Java의 char형은 어떻게 표현이 될까요? Character 클래스에 BYTES 라는 필드가 있는데요. 이 값은 char형 변수가 바이트를 얼마나 쓰는지 나타냅니다.

이 값을 출력해 봅시다.

2가 나와요. 기본적으로 16bit 유니코드 인코딩을 쓰고 있다는 건데요. 이제 이 친구가 어떤 식으로 값을 저장하는지 알아보도록 하겠습니다. '가'라는 문자를 집어 넣어보겠습니다.
'가'는 유니코드로 U+AC00에 맵핑이 됩니다.

그러면, ch를 int형으로 변환하여 출력하면, 유니코드가 어떠한 형식으로 디코딩 된 결과를 출력할 겁니다. Integer 클래스 안에 있는 toHexString은 16진수의 문자열로 출력해주는 함수입니다.

봤더니 16진수로 ac00으로 출력이 되었어요. 이 값은 0000에서 ffff 사이의 값인데요. 이것을 기본 다국어 평면이라고 해요. 이 사이에 포함된 값은 유니코드 값 그대로 인코딩이 되어요. 당연하게도 이것을 utf-8로 인코딩을 했다면, 이 값이 출력이 되지 않을 거에요.

utf8은 기본적으로 가변 길이 인코딩이에요. 0부터 127까지, 그러니까 아스키 코드로 표현이 가능한 것들은 1byte를 차지합니다. 그리고, 128부터 2047까지의 코드값은 2바이트로 표현이 됩니다.

형식은 대략 이러합니다. 그리고, 2048부터 65535까지는 요렇게 표현이 됩니다.

U+AC00은, 이 영역에 포함됩니다. Hex로 AC00인 것을 utf-8형식으로 인코딩을 하면 아래와 같을 거에요.

이걸 차례대로 넣으면 2진수로 11101010 10110000 10000000이 되는데, 이걸 4비트씩 끊으면 ea b0 80이 됩니다. 만약에 기본적으로 UTF8이였다면 이 값이 튀어나왔을 거에요. 그런데 0xac00이 나왔고, 사이즈가 2였습니다. 그러면, 기본적으로 UTF 16으로 인코딩이 된다는 겁니다. 이는 Charater 클래스에도 설명이 잘 나와 있습니다.
그러면, 2byte로 표현이 가능한 0x0000부터 0xffff까지는 2바이트로 표현이 될 거에요. 그렇지 않은 경우도 있을 거에요. 예를 들어 높은음자리표는 U+1D11E로 표현이 되는데요. 이것은 0xffff를 초과하는 숫자입니다. 그렇기 때문에 2바이트에 깡으로 저장하지는 못하고, 더 큰 공간에 넣어야 할 건데요.
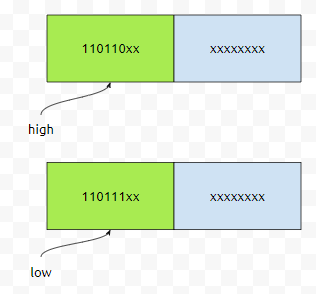
상위 서러게이트랑, 하위 서러게이트로 나눠서 저장합니다. 그러면 U+D800부터 U+DFFF, 그러니까 D8 평면부터, DF 평면까지 유니코드는, 쓰이지 않겠네요. 서러게이트로 써야 하기 때문에. 예를 들어, 높은음 자리표는 U+1D11E로 표현이 되는데요. 이를 2진수로 끊어서 표현하면, 다음과 같이 쓸 수 있습니다.
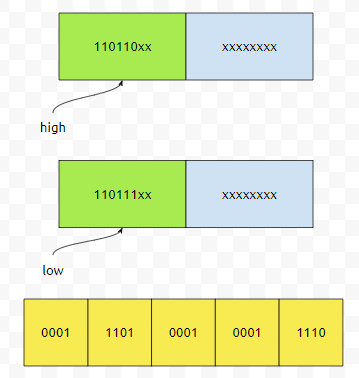
그러면 이것을 적절히 잘 넣어주기 전에 0x10000을 뺍시다. 그러면 맨 앞에 4자리가 0000이 될 거에요.

여기서 0x10000을 빼 줍니다. 그러면 보라색이 될 거고, 이것을 high와 low 서러게이트에 넣으면 위와 같습니다. 이것을 4비트씩 끊어서 16진수로 출력하면 D834 DD1E가 됩니다. 간혹 가다 Character형을 뜯다 보면 surrogate가 나오는데, 이런 것 때문에 나온다고 이해하셔도 좋겠습니다.
다음에 getByte()도 같이 언급하면서 계속 이야기 해 보도록 하겠습니다.
'코딩 > Java' 카테고리의 다른 글
| java string intern 메서드 : pool이 된다는 것만 기억합시다. (2) | 2019.08.08 |
|---|---|
| cp949 vs euc-kr : 어떤 차이점이 있는지 간단히 알아봅시다. (0) | 2019.08.04 |
| java 참조 타입 vs 기본 타입 : 어떤 값을 저장하는가? (4) | 2019.08.03 |
| getBytes : String을 어떻게 인코딩하고 디코딩 할까? (0) | 2019.07.31 |
| 얕은 복사 vs 깊은 복사 : 참조가 복사되는가? 내용이 복사되는가? (12) | 2019.07.18 |


최근댓글