이전에 저는 2개의 필드를 가지는 구조체를 custom 하게 정렬하거나 비교할 때, < 연산자를 구현한 적이 많았습니다. 예전에 제가 ps를 할 때는 그랬습니다. 생각이 바뀐 것은 python의 tuple을 맛보고 난 후였습니다. c++에도 tuple이 있는데요. 백준에서 문제를 풀기 위해 이 정도만 알아도 되겠다 싶은 것들만 작성해 보겠습니다.
tuple을 다룰 때에는 3가지만 알면 됩니다. i번째 필드 얻어 오기, i번째 필드 바꾸기, 새로 생성하기. 이 2가지를 먼저 알려드린 다음에 프로세스와 가희 문제에서 어떻게 적용될 수 있는지 보여드리겠습니다. 예제를 보면서 이해해 보도록 하겠습니다.
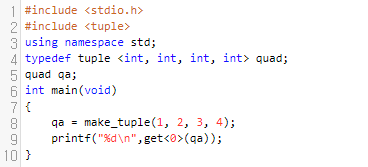
먼저, 새로 생성하는 것은 make_tuple로 하시면 됩니다. 8번째 줄을 수행하면, 대략적으로 요래 올라갈 겁니다..

여기서 0번째는 1, 1번째는 2, 2번째는 3, 3번째는 4가 들어간 상황입니다. 여기서 0번째 원소인 1을 가지고 오려고 합니다. 몇 번째, 인덱스가 주어진 경우에는 get<index>(tuple_obj)로 꺼내올 수 있어요. qa에 1, 2, 3, 4가 저장되어 있고 0번째 원소를 꺼내오려고 하므로, index는 0이 되고, tuple_obj는 qa가 됩니다. 따라서, get<0>(qa)로 가지고 오시면 됩니다.
그러면 1을 가지고 오게 됩니다. 실행 결과는 아래와 같습니다.

의도했던 대로 나왔음을 알 수 있습니다. 정확하게 말하자면, get 메서드는 레퍼런스를 리턴한다고 문서에서 언급하고 있습니다. 그렇다면, i번째 원소를 t로 set 하기 위해서는 어떻게 하면 될까요? 원래 tuple에 1, 2, 3, 4가 저장이 되어 있었는데요. 5, 2, 3, 4로 바꾸기 위해서는 <0>의 alias에 5를 넣는다는 코드를 작성하시면 됩니다.

아래와 같이 코딩하면 되겠군요.
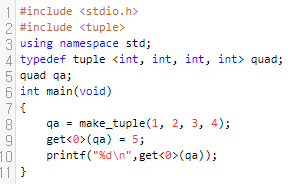
9번째 줄이 핵심입니다. 이제 실행 결과를 볼까요?

5가 나왔음을 알 수 있어요. 가희와 프로세스 문제는 이것만 알아도 해결을 할 수 있습니다.
이제 가희와 프로세스 문제를 풀어 봅시다. id, 시간, 우선 순위가 주어집니다. 필드가 3개 주어집니다. 그런데, 저는 처음에 tuple은 각 필드가 비교 가능하다면, 정렬 연산자를 오버라이딩 할 필요가 없다고 하였습니다. 필드가 모두 비교 가능하다고 가정해 봅시다. 그러면 튜플은 아래와 같은 로직으로 비교합니다.
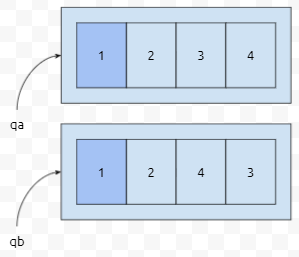
먼저 0번째 원소끼리 비교합니다. 1과 1이므로 같네요. 다음으로 넘어갑니다.
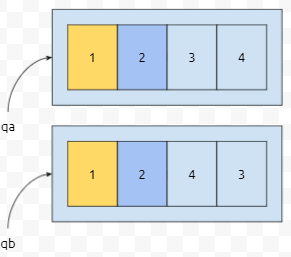
1번째 원소를 비교합니다. 2와 2. 역시 같네요. 다음으로 넘어갑니다.
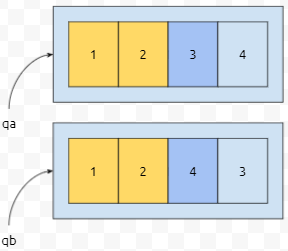
2번째 원소를 비교합니다. 3과 4. qa의 3번째 원소가 qb의 3번째 원소보다 작으므로, qa < qb입니다. int만 들어갔다면 요런 식으로 비교하게 됩니다. 마치, 문자열 compare 비교하는 것 처럼 동작하신다고 보시면 됩니다. 가희와 프로세스 문제에서는 우선 순위가 높은 것이 우선하고, 그것이 같다면 id 오름차순으로 우선한다고 되어 있으므로, (우선순위, id, 시간)으로 tuple을 만들어야 합니다.
문제는, priority queue가 기본적으로 a가 b보다 크다면, b가 rank가 높은 걸로 동작합니다. 그러면 우선 순위는 그대로 넣으면 됩니다. 그런데, id는 어떻게 해야 할까요? 작은 게 먼저 오게 하려면 id 값에 -1을 하면 됩니다.

13번째 줄에 어떻게 넣었는지 보시면 됩니다. id가 모두 다르기 때문에, (prio, id)쌍도 모두 다르다는 것을 보장할 수 있어요.

프로세스를 1초 실행시킨 후에 어떻게 데이터를 업데이트 하면 될까요? 이것도 간단해요. 실행 시킨 프로세스의 우선 순위를 하나 감소시키고, 실행 시간을 하나 감소시켜서 다시 넣어버리면 됨을 알 수 있어요. 19번째 줄에서 그러한 일을 수행합니다.
'레퍼런스 > 예제' 카테고리의 다른 글
| java string repeat 메서드로 쉽게 문자열을 반복해 봅시다. (1) | 2021.07.11 |
|---|---|
| java arrays binarysearch 함수를 알아봅시다. (4) | 2021.07.07 |
| c++ multiple delimeters에 대해 tokenize를 regex를 이용해서 해 봅시다. (0) | 2021.06.18 |
| c++ find 메서드로 multiple delimiter일 때 string을 분리해 봅시다. (0) | 2021.05.31 |
| 파이썬 randint randrange : 랜덤하게 수를 뽑을 때 쓴다. (0) | 2021.05.17 |


최근댓글