리스트와 배열의 차이점은 면접에서 자주 나오는 질문 중에 하나입니다. 저에게 메일로 질문이 들어온 것 중 하나는, 순회 속도가 어떻게 차이가 나느냐였습니다. n이 작을 때는 별 차이가 없을 수도 있습니다. 하지만 n이 3000 ~ 4000만 정도만 되도 이야기가 달라집니다. 배열은 순차적으로 저장이 되지만, 리스트는 그렇지 않습니다. cache를 이용하기 좋은 구조는 리스트보다 배열이라는 겁니다. 정말 그런지 실험을 해 봅시다.
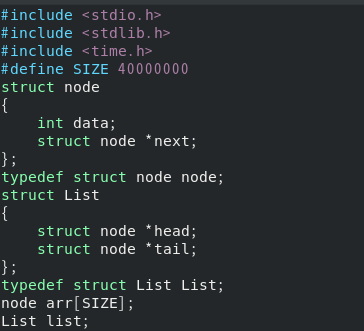
배열과 링크드 리스트의 순회 성능 테스트를 위한 코드를 작성해 봅시다. node형을 하나 선언해 주었는데요. data 필드와, 다음 주소를 가리킬 필드를 선언해 주었습니다. 단일 링크드 리스트는 포인터가 1개, 더블은 2개일 거에요. C++의 리스트는 더블로 구현이 되어 있습니다. 즉, 제가 선언한 node보다는 필드가 최소한 1개 더 많다는 소리가 되겠습니다.
SIZE는 4천만으로 해 놓았는데요. 적당히 500만 정도만 해 놓아도 무난합니다.

그 다음에, clock 함수를 이용해서, list 순회하는 시간과, 배열 순회하는 시간을 측정하였습니다. 그 결과는 list는 얼마나 걸렸고, array는 얼마나 걸렸는지 출력해 주고 있습니다.

그리고, 저는 List에서 삭제를 하지 않을 거기 때문에, 리스트의 맨 뒤에다가만 추가하는 연산을 수행했습니다. 만약에 list의 head가 NULL값이라면, 아직 리스트에 아무것도 없는 것이므로, head와 tail을 업데이트 해 주었습니다. 그렇지 않다면, 새롭게 공간을 할당해 준 다음에, tail과 new를 연결합니다. 그리고 tail을 new로 갱신해 버렸습니다.
그러면, 뒤에다가만 원소를 추가하는 연산은 쉽게 구현할 수 있습니다.
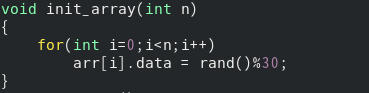
이에 비해서 배열은 훨씬 간단합니다. 그냥 arr[i]의 data 필드에 값만 넣으면 되기 때문입니다. 그러면 순회하는 연산은 어떻게 구현하면 좋을까요?

연결 리스트는 간단합니다. 그냥, 현재 위치가 NULL이 아닐 때 까지만 계속 돌면 됩니다. 배열은 그냥 n개만큼 돌면 되고요. 겉으로 보이는 연산 차이는 그렇게 많이 없어 보입니다.

그런데, 시간 차이를 보면, list보다 array가 상대적으로 더 빨랐음을 알 수 있어요. 여기서 우리는 배열을 전체 순회했을 때 평균 시간만 볼 건데요. 평균적으로, 0.015723초 걸렸습니다. 그런데, 보통 배열에 data를 넣을 때, 다음 원소의 위치가 어디인지는 넣지 않을 겁니다. 필요가 없기 때문입니다. arr을 node형이 아닌, int형으로 바꿔 봅시다.

그러면 프로그램의 두 함수를 바꿔야 할 겁니다. 일단 arr[i].data에 대입하는 것이 아니라 arr[i]에 rand()%30의 값을 넣어야 할 거에요. 그리고 배열을 순회하고, 특정한 값을 더할 때도 마찬가지입니다.

arr[i].data를 더하는 게 아니라, arr[i]를 더하면 되겠습니다.
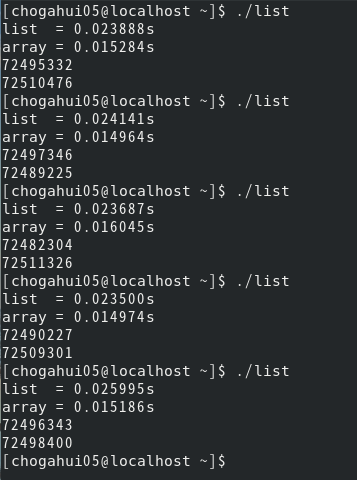
이렇게 프로그램을 바꾸고 다시 실행시켜 봅시다. 평균 수행 시간이 0.015290초로, 수행 시간이 약 3% 가량 감소했습니다. 이 차이 또한 무시 못합니다. 보통 c++의 list는 싱글이 아닌 더블로 구현이 되어 있어요. 즉, 원소를 가리키기 위한 필드가 제가 선언한 node형보다는 많이 차지할 거에요. 그러면 필요한 공간도 상대적으로 더 많아질 거고요.
또한 list의 순회 시간과 array의 순회 시간을 비교해보면, 후자가 압도적으로 더 빠르다는 것을 알 수 있어요.
배열은 연속적으로 저장이 되어 있습니다.
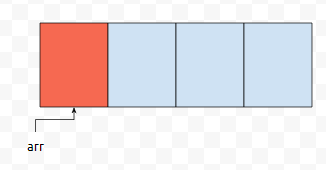
즉 배열의 시작 주소랑, 원소 1개가 차지하는 메모리 size만 알면, arr[i]의 주솟값 또한 매우 쉽게 알 수 있습니다. 예를 들어서, arr의 시작 주소가 0x80이였다고 해 보고, 원소 1개가 차지하는 메모리 크기가 4byte였다고 해 봅시다. 그러면, arr[0]의 주소는 0x80일 겁니다. arr[2]의 주소는 어떻게 계산이 될까요? 0x80 + 4*2 = 0x88, 이런 식으로 계산이 될 거에요.
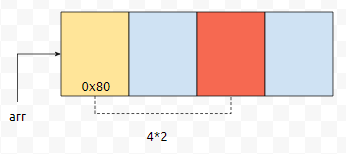
그렇기 때문에 random 접근이 O(1)에 가능합니다. 또한 이전 원소와 현재 원소가 메모리 상으로 인접해 있고, 현재 원소와 다음 원소 또한 메모리 상에 인접해 있어요. 즉, 서로 가까이 있습니다. 그렇기 때문에, cache를 잘 쓸 수 있는 구조입니다. 반면에 링크드 리스트는 그렇지 않아요.

메모리 상에 연속적으로 저장이 되어 있지 않아요. 즉, 현재 원소의 위치가 0x0080번지에 있었는데, 다음 원소의 위치는 0x1000번지에 있을 수도 있다는 겁니다. 그러니, 랜덤 접근도 안 됩니다. 지역성이 배열보다 상대적으로 좋을까요? 지역성의 원리란, 한 번 참조된 데이터는 다시 참조될 가능성이 높고, 주변에 있는 데이터 또한 다시 참조될 가능성이 높다는 원리입니다.
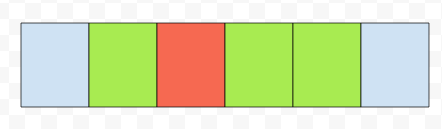
그렇다면, 인접한 영역까지 캐시에 끌어 올릴 건데요. 예를 들어서 2번째 원소를 읽었다고 해 봅시다. 그리고 인접한 영역, 그러니까 초록색으로 칠한 부분까지 캐시로 끌고 왔다고 해 봅시다.

그러면, 3번째, 4번째 원소를 읽을 때, 굳이 메모리까지 접근을 할 필요가 없을 겁니다. 이미 캐시에 저장이 되어 있기 때문입니다. 배열은 연속적이기 때문에, 가능합니다. 하지만 List는 어떤가요? 대충 List가 이런 식으로 연결이 되어 있다고 해 봅시다.

초록색 부분까지 cache로 끌고 왔다고 해 봅시다. 빨간색 부분을 읽었습니다. 그리고 next로 갔습니다. 빨간색으로 칠한 원소의 다음 원소는, 캐시에 저장이 되어 있나요? 아닙니다. 그렇기 때문에, 다시 읽어와야 할 겁니다. 연속적이지 않기 때문에, 상대적으로 배열에 비해서 순회 연산이 오래 걸리는 셈입니다. 거기에 필드값도 더 많다면, 공간마저 많이 쓸 겁니다.
배열보다 순회 연산이 오래 걸릴 수 밖에 없겠네요.
'자료알고 > 자료구조' 카테고리의 다른 글
| 올바른 괄호 문자열 검사하기 : 스택으로 손쉽게 해결해 보자. (2) | 2019.07.20 |
|---|---|
| 자료구조 스택 : 먼저 넣은 것이 나중에 빠진다. (12) | 2019.07.18 |
| 하노이탑 알고리즘 : 재귀 호출의 대표적인 문제를 구현해 봅시다. (5) | 2019.07.12 |
| 재귀 함수 : 자기 자신을 호출한다. (2) | 2019.07.08 |
| 동적 배열 : expand 연산을 이해하는 것이 핵심이다. (0) | 2019.06.23 |


최근댓글