파이썬에서 sorted는 꽤 많이 쓰는 함수 중 하나입니다. 어떻게 쓰는지 간단하게 알아봅시다. 이 문서를 보고 오시면 더 좋습니다.
먼저, 정수를 정렬해 봅시다. 정렬할 때에는 보통 리스트를 많이 씁니다.

리스트는 iterable 하므로, 정렬 가능합니다. sorted(arr)을 한 결과를 출력해 보겠습니다.

그러면 2, 3, 3이 나옵니다.
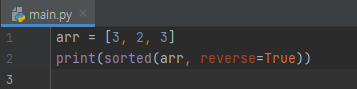
역순으로 정렬할 수 없을까요? 할 수 있습니다. reverse 옵션을 True로 주면 됩니다.

실행 결과는 위와 같습니다.
키를 설정하는 것을 많이 쓰는데요. 이것을 람다로 퉁칠 수 있습니다. 예를 들어 보겠습니다.

먼저, pair의 1번째 요소를 기준으로 정렬한다면, lambda tu : tu[1]로 주면 됩니다. 단지, 이것은 키 (1, 2)에서 1번째 원소인 2를 꺼내오는 역할을 합니다. 이것을 키 값으로 삼을 겁니다.

실행 결과는 위와 같습니다. 그런데, 우리는 pair의 1번째 요소를 오름차순으로, 1번째 요소가 같다면 0번째 요소 오름차순으로 정렬하고자 합니다. 어떻게 하면 좋을까요?

튜플로 만들어 버리면 됩니다. 1번째 정렬 기준인 tu[1]을 먼저, tu[0]을 2번째에 올렸습니다.

실행 결과는 위와 같습니다. 여러 정렬 기준을 적용할 때, 튜플은 생각보다 유용한 구조라는 것만 기억해 두시면 됩니다. 이제, 1번째 요소는 오름차순으로, 1번째 요소가 같다면, 0번째 요소는 내림차순으로 정렬하게 하려면 어떻게 해야 할까요? 정수는 음수만 붙이면 크기 순서가 완전히 바뀌어 버림을 이용하시면 됩니다.

2번째 줄에서 -tu[0]을 주목해 보세요. 앞에 -를 붙인 이유는 내림차순으로 정렬해야 하기 때문입니다.

결과는 위와 같습니다.
이 내용을 이용해서 풀 수 있는 문제인 1181번을 풀어보겠습니다. 문자열을 정렬하려는데, 길이 오름차순, 길이가 같다면 사전 순으로 정렬하라고 하였습니다.
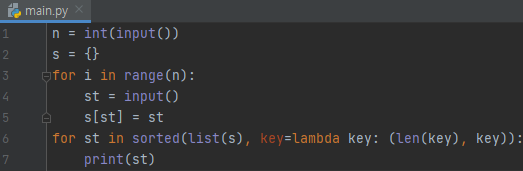
그러면 1번째 기준이 len(key)이고, 2번째 기준이 key라고 말할 수 있습니다. 이것을 pair로 묶었다는 것을 알 수 있습니다. 중복 제거를 위해서, dict를 썼고, 6번째 줄에서 dict를 list로 변환하는 작업을 같이 하였습니다.
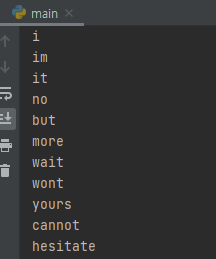
잘 정렬이 됨을 알 수 있습니다. 이 코드를 그대로 제출하면 맞았습니다를 받을 수 있습니다. lambda만을 이용해서, 2번째 정렬 기준이 사전순 역순이 되게 하는 것은 더 생각해 봅시다.
이럴 때, 제가 많이 쓰는 방법은, 커스텀 클래스를 따로 만드는 것입니다. 아래 예제를 보겠습니다.
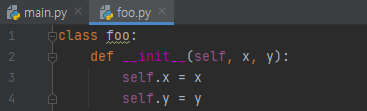
저는 x와 y를 담고 있는 클래스 foo를 만들었습니다.
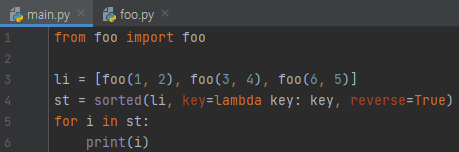
정렬을 시켜 보겠습니다.
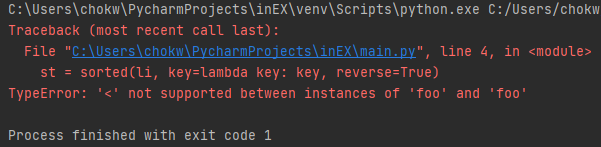
그러면, <가 not supported라고 뜨는데요. 두 키를 비교하는 연산자가 정의 되어 있지 않다는 것입니다. 그러면, 클래스 안에서 < 역할을 하는 메서드를 정의하면 되겠네요.
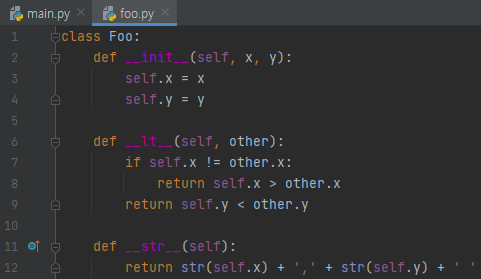
x는 string을, y는 int를 받습니다. 그리고, __lt__ 는 self와 other를 비교해서, self가 other보다 앞서야 하는지를 판단하게 되는데요. c++의 STL에서 < 연산자라 생각하시면 됩니다. self.x가 other.x보다 크다는 것은, self.x가 other.x보다 사전순으로 뒤에 있다는 것입니다. 즉, 1번째 기준은 x가 사전 순으로 뒤에 있는 것부터 sort가 되겠네요.
다음에, 이 둘이 사전 순으로 같다면, self.y와 other.y를 비교하게 되는데요. 이 둘을 비교했을 때, self.y가 더 작으면 앞에 올 겁니다. 즉, 2번째 기준은 y 오름차순이 됩니다. 그리고 __str__을 재정의 해서, 객체의 정보를 출력하게끔 하였습니다.
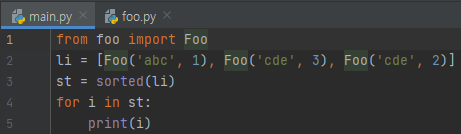
실제로 그렇게 정렬이 되는지 볼까요?
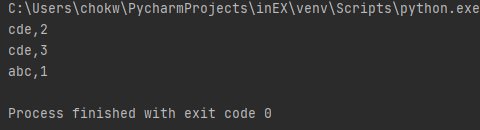
의도한 대로 잘 정렬이 되었음을 알 수 있습니다.
'코딩 > 파이선' 카테고리의 다른 글
| 파이썬 삼항 연산자 : 간단한 조건 판단에 쓰면 유용하다. (0) | 2021.03.18 |
|---|---|
| 알아두면 편한 파이썬 f-string 기능을 알아봅시다. (2) | 2021.03.10 |
| 파이썬 filter : 배열에서 추출할 때 많이 쓴다. (2) | 2021.02.26 |
| 파이썬 로또 프로그램을 sample 함수를 이용해서 만들어 봅시다. (0) | 2021.02.19 |
| python range 함수 : for 문과 같이 많이 쓰인다. (0) | 2021.02.15 |


최근댓글