이번 시간에는 cut 명령어에 대해서 간단하게 알아보겠습니다.

먼저, 어떤 파일인 거 같나요? 유저 이름이 나오고, /usr/sbin/nologin 같은 것이 나오는 걸로 보아서는, /etc/passwd의 내용으로 보입니다. 여기서 우리는 유저 네임만 뽑아내려고 합니다. 유저 이름은 1번째 필드이고, : 을 구분자로 구분되어 있습니다.
옵션 하나. -d는 델리미터를 의미합니다. 토큰을 구분지을 때, 구분짓는 것을 의미합니다. 둘 이상일 때에는, awk를 쓰는 것이 하나의 방법인 듯 싶어요. 이에 대해서는 awk 명령어 포스팅에서 언급을 드린 바가 있습니다. 옵션 둘. -f는 필드를 의미합니다. 구분자로 구분된 구획이 있을 텐데요. 몇 번째 구역을 출력할 것인가를 나타냅니다.
예를 들어서, /etc/passwd가 구분자 :로 구분이 되었다면, kibana x 129 135 ... 이런 식으로 나뉠 텐데, 이 중 1번째 구획은 kibana를 의미합니다. 그러면, 우리는 :을 구분자로 구분하고, 1번째 구획을 출력하면, 유저들만을 출력하게 됩니다. 한 번 입력해 봅시다.

cut -d ':' -f 1. 제가 말한 내용을 그대로 수행한 것 뿐입니다. 다음에, :로 구분된 것 중 7번째 필드는 쉘을 의미합니다. 로그인 쉘.

그러면 유저 명하고, 로그인 쉘을 출력해 보도록 하겠습니다. 7번째 필드도 출력한다면, 1, 7 이렇게 넣어주면 됩니다. 아. 그런데, 출력할 때도 :를 구분자로 보여집니다. 이걸 다른 문자로 바꿀 수 없을까요?

--output-delimiter 옵션은 아웃풋 델리미터를 설정합니다. 위에서 저는 출력 구분자를 ' '로 설정했는데요. 설정 안 했을 때에는 root:/usr/bin/zsh 이렇게 출력되던 것이, root /usr/bin/zsh 요래 출력되었습니다. cut -d와 이것과 많이 쓰일법한 -f 정도는 익혀두시는 게 좋겠습니다.
이제, 다음 실습을 진행해 보겠습니다.

-s 옵션은, delimiters가 포함되어 있지 않으면, line을 출력하지 않는다고 되어 있습니다. 이게 무슨 소리인지 사실 잘 모르겠습니다. 그러니, 테스트 케이스를 하나 만들어 보겠습니다.

in.txt는 위와 같습니다. :를 구분자로 되어 있는데 mola, 즉 3번째 라인만 : 구분자가 없습니다.

1, 3번째 필드만 취해보도록 하겠습니다. 그러면, 1, 2, 4번째 줄은 정상적으로 나옵니다. 그런데, 3번째 줄은 mola만 나옵니다. 이러한 결과를 제외하고 싶습니다. 이 경우에 -s 옵션을 넣어주면 됩니다. 아마도 동작은 1번째나, 3번째 필드가 없는 경우에 무시된다거나, 혹은, 결과값에 :가 없다면 무시된다일 겁니다. 왠지 man 페이지만 보면 전자일 듯 싶긴 하지만..
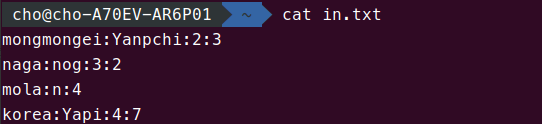
필드를 몇 개 더 추가하고, 1, 2, 4번째 필드를 뽑게 해 보겠습니다.

그러면 요래 나옵니다. 4번째 필드가 비어 있지만, :라는 구분자가 있기 때문에 그냥 나와버렸습니다. 결과값에 델리미터가 없으면 필터링 되는 게 맞나 보군요. 하튼 mola:n과 같이 특정 필드가 비어 있는 것은 어떻게 필터링을 해야 할까요? cut만 써서는 힘들 거 같은데. 사실, 이런 것을 필터링 하기 쉬운 방법 중 하나는, cut으로 뽑아놓고, grep을 이용해서 또 필터링을 하는 것입니다. 저는 우분투를 쓰니 /etc/groups을 가지고 실습해 보겠습니다.

둘 이상의 유저가 속해있는 모든 그룹들을 출력해야 합니다. 어떻게 하면 좋을까요?

일단 1, 4 필드만 뽑아놓으면 전체가 나올 겁니다. -s 옵션을 붙여도 마찬가지라면 끔찍하겠군요. 그런데, 그룹에 있는 유저가 둘 이상이 아니라면, 4번째 필드는 비어 있을 겁니다. 그 말인 즉슨 :로 끝난다는 이야기입니다. :로 끝나지 않고, 중간에 :가 있다면, 다음과 같은 패턴을 써서 걸러내도 됩니다.

:. 이것은 : 다음에 아무 문자나 와도 된다는 것을 의미합니다. 이렇게 해서 걸러내도 무난합니다. 다음에, 걸러낸 내용들 중에서 :로 구분했을 때 1번째 필드만 뽑아내면 되므로, 아래와 같이 명령어를 입력하시면 됩니다.
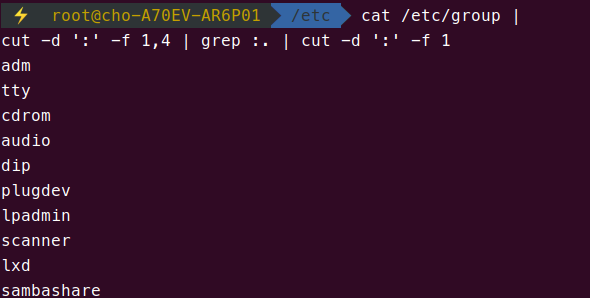
어렵지 않죠? 그런데, /etc/group 파일의 특성을 이용하면, 이 긴 명령어를 줄일 수 있는 방법도 있습니다. 이건 조금만 더 생각해 봅시다. 어렵지 않으니까요.
이제, 이런 경우를 생각해 보겠습니다.

구분자가 여러 개입니다. :이나 공백이라고 합시다. 이 때 1번째 필드와 3번째 필드를 뽑아야 합니다. 어떻게 해야 할까요? cut을 써야 할까요? 사실, 무조건 이 명령어만 써야 한다. 이렇게 생각하실 필요는 없습니다. 왜냐하면, 이미 awk 명령어를 할 때 이와 비슷한 문제를 접했기 때문입니다.

단지, -F 옵션을 주고, "[: ]+"을 주면, :와 ' '을 구분자로 돌립니다. 그리고 +까지 입력했으니, :나 ' '이 하나 혹은 여러개 오는 패턴을 구분자로 인식을 합니다. 그리고 '{print $1" "$3}' 을 하면 1번째 필드와 3번째 필드를 출력합니다.

바이트 단위로 끊어버리는 거는 -b를 주면 됩니다. 주의해야 할 것은 한글이 있을 때, cut -b 2-2 in.txt 이런 식으로 주면 깨질 수도 있다는 것입니다. 1byte로 표시되는 문자가 아닌 경우에는 주의해야 합니다. 그런데, 우리는 이런 텍스트 파일에서 4번째 문자에서 6번째 문자까지를 출력하고 싶습니다. 이건 또 어떻게 해야 할까요? 아. 이런 거 진짜 바이트를 세가지고. 할 수도 없는 노릇이고 말입니다. 크헝헝. 사실, 이런 질문이 올라오긴 했지만. 다른 방법을 쓰는 게 솔직히 더 좋을 듯 싶습니다.
grep으로 필터링 걸겠습니다. 정규식에서 ^은 시작을 의미합니다. 그리고 {n}은 정확히 n번 반복을 의미합니다. 그러면 matching 되는 것만 출력하게 하는 옵션만 보면 되겠네요.

grep에서 매치되는 것만 출력하는 것은 -o입니다.

그러면, 먼저 앞에서부터 6개를 뽑아낸 결과에다가, 다시, 뒤에서 3개의 결과를 뽑아내면 됩니다. 그러면 정확히 4번째 문자부터 6번째 문자까지를 뽑아내게 됩니다. grep 명령어 안에 -o 옵션을 썼다는 것에 주목하시면 되겠습니다.
'OS > 리눅스' 카테고리의 다른 글
| 리눅스 head 명령어 : 파일의 앞부분을 출력한다. (2) | 2020.11.18 |
|---|---|
| 리눅스 grep -i를 이용해서 대소문자 구분 없이 패턴을 찾아 봅시다. (0) | 2020.10.15 |
| 터미널을 꾸미기 위해 유용하게 썼던 리눅스 cp -rp 명령어 (0) | 2020.09.19 |
| 리눅스 kill 명령어 : 프로세스에 시그널을 보낸다. (0) | 2020.09.10 |
| 리눅스 awk 명령어 : 원하는 컬럼을 출력한다. (0) | 2020.09.06 |


최근댓글