수많은 데이터를 한꺼번에 추가하려면 어떻게 해야 할까요? 특히 queryset의 성능을 실험할 때 거대한 데이터를 넣어야 할 일이 의외로 있는데요. 매 루프마다 create를 호출하면 상당히 느릴 겁니다. 이 때, 쓸 수 있는 것은 bulk_create입니다. 말 그대로, 일정 묶음 단위로 추가를 할 수 있습니다. 자세한 것은 문서를 보시면 되겠습니다.
이 글에서는 간단하게 bulk_create가 무엇인지 정도만 짚고 넘어갑니다.
예제의 모델들은 아래와 같이 정의되어 있습니다.

먼저 Profile의 user는 django의 기본 모델인 User의 fk입니다. 다음에 blocked는 block 유저를 관리하기 위한 m2m field입니다. 실제로 postgres 디비에는 block 유저를 관리하는 mapping 테이블이 존재합니다.
post는 포스트의 내용을 담는 post와 owner가 있습니다. 이 owner는 Profile을 참조하는 fk입니다. 대략적으로 그림이 그려지시리라 믿습니다.
먼저, 2000개의 포스트를 일일히 Post.objects.create로 생성해 보겠습니다.
gen 함수는 20자 길이의 랜덤한 내용을 생성합니다. 생성 후에, "1"번이라는 이름을 가진 user의 Profile이 생성한 포스트의 갯수를 세어 봅시다. Profile이 User의 어딘가를 참조하고, Post가 Profile의 어딘가를 참조하고, 유저 이름은 User에 있기 때문에 쿼리가 다소 복잡합니다.
이너 조인을 2번 태웠습니다. 유저 1명당 프로필은 1개이고, 프로필 1개당 게시물은 n개이니, 저리 써도 큰 문제는 없을 겁니다.
index 함수를 호출 후, count는 2000이 찍혔습니다.
이제, bulk_create를 이용해서 2000개의 포스트를 한 번에 찍어보겠습니다. new_post_list를 어떻게 생성했는지 주목하시면 되겠습니다. 2000번의 루프를 돌 동안, Post 정보들을 생성합니다. 보면 owner는 profile이고, post는 gen()이라 되어 있네요? 이는 post 내용은 랜덤하게 찍힌 내용이고, 포스트를 쓴 사람은 username이 "1"인 프로필을 의미합니다.
이렇게 생성된 리스트를 bulk_create의 인자로 넘겨주면 됩니다.
다시 "1"번이 생성한 포스트의 수를 보면 4000이라고 되어 있습니다.
그러면, 성능 차이가 얼마나 발생했을까요?
왼쪽은 bulk_create를 이용했을 때, 오른쪽은 일일히 for loop 안에 Post.objects.create를 이용한 결과입니다. 전자가 후자보다 압도적으로 빨랐음을 알 수 있습니다. 이는 create를 한 번 수행할 때 마다 걸리는 오버헤드를 무시하지 못하기 때문입니다. db에 연결해야 되는 오버헤드라던지, lock을 걸고 푸는 것 등이 있을 텐데, 이러한 연산들이 결코 가볍지 않음을 의미해요.

이 결과는 20000개의 포스트를 생성했을 때의 성능 차이입니다. 아까보다 더 극단적으로 나타났음을 볼 수 있어요. 왼쪽은 2.28초, 오른쪽은 22초. 쿼리 1번을 날릴 때 숨겨진 추가 비용이 생각보다 크다는 의미도 되겠네요. 다만, 문서에 언급된 대로 post_save와 같은 signal이 동작하지 않고, save() 메소드가 호출되지 않는 등 제약 사항이 있다는 점을 유의하시면 되겠습니다.
한 가지 예제 더 보여드리겠습니다. m2m field에서 bulk_create를 어떻게 써야 할까요? 쉬운 방법 중 하나는 through를 이용해서 접근하는 것입니다. 예를 들어 1번이 악성 유저라서 운영자가 수동으로 모든 유저에게 1번 유저를 악성 유저로 추가한 상황을 생각해 봅시다. 유저 수가 20만명이라고 하면 어떨까요? 생각보다 상당히 오래 걸립니다.
profile의 blocked가 m2m이기 때문에, m2m model에 접근할 수 있는 방법이 있다면, bulk create를 하는 데 크게 어려움이 없어 보입니다.

먼저 "1"이라는 이름을 가진 user를 뽑습니다. 이건 20번째 줄에서 하고 있습니다. 그리고, "1"이라는 이름을 가진 유저의 프로필을 뽑는데요. 이것은 21번째 줄에서 하고 있어요. 다음에 not_profile은 "1"이 아닌 유저들의 프로필을 모두 뽑습니다. 이제 우리는 이 정보들을 가지고 block 관련 정보들을 만들 건데요.
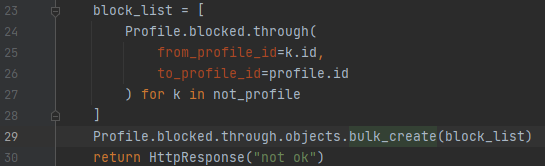
다른 유저들이 1번을 차단한 그림입니다. 1번은 profile.id이고, 다른 유저들은 not_profile에 있는 k.id로 표현이 될 수 있어요. 여기서 저는 from을 block 하는 사람이라고 정의했습니다. to는 block을 당하는 사람이라고 정의했고요. 그렇기 때문에 25번째 줄에서 from_profile_id는 k.id를 넣었습니다. to_profile_id는 profile.id를 넣었어요. 왜 from_profile_id, to_profile_id인지는 이 문서를 보시면 되겠습니다.
이제, 넣어야 되는 block_list가 얻어졌다면, m2m field로 직접 접근해서 bulk_create를 날려주면 됩니다. 이는 29번째 줄에서 수행합니다. 총 유저의 수는 12500명이고, 이 중 1건에 대해서는 block을 하지 않으니 block m2m table이 쿼리를 수행하기 전에 비어 있었다면, 수행 후에 12499건이 나와야 할 겁니다.
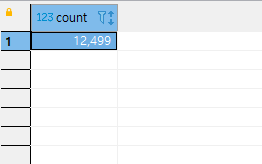
정말 그럴까요? 그런지 확인해 보니 12500에서 한 건이 빠진 12499가 나왔습니다.

'웹 > 장고' 카테고리의 다른 글
| django admin의 list_filter를 알아보고 간단하게 적용해 봅시다. (0) | 2022.11.12 |
|---|---|
| django search_fields에 대해 예제와 함께 알아봅시다. (0) | 2022.11.07 |
| django m2m field filter 를 through로 접근해서 걸어봅시다. (0) | 2022.09.28 |
| django set_password 함수에 대해 알아봅시다. (0) | 2022.09.12 |
| django 복잡한 filter 조건 연결할 때 Q object 를 이용해 봅시다. (0) | 2022.09.06 |

최근댓글