알고리즘에, 정렬 시리즈를 계속 올리고 있습니다. C언어에서도, 손쉽게 빠른 정렬을 쓸 수 있는데요. <stdlib.h>에 빠른 정렬을 하는 qsort 함수가 있습니다. 이것의 원형은 다음과 같습니다.
void qsort(void *base, size_t num, size_t size, int (*compare)(const void *,const void *));
뭔가 원형이 복잡해 보이는데요. 특히 4번째 인자가 조금 복잡해 보입니다. 이게 무엇인지 천천히 해석해 보겠습니다. 먼저 identifier를 찾을 건데요. compare입니다. 오른쪽부터 볼 건데요. (나 )를 만날 때 까지 읽어요. compare 뒤에 바로 )가 있으니까, 왼쪽을 봅니다. 보는데 *가 있네요. 즉, compare is pointer라는 겁니다. 무슨 포인터인가요?
오른쪽에 보니까, (...)가 있어요. 이건 함수라는 뜻이에요. 무슨 함수에요? void형 포인터를 2개 받는. 다시 왼쪽을 보면, int를 리턴하는 녀석이라는 거죠. 즉, void형 포인터를 2개 받아서, int형을 리턴하는 compare 함수를 작성해야 한다는 소리가 되겠어요. 이건, 비교 기준을 재정의 하는 것이라고 생각하시면 좋겠습니다.
int compare(const void *p1, const void *p2);
비교 함수는 다음과 같습니다. p1과 p2를 받아서, int형을 리턴하는데, p1이 p2보다 우선 순위가 앞서면 음수를, p1이 p2보다 우선 순위가 떨어진다면 양수를, 같으면 0을 리턴해야 합니다. 쉽게 말해, priority가 1인 것은 5인 것보다 중요도가 높다. 정도로 해석하시면 손쉽게 암기 가능합니다.
그러면 qsort 함수의 4번째 인자로 넘겨줄 compare을 어떻게 작성해야 하는지 보아야 하겠다는 것이에요. 백준 1181번 단어 정렬은 길이가 짧은 것이 우선순위가 높고, 길이가 같다면, 사전순으로 앞선 것이 우선순위가 높습니다. 그리고 중복 또한 제거해서 출력하라고 했습니다.

moo 레코드를 void 포인터인 a가 가리키고 있습니다. 그러면, 일단 a를 (moo *), 그러니까 moo를 가리키는 포인터 형으로 강제 형변환을 해야 합니다. 그러면, (moo *)a; 라고 쓰면 되겠습니다. 그런데, 실제 객체에 들어 있는 값을 가져오려면 어떻게 하면 좋을까요? 둘 중 하나입니다. 그 중 한 방법은 아래와 같습니다.

a를 역참조하면, 어떻게 되나요? 실제 객체의 주소를 참조하니까, real 값을 가지고 올 수 있게 될 겁니다. *(moo *)a를 하면 되겠죠. 포인터를 배우신지 얼마 안 되셨다면 단계별로 차근차근 코드를 작성하시는 게 좋습니다.

27번째 줄, 28번째 줄의 패턴은 반드시 외워두세요. 외우시고 이해하세요. 일단, 길이 오름차순으로 정렬하려면 어떻게 하면 좋을까요? 레코드 a에 대한 것은 real_a가 가지고 있고, 레코드 b에 대한 것은 real_b가 가지고 있습니다. 그러면 len_a - len_b가 음수라면 어떤가요? 앞의 것이 뒤의 것보다 우선 순위가 높은 것이고, 양수라면, 앞의 것이 뒤의 것보다 priority가 낮은 거겠네요.
만약에 반대로, 길이가 긴 순으로 정렬을 해야 한다면 어떻게 해야 할까요? 이 때에는 len_a>len_b인 경우, 음수가 리턴이, len_a<len_b인 경우 양수가 리턴이 되어야 할 겁니다. 즉, len_a - len_b의 값에 (-1)을 곱한 값을 리턴해 주면 됩니다.

그런데, 길이 값이 같은 경우에는 어떻게 될까요? 이 때 우선 순위가 같기 때문에 순서가 정의되지 않습니다. 문제에서는 길이가 짧은 순대로, 길이가 같다면 사전순으로 정렬하라고 했어요. strcmp(a,b)는 a가 b보다 사전순으로 앞서면 음수를 리턴합니다.

따라서, len_a != len_b일 때에는 len_a - len_b의 값을 리턴하고, 그렇지 않다면, 두 녀석의 길이가 같은 것이니까, 33번째 줄을 추가해 주시면 되겠습니다. compare 함수 작성이 끝났습니다.
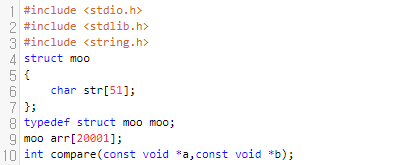
길이는 2만개라고 했으니, moo 배열의 길이는 20001개쯤 두면 될 겁니다.

16번째 줄을 자세히 보세요. n+1개를 sorting 했습니다. 첫 데이터에 빈 문자열을 넣었는데요. 이것은 dummy 데이터입니다. ""은 길이가 0이기 때문에, 어떠한 경우라도, 문제에서 입력되는 문자열보다 우선순위가 앞섭니다. 그래서, 일부러 저리 넣었습니다.
qsort 함수의 1번째 인자는 정렬을 시작할 위치, 2번째는, 몇 개를 정렬할 건지, 3번째는 정렬 레코드의 크기, 4번째는 비교 함수를 각각 넣엊우면 됩니다. 이 부분 그리 어렵지 않아요. 다음에, 17번째 for문 블록을 보면 i가 1일 때부터 n일 때까지 도는데요.
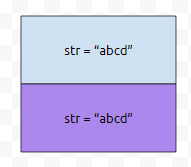
현재 검사하고 있는 문자열과, 이전에 검사하고 있는 문자열이 같다면, 현재 위치에 있는 문자열은 출력하지 않고 넘어갑니다. 이는 중복을 출력하지 않는 방법 중 하나입니다. 이러한 원리를 이용해서, STL의 unique() 함수를 구현할 수 있다는 것 정도는 알고 넘어가시면 좋겠습니다.
이번에는 n명이 주어지는데요. 나이가 적은 사람이 우선 순위가 높습니다. 만약에 나이가 같다면 먼저 등록한 순서대로 출력해야 하는데, 이것은 입력에 들어온 순서와 같습니다. 놀랍게도 qsort는 stable sort가 아니기 때문에, 새로운 정렬기준을 하나 만들어야 합니다.
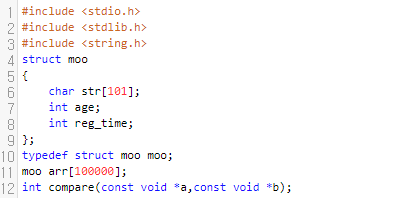
저는 그 기준을 reg_time으로 잡았습니다. 등록된 시간입니다. 만약에, merge_sort와 같이 stable_sort였다면, 이러한 기준을 만들 필요가 없었을 겁니다. 왜냐하면, 우선순위가 같은 데이터 A, B가 정렬 전에, A, B 순서대로 있었다면, 정렬 후에도 A, B 순으로 있다는 것이 보장되기 때문입니다.
그렇지만 quick은 그렇지 않습니다. 따라서, reg_time이라는 새로운 기준을 두는 겁니다.
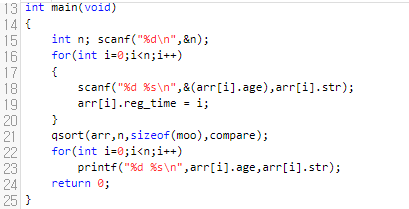
19번째 줄에, arr[i].reg_time에 i를 넣는 게 보이실 겁니다. 그러면 1번째 기준이 age, 2번째 기준이 time이에요.

그러면, compare 함수는 아래와 같이 작성하면 됩니다. age_a와 age_b가 다르다면, age_a - age_b의 값을 리턴합니다. 만약에 이 값이 음수라면 a가 b보다 우선 순위가 앞선다는 건데요. 이 때, age_a < age_b입니다. 그러니 만족합니다. 다음, 둘이 같다면 a의 reg_time - b의 reg_time 값을 돌려주면 됩니다.
'레퍼런스 > 예제' 카테고리의 다른 글
| c언어 memset : 어떠한 수들만 초기화 가능할까? (9) | 2019.08.11 |
|---|---|
| 반복자 무효화 : 어떠한 연산을 조심해야 할까요? (6) | 2019.08.08 |
| C언어 문자열 복사 : strcpy 함수를 이용해 봅시다. (4) | 2019.08.03 |
| C언어 문자열 비교 : strcmp 함수로 손쉽게 슥삭~ (2) | 2019.07.29 |
| mktime : struct tm 구조체를 time_t로 변환한다. (4) | 2019.07.28 |


최근댓글