정규표현식 중에 (?=...), (?!...)와 같이 쓰는 패턴이 있습니다. 정규표현식에서 lookahead라고 하는데요. 간단하게 알아보겠습니다.
이 패턴으로 어떻게 기준이 잡히는지부터 보는 것이 빠르겠네요.

(?=foo)f 패턴을 보겠습니다. foofoofoofoofoof를 입력했을 때, 패턴이 어떻게 매치되는지부터 보겠습니다.

1번째부터 5번째 f까지 잡히고, 6번째 f는 match가 되지 않음을 알 수 있어요. 왜? (?=foo)만 입력했을 때 어떻게 기준이 잡히나 보겠습니다.

1번째 f 앞에 기준선이 있습니다. 2, 3, 4, 5번째 f 앞에도 기준선이 있습니다. 그런데, 6번째 f 앞에는 없습니다. 어떤 기준으로 잡히는 것일까요? foo라는 패턴 앞에 기준선이 붙어요. 1, 2, 3, 4, 5번째 f 앞에 있는 기준선부터 보면, foo라는 패턴이 따라 붙음을 알 수 있어요.

2번째 f를 기준으로 보면, f 다음에 oo가 붙어서 foo 패턴이 들어왔습니다. 제가 선택한 부분입니다. 5번째 f도 마찬가지로 보면 foo가 있음을 알 수 있는데요. 6번째 f는 그냥 f만 붙어 있어요. foo 패턴이 전혀 아닙니다. 따라서, 기준이 잡히지 않아요. 이제 (?=foo)f는 제가 찾은 5개의 기준선들 부터 시작했을 때, f라는 패턴이 나오는지를 match 하는데요.
기준선이 5개가 있었어요. 1, 2, 3, 4, 5번째 f 앞에. 이 기준선들로부터 시작했을 때, 패턴이 일치하는지 찾는데요. 찾는 방향이 위 그림과 같습니다.

보면 1번째 기준선에서 시작했을 때 1번째 화살표 방향으로 찾아요. foof... 로 이어지는데요. 이미 f가 있네요? 따라서 f가 하나 매치됩니다. 2번째 기준선에서 시작했을 때에도 마찬가지입니다. foof... 로 이어지는데 f라는 패턴을 찾았네요. 이런 식으로 생각하면, 5개의 f가 매치됨을 알 수 있어요.
이제 (?![a-z])를 입력해 보겠습니다. =과 달리 !은 일치하지 않음을 의미합니다. (?![a-z])이므로, 대소문자가 아닌 패턴을 의미합니다. 기준선들이 어디에 잡힐까요?

1 앞에 하나가 잡히고 맨 끝에 하나가 잡힙니다. 1 앞에 기준선이 잡히는 것은 이해가 됩니다. 그런데, 맨 끝에 잡히는 건 뭘까요? 맨 뒤에 있는 a에는 아무 문자도 없습니다. [a-z] 패턴, 즉 소문자가 하나 나오는 패턴과 일치하지 않아요. 따라서, 맨 끝에 있는 a 뒤에도 기준선이 잡히게 됩니다.
a(?![a-z])를 입력해 보겠습니다.

기준선 앞에 a라는 패턴이 왔기 때문에, 1 앞에 있는 것과, 맨 끝에 있는 a 앞에 있는 것이 패턴 a와 일치하는지 찾습니다. 둘 다 일치하기 때문에 2개가 match 됨을 볼 수 있어요. 즉, 제가 찾은 2개의 기준선 바로 앞에 있는 것이 a라는 패턴과 일치하는지 찾는데요. 이제 다소 복잡한 예제를 봅시다.

이건 어떨까요? 뭔가 복잡해 보이는데요. (?![a-z]).*(?=[a-z])입니다. 일단, (?![a-z]).*부터 봅시다.

먼저 앞에 (?![a-z])가 온 상황입니다. 이 경우, 기준선들은 알파벳 대소문자가 아닌 패턴인 1 앞에 잡힙니다. 그 다음에 .*가 왔으니, 기준선들로부터 greedy하게 매치하게 될 겁니다. 그래서 (?![a-z]).*만 입력하면 1aaaa 전체가 매치가 될 겁니다. 그런데, 뒤에 (?=[a-z])가 왔습니다. 이는 대소문자 패턴 앞에, .*가 와야 한다는 의미입니다. 1번째 (?![a-z])이 기준선이 1 앞에 있었으니 1부터 match가 되기 시작할 텐데요. "1aaaa"까지 보자니, 뒤에 딸려오는 패턴이 알파벳이 아닙니다. 따라서 "1aaa"를 보는데요. 이 때에는 뒤에 딸려오는 패턴이 "a"이기 때문에 "1aaa" 까지만 match 됩니다.

더 쉽게 말하면, (?![a-z])와 .*의 후행으로 오는 (?=[a-z])에 매치되는 기준선 2가 요래 있는데, 기준선 1은 1 앞에 있었습니다.

그러니, 1 뒤에 있는 기준선 4개 중에 어느 기준선 앞까지 갈지 고를텐데요. .*은 greedy하기 때문에, 맨 뒤에 있는 친구를 고를 겁니다. 따라서 "1aaa"가 매치됩니다. 반대로 (?![a-z]).*?(?=[a-z])의 경우에는 어떻게 매치되는지 직접 생각해 보시면 좋겠습니다.
이제 조금 어렵습니다. 이건 무엇을 의미할까요? (?=a)(?=1). 뭔가 어려워 보이네요. 차근차근 볼까요?

aaaaaaaaaa111aaaaaaaaaa패턴을 생각해 봅시다. (?=a)는 기준선을 어떻게 잡나요?
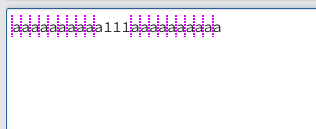
요래 잡습니다. (?=a)a에서 뒤에 a는 기준선으로부터 문자 하나가 a인지를 봅니다. 만약에 일치하면, match가 되겠죠?

이 때 문자가 하나 소모됩니다. 다음에 (?=1)가 들어오면 1이라는 패턴이 있는지를 보는데요. 일단 1번째 기준선에서 문자 하나를 소비하면 2번째 기준선입니다. 2번째 기준선은 a...a 패턴으로 이어지니까 아예 match가 되지 않죠.

대신에, 10번째 a의 앞을 기준선으로 삼아봅시다. 이것도 기준선 뒤에 a가 있으니, a가 하나 소비됩니다. 그 뒤에는 1이 있으니, 당연하게도 match가 됩니다. 그러면 (?=a)(?=1)이 무엇일까요? (?=a)a(?=1)과 다르게 문자가 소비되지 않았습니다. 고로 아래와 같이 검사가 됩니다.

먼저 (?=a)가 옵니다. 기준선은 분홍색으로 표시되어 있습니다. 문자가 하나도 소비되지 않았으니, (?=1)을 검사할 때에도 같은 기준선을 기준으로 검사하게 되는데요.

(?=a)와 매치되는 기준선들이 (?=1)과 매치되지는 않습니다. (?=.*[1])(?=.*[a])는 어떨까요? 먼저 (?=.*[1])을 봅시다.

.*[1] 패턴, 아무 문자가 0개 이상 나온 다음에 1이 나오는 패턴이 기준선 뒤에 옵니다. 다음에 소비된 문자가 없고 다시 (?=.*[a])가 옵니다. 이는, 아무 문자가 0개 이상 나온 다음에 a가 나오는 패턴이 같은 기준선 뒤에 온다는 의미입니다. 분홍색으로 표시된 것 중 해당 패턴을 만족하는 케이스들을 봅시다.

만족합니다. 모든 기준선이 이 조건을 만족하기 때문에, (?=.*[1])(?=.*[a]) 뒤에 오는 패턴은, 분홍색 기준선으로부터 match 시키게 됩니다.
'REGEX' 카테고리의 다른 글
| 정규표현식 lookbehind에 대해 알아봅시다. (0) | 2022.11.03 |
|---|---|
| regex lazy quantifier에 대해 간단하게 알아봅시다. (0) | 2022.10.29 |
| notepad++ regex group capture를 이용해서 데이터 가공 해 봅시다. (0) | 2021.07.23 |


최근댓글