이번 3회 코테에서도 어김없이 3번 문제에는 cs가 나왔습니다. 그런데, 기존 3번 문제는 골드 5로 평가되었던데 비해, 3회 3번은 얘네들보다 난이도가 높았습니다. 가희와 쓰레기 놀이는 어떤 문제였는지, 출제 목적이 무엇이였는지부터 상세하게 설명을 하면서 풀이를 작성하도록 하겠습니다.
먼저, 이 문제를 가져오게 된 계기는 그리 어렵지는 않았습니다. 이 글에서도 간접적으로 볼 수 있긴 하지만, 결정적인 계기는 logback의 MDC를 보다가 threadLocal을 보게 되었고, 그 안에 있는 WeakReference를 보게 된 것이 결정타였습니다. gc가 약하게 도달 가능한 객체들을 모두 지워야 겠다는 판단을 했을 때, finalize가 된다고 되어 있는데 이것을 구현해 보라는 목적도 있었고요. 제한을 보면 object의 id와 reference id가 1이상 10^9 이하의 정수였습니다. 이 obj_id와 ref_id가 상당히 큰 정수이므로, 이 친구를 key 값으로 받는 자료구조를 생각해야 합니다.

그런데, 이 키 값을 가지고 뭘 해야 하나요? 해당 키에 대응되는 reference, 혹은 object를 찾아야 해요. 그러면 key, value 쌍이 떠오를 겁니다. 하나 더. 키 값을 빠르게 찾아야 하나요? 그럴 필요가 있습니다. 왜냐하면, ref를 추가, 삭제하거나 obj를 추가하는 연산이 여러 번 주어지기 때문입니다. 키 값을 빠르게 찾기 위한 것은 c++의 stl에서는 map, unordered_map이 있고, java에서는 hashmap, treemap 등이 있어요.
즉, ref_id와 obj_id는 이런 친구들로 관리하면 되겠다. 라는 생각을 먼저 하셔야 합니다. 이제 다음 질문. id가 obj_id인 객체와 연결되는 관계들은 어떻게 관리를 하면 좋을까요? 예제 3을 보겠습니다.

예제 3의 경우, id가 1인 객체에서 id가 2인 객체로 여러 개의 연결 관계들이 있는 상황입니다. 그러면 id가 1인 객체가 id가 2인 객체에 여러 번 연결이 되었다고 들어올 겁니다. 어? 그러면 2에 연결되었다는 단순한 정보만 들고 있으면 될까요? 그건 아닐 겁니다. 왜냐하면, 연결 관계에는 강한 연결 관계도 있지만, 약한 연결 관계도 있을 것이기 때문입니다.
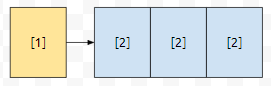
그래서 단순하게 이런 관계만 넣어주면 안 됩니다. 대신에, 2로 연결되었다는 정보 밑에 ref_id 등을 추가해서, 어느 연결 관계가 실제로 2와 연결하는지에 대한 정보를 주면 됩니다. 저는 아예 id가 1인 obj_id가 가지고 있는 연결 관계는 ref_1, ref_2, ... 다. 라고 관리하였습니다.
예제 1을 보면 1번 obj가 6번 obj로 연결되는 ref_id가 10인 연결 관계를 추가하라고 되어 있어요. 이 때, 저는 어떻게 관리를 했는가?
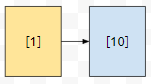
1번 object가 10번 연결 관계를 가지고 있구나를 con에 저장하였어요. 그러면, 이 10번 연결 관계에 대한 정보는 어떻게 얻어오면 될까요? 어짜피 게임 상태에서 ref_id가 같은 연결 관계가 둘 이상 있지는 않습니다.

그러므로, 간단하게 이런 식으로 자료 구조를 설계하면 됩니다. ref_id에 대응되는 것은 실제 연결 관계에 대한 정보이고, obj_id에 대응되는 것은 실제 id가 obj_id에 연결되어 있는 연결 관계 id가 어떤 것인지를 들고 있으면 됩니다. 그런데 왜 ref_set을 썼는가? 참조 관계는 수시로 추가, 삭제가 될 수 있기 때문에 그렇습니다. 제가 설명한 내용을 코드로 구현하면 아래와 같습니다.

먼저, ref는 ref_id에 대응되는 연결 관계에 대한 연관 정보를 map에 저장합니다. 다음에, map <int, set <int>> con은 obj_id에 대응되는 연결 참조 관계들을 저장합니다. 다음에 REF에는 a, b, weak가 저장되는데요. weak는 연결 관계가 강한 연결인지, 약한 연결인지 저장하기 위한 용도입니다.
아마 제가 말한 이 구조에서 하라는 대로 구현했다면, M이나 m연산을 수행 후에 다시 그래프를 재구축을 할 때, con과 ref를 다시 새롭게 구축할 겁니다. 이는 아래 코드에 나와 있습니다.

visit를 하나라도 하지 않았다면, ref에서 제거를 합니다. 그리고 ref를 재구축 했으니, 이를 토대로 con을 다시 구축해야 할 텐데요. 남은 연결 관계들과 root만을 가지고 구축을 할 수 있으므로 아래와 같이 코딩하면 그리 어렵지는 않습니다.

루트들은 모두 con에 다 넣어버리고, 살아남은 참조 관계들을 순회하면서 con에 정보를 넣어버리면 끝이기 때문입니다. 사실 bfs를 적절하게 구현하고, 정보를 rebuild 하는 부분만 구현했다면 M 연산과 m 연산의 총 합이 17 ~ 18번 정도 수행되는 테스트 케이스까지는 문제 없이 동작할 것입니다. 그리고, 이게 무리 없이 동작하면, 부분 배점이 있다면 저는 100점 만점에 70점을 주었을 겁니다.
문제는 unordered_map이나 unordered_set의 경우 rebuild를 하는 경우 상수가 매우 크기 때문에 자칫하다가는 시간 초과가 나 버릴 수도 있다는 점입니다. 제한 시간 3.5초가 생각보다 매우 빡빡했다는 의미입니다. 이는, vector insert, delete를 저격하기 위해서 어쩔 수 없이 3.5초로 설정하였는데요. 이게 M과 m연산의 최대 횟수 20번과 맞물려서 생각보다 어려워 졌을 거라 생각합니다.
왜 시간 초과가 났을까요? M과 m 연산이 수행이 될 때, 오버헤드가 걸릴 만한 곳은 ref와 con을 재구축 하는 부분과 bfs를 돌리는 부분으로 나눌 수 있는데요. bfs도 생각보다 빡빡하기 때문에, 이 상수들을 어디서 줄여야 할 지 생각해 볼 필요가 있어요. 관찰할 수 있는 핵심 키는 2가지입니다.

루트로는 항상 접근이 가능하다. 그리고 루트가 아닌 객체는 연결 관계를 통해서만 접근이 가능하다. 이 말인 즉슨, 모든 연결 관계를 bfs를 수행할 때 고려하지 않고 무시한다면, 루트를 제외한 객체는 방문할 수 없습니다. 이 말을 다시 풀어서 써 봅시다. bfs를 수행할 때 무시해야 하는 연결 관계를 marking 하는 것 만으로도 연결 관계를 삭제하는 것과 동일한 효과를 낼 수 있다는 의미입니다.
예를 들어 객체가 요래 연결 되었다고 해 보겠습니다. 그리고 1번이 루트라고 해 봅시다.
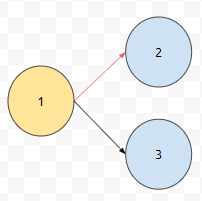
빨간색으로 표시한 연결 관계를 무시해 봅시다. 그러면 1에서 3은 방문하는데 2는 방문하지 못해요. 그런가요? 그러면 marking 과정에서 1, 3이 마크가 될 것이고, 2는 그렇지 못할 겁니다. marking 한 부분만 남긴다면 2는 제거될 겁니다. 그러면 ref_id가 추가만 되고 삭제는 되지 않는 자료구조라는 건데요. 특정 위치에 insert가 되지 않고 단순하게 어느 위치에나 insert가 되는 구조를 원해요. 키 값 삭제는 없고요. 이건 단순하게 vector와 같은 dynamic array를 이용해도 되는 부분이에요.

요런 식으로 해도 문제가 없습니다. 대신에, 삭제되었음을 marking 하는 무언가가 추가되어야 할 겁니다. 이건 어떻게 하면 좋을까요? 연결 관계나 오브젝트가 같은 시점에 둘 이상이 추가, 삭제되는 경우가 주어지지 않습니다. 그러면 같은 ref_id라도 추가되거나 제거된 시간에 따라 다르게 취급될 수 있음을 의미해요.
그러면 이런 아이디어로 접근하면 어떨까요? 건물 A가 시간 1에 건설되었어요. 시간 10에 철거되었고, 시간 13에 다시 재건축 되었다고 해 봅시다. 그러면 시간 8인 시점에, 시간 1에 건설된 건물 A는 있겠죠. 그런데 시간 14인 시점에 시간 1에 건설된 건물 A가 있을까요? 없습니다. 왜? 철거되고 재건축 되었기 때문입니다. 건물을 참조 관계에 대응시켜 볼게요.

t = 1인 시점에 id가 3인 연결 관계가 추가되었어요.

t = 10일 때, id가 3인 연결 관계를 삭제한다는 연산이 들어왔다 해 봅시다. 이 때, t = 1일 때 추가된 id = 3인 연결 관계를 삭제하는 게 아니라, 연결 관계가 무효화 되었다고 생각하면 어때요? id = 3인 연결 관계가 t = 10일 때 상태가 업데이트 되었기 때문에 더 이상 유효하지 않게 되어 버린 것입니다.
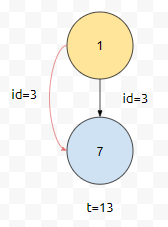
t = 13일 때 또 id가 3인 연결 관계가 추가됩니다. 이 때에는, t = 13일 때 추가된 id = 3인 연결 관계가 유효하게 되어 버립니다. 우리는 t = 1일 때 추가된 id가 3인 연결 관계를 삭제할 필요 없이 marking만 하면 되는 건데요. 이것을 어떤 기준으로 잡았나요? id가 ?인 연결 관계의 상태가 업데이트 된 시점으로 잡았습니다. 연결 관계가 추가된 시점이, 업데이트 된 시점보다 앞에 있으면, connect 관계는 valid 한 게 아니므로 무시해 버리면 됩니다.
이제, 이것을 어떻게 구현할 것인지가 문제인데요. ref_id에 대한 이벤트가 최근에 발생한 시점은 unordered_map 하나로 관리할 수 있어요. delete 연산이나 add 연산이 일어날 때 마다 업데이트가 되면 되겠죠. 이걸 코드로 구현해 봅시다.

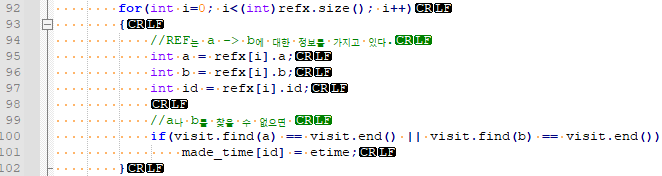
REF 정보에 made_time이라는 메타 데이터를 추가하면 됩니다. 이는 실제 연결 관계가 어느 시점에 만들어졌는지를 저장합니다. 이것을 어디에 쓸까요? M이나 m연산이 일어날 때 마다 연결 관계 탐색 조건으로 쓰기 위함입니다.

79번째 줄을 봅시다. 탐색 조건에서 made_time[ref_item.id] > ref_item.made_time 이 조건을 쓰는데요. 이는 특정 레퍼런스가 추가된 시점보다, 최근에 상태가 바뀐 시점이 더 뒤에 있다면 valid 하지 않다고 판단하고 무시하는 로직입니다. 그러면, con을 재구축 하는 것도 그리 어렵지 않습니다.
단순하게, a에서 b로 연결하는 간선이 객체들이 정리되어서 invalid 하다고 판단되면 made_time을 업데이트 하면 됩니다.
이 아이디어대로 구현하면 fast io 없이 맞았습니다를 볼 수 있습니다. 제가 설명한 코드들은 여기서 보실 수 있어요. 이 글에서 언급된 것 말고 최적화를 통해서 최종적으로 맞은 코드는 여기서 보실 수 있습니다.
'자료알고 > 알고리즘' 카테고리의 다른 글
| 가희와 프로세스 2 : 관점을 바꾸어서 이분 탐색을 적용해 봅시다. (0) | 2022.02.21 |
|---|---|
| 백준에서 자주 보이는 절대 오차 상대 오차에 대해 간단하게 알아봅시다. (0) | 2022.01.31 |
| bfs나 dfs에서 component를 왜 구하는지 알아보고 응용해 봅시다. (0) | 2022.01.24 |
| 가희와 비행기 문제를 카탈란 수로 구해 봅시다. (0) | 2022.01.06 |
| 롯데 자이언츠와 가희 : 벤다이어그램을 그려서 도식화 시켜 봅시다. (0) | 2021.11.24 |


최근댓글