Java에서 구분자를 기준으로 문자열을 자르는 방법은 몇 가지가 있습니다. 이 중, StringTokenizer를 간단하게 알아보도록 하겠습니다. 그 전에, token이랑, 구분자에 대해서 간단하게 짚고 넘어갑시다.
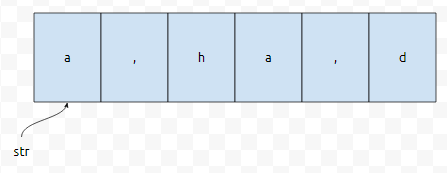
먼저 "a,ha,d"라는 문자열이 있습니다. 저는 ,를 기준으로 분리를 해 보겠습니다. 이 때, ,를 구분자라고 이야기를 합니다. 문자열을 ,를 기준으로 나눈 셈인데요.
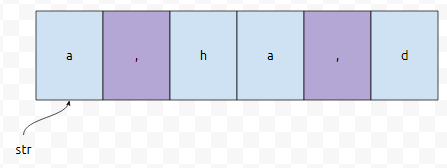
구분자를 보라색으로 표시해 보겠습니다.
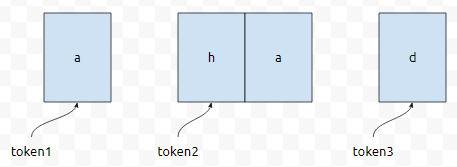
그러면 그것에 의해서 "a,ha,d"가 "a", "ha", "d"로 분리가 됩니다. 이러한 것들을 각각 토큰이라고 이야기를 합니다.
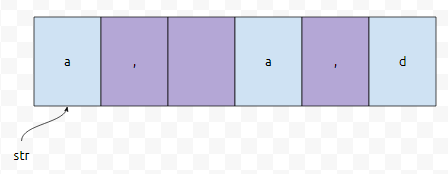
만약에 구분자가 ','와 ' '인 경우, 요런 식으로 쪼개질 수 있어요. "a", "a", "d". 아니면 "a"와 "", "a", "d" 순서로 쪼개지거나. StringTokenizer는 전자입니다. 그림을 보시면 1번째로 만나는 구분자 ','와 ' '사이에 아무것도 없음을 알 수 있는데요. 토크나이저는 그러한 경우, 토큰으로 삼지 않아요.
이제 예제 프로그램을 몇 개 봅시다.
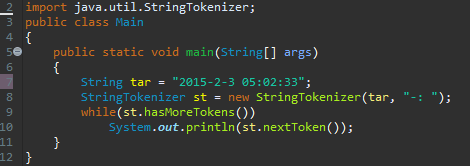
8번째 줄을 봅시다. target 문자열을 가지고, 2번째 인자에 나온, 구분자들, '-', ':', ' '을 가지고 분리하겠다는 겁니다. 보시면, hasMoreTokens 라는 메서드가 있다는 것을 알 수 있는데요. 이것은, 구분자로 인해 잘라진 토큰이 더 있는지를 검사하는 함수입니다.
만약에 있다면, 해당 토큰을 리턴해 주는 역할을 합니다. 그러면 Token은 어떻게 나올까요? "2015", "2", "3", "05", "02", "33" 이렇게 나올 건데요. 처음에 호출이 되면, "2015"가 있으니까, nextToken을 호출하면 "2015"가 나올 겁니다. 그 다음에는 "2"가 있으니까, "2"가 나올 거에요.
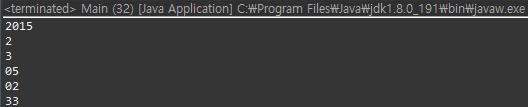
수행 결과는 다음과 같습니다.
이제 문자열을 ","을 구분자로 해서 분리해 봅시다.
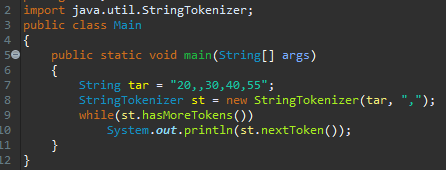
그러면 두 번째 인자에 ","을 넣어주면 됩니다. tar는 "20,,30,40,50"임을 알 수 있는데요. 1번째 ','과 2번째 ',' 사이에 아무런 문자도 없어요. 그러한 경우, 무시가 된다고 했으니, ','만을 구분자로만 끊어버리면, "20", "30", "40", "55" 순으로 나올 겁니다.
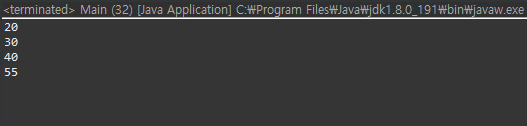
프로그램의 수행 결과는 다음과 같습니다.
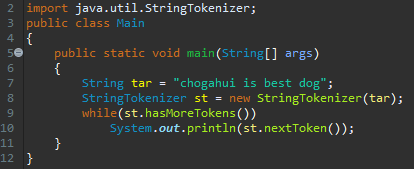
이제, StringTokenizer의 생성자에, target 문자열만 넘겨보도록 하겠습니다. 그러면 어떤 걸 기준으로 끊을까요?

내부를 보면 공백과 tab, 개행문자, '\r'과 '\f'가 보입니다. 이들을 구분자로 삼아서 끊어낸다는 것을 유추할 수 있어요. target 문자열은 이 중 공백만 있었습니다. 그러니, space 문자를 기준으로 끊어질 겁니다.
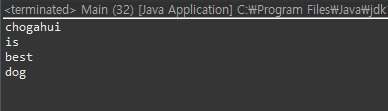
실행 결과는 위와 같습니다.
그러면 hasMoreTokens + nextToken 조합 말고 다른 방법으로 토큰을 분리할 수 있을까요?
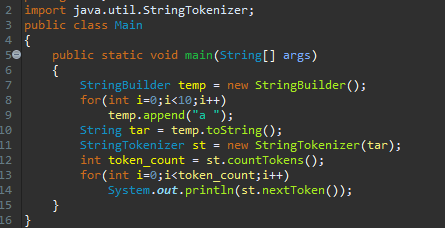
countTokens는, target 문자열의 남은 토큰수를 리턴해 줍니다. nextToken이 수행이 되면, 내부적으로 currentPosition 이라는 변수를 변화를 시키는데요. countTokens도, currentPosition부터 문자열의 끝까지 탐색하면서 토큰 수를 셉니다. 그러면, nextToken을 호출하고, countTokens를 호출하면 그 수가 줄어들겠지요.
보통, 문자열을 분리하기 전에, countxxx를 호출을 합니다. 12번째 줄에서, 공백이나, 탭 등등을 구분자로 했을 때, 분리되는 것의 갯수를 token_count에 넣어 놓았습니다. 그리고, 13번째 for문을 돌면서 nextToken으로 계속 분리된 문자열들을 리턴하고 있어요.
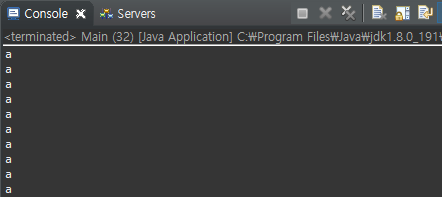
실행 결과는 a가 10번 출력되는 것입니다.
'레퍼런스 > 예제' 카테고리의 다른 글
| c언어 atoi 함수 : 문자열을 숫자로 변환한다. (6) | 2019.09.25 |
|---|---|
| c언어 strtok 함수 : 구분자를 기준으로 문자열을 자른다. (6) | 2019.09.19 |
| ctime 함수 : time_t를 우리가 알기 쉽게 문자열로 변환해준다. (6) | 2019.08.25 |
| c언어 memset : 어떠한 수들만 초기화 가능할까? (9) | 2019.08.11 |
| 반복자 무효화 : 어떠한 연산을 조심해야 할까요? (6) | 2019.08.08 |


최근댓글