을 알 수 있습니다. 유독 [0]에만 매우 많이 몰렸다는 것을 눈으로 보셔도 알 수 있습니다.

이제, 특정한 키 값을 찾는 연산은 200만회 수행해 보겠습니다.

200만회를 수행해 보니, 실행 시간은 단 172ms에 불과했습니다. 한 버켓에 다 몰린 상황이라면, 2만개의 원소만 map 안에 있더라도 굉장히 오래 걸릴 텐데 어떻게 된 일일까요?
Tree에 넣는 작업을 어떻게 수행하는지 보면 알 수 있습니다.

먼저, if문을 보면, ph가 있고, h가 있습니다. 이 h값은 해시값을 의미합니다. 그리고 p가 문제인데요. p가 root부터 변하는 것으로 보아서, p는 현재 탐색하고 있는 노드라고 추측할 수 있습니다. 이 hash값을 기준으로 1차로 대소 비교를 하게 됩니다. Integer a, b가 있습니다. a ^ (a>>>16)하고 b ^ (b>>>16)하고 다르다면 key a와 b의 해시값이 다를 겁니다.
즉, 저 값으로 대소 판별이 된다면 기준점의 왼쪽 자식이나, 오른쪽 자식으로 들어가면 됩니다. 이것은 별 문제가 되지는 않습니다. 문제는, 현재 기준점하고, 찾으려는 키의 해시값이 같은 경우입니다. 그러면 계속 else if를 타고 내려올 겁니다.

equal을 했을 때도 다르다면, 1987번째 줄까지 내려옵니다. 이 조건문을 자세히 보면 (A && B) || C임을 알 수 있습니다. 즉, 비교할 수 있는 객체라면 초록색으로 색칠이 된 block은 수행되지 않고, 2002번째 줄로 바로 들어오게 되는데요. 1989번째 조건문은, 내부적으로 kc와 k를 비교하는 CompareTo를 호출합니다. 초록색 블록은 한 번 보았을 텐데요. find를 재귀적으로 호출하는 로직이 있습니다. 당연하게도, 초록색 블록은 Integer가 키라면, 호출되지 않습니다.
dir의 값에 따라서, 트리의 왼쪽에 추가할지, 오른쪽에 추가할지 결정합니다.
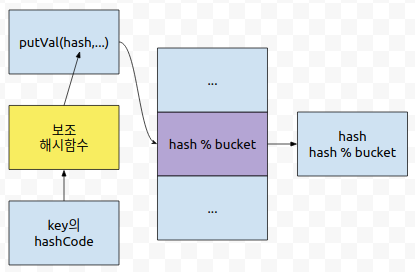
제가 오늘 설명한 내용을 한 장의 그림으로 정리하면 위와 같습니다. 보조 해시함수를 쓴다고, Integer에 대해서 최악의 데이터를 만들 수 없는 것은 아닙니다. 그렇지만, 단순히 Integer값 % bucket 사이즈로, 할당할 바구니 번호가 결정되는 것에 비하면, 충돌 데이터를 찾는 것이 어려웠습니다. 그리고 정수 객체의 경우에는 Comparable<T>가 구현되어 있어서 정말 최악의 경우라도 빠르게 insert하고, 찾는 연산 등을 수행할 수 있습니다. 그 정도만 짚고 넘어가셔도 무난할 듯 싶습니다.
'레퍼런스 > 분석' 카테고리의 다른 글
| java toLowerCase toUpperCase 를 수행하면 길이가 항상 같을까요? (4) | 2020.09.27 |
|---|---|
| 파이썬의 list.pop(0)을 쓰면 안 되나요? (0) | 2020.09.25 |
| 해시맵에 있는 tiebreakorder는 어떤 메소드일까요? (0) | 2020.08.28 |
| java ArrayList remove 메소드에 대해 알아봅시다. (0) | 2020.08.25 |
| java hashset : 어떻게 구현이 되어 있을까요? (3) | 2020.08.08 |


최근댓글