가희배 5회 코딩테스트가 4월 2일에 열렸습니다. 제가 플레 이상으로 예측한 문제도 있었지만, 골드 정도로 예측했는데 실제로 까 보니 플레였던 문제가 있었습니다. 그 문제에 이어서 또 당한 셈인데요. 이 문제가 어려웠던 이유는 2가지가 있습니다. 카카오 기출 문제를 3개나 섞었다. 그리고, 이 문제에 jpop 이랑 kpop이 상당히 많이 들어가면서 지문 자체가 어마어마하게 길었다. 이 2가지가 있겠습니다. 이것은 가희와 코드도 마찬가지입니다.
후자는 사전 지식이 없으면 해석하는 데 시간이 구현시간보다 더 걸렸을거고 전자는 구현량이 생각보다 있었습니다.
문제에서 요구하는 것은 2가지입니다. lru, 가장 가까운 cache 찾기, 엄청나게 긴 지문과 이상하게 jpop과 kpop이 들어간 예제 해석. 이 중 lru 부분은 클래스로 따로 빼서 구현해야 겠다는 생각은 하셨을 겁니다. 그리고 Java의 Collection에는 LinkedHashMap이 있습니다.

여기서, accessOrder의 설명을 봅시다. ordering mode를 의미한다고 되어 있어요. 만약에 이 값이 true면 AfterNodeAccess, 즉 접근하고 난 후 노드 처리를 하는 메서드와, AfterNodeInsertion, 노드를 추가하고 난 후의 처리를 하는 메서드를 호출하게 됩니다. 이 클래스의 공식 문서를 뒤져가면서 찾아보면 removeEldestEntry 메서드가 있어요.
오늘은 이것을 볼 거에요.

요렇게 씁니다. LinkedHashMap을 생성할 때, accessOrder를 true로 주었습니다. capacity는 용량을 의미해요. 84번째 줄부터 86번째 줄까지를 보면 return size() > capacity; 를 볼 수 있는데요. 이건 또 무엇인가? 일단 size가 capacity보다 크면 true를 리턴합니다.
이 메서드가 true를 리턴하는가, false를 리턴하는가에 따라서 무언가에 쓰이게 될 겁니다.

AfterNodeInsertion을 봅시다. 그러면 evict이고 first가 NULL이 아니면서, removeEldestEntry(first)가 나옵니다. 이 3개의 조건이 참이면, 처음 원소를 remove 하게 됩니다. 그런데 저는 removeEldestEntry 메서드를 size() > capacity인지를 검사했단 말입니다.

이 메서드의 결과가 참이라면 가장 앞에 있는 원소를 제거해 버립니다. 그렇지 않으면 제거되지 않습니다. 여기서 정리할 수 있는 것은 2가지입니다. 아. Link로 연결된 것에서 head를 제거하는구나. 그러면 tail은 늦게 제거되겠구나. 그리고 특정 조건을 만족하면 꽉 찼으니, 제일 오래된 것을 제거하는 로직을 태우는데요. 그 기준을 정해주는 것이 removeEldestEntry가 되겠습니다.
하나 질문. 추가될 때에는 뒤에 tail에 추가되긴 할 텐데요.
tail에 추가되는 부분은 afterNodeInsertion에서 수행되지는 않습니다. 그러면 언제 수행되는가? putVal에서 newNode를 호출하는 시점에서 수행됩니다.

putVal 메소드를 잘 보면 newNode를 생성하는 부분이 있습니다. 이 부분을 디버그 하면서 따라들어가다 보면, LinkHashMap의 linkNodeLast 메서드를 부르고 있음을 알 수 있습니다.

로직을 보면, 그냥 맨 끝에 추가함을 알 수 있습니다. 그냥 tail에 새로 추가한 것을 넣어주고, 기존의 last와 p를 연결합니다.

노란색이 새로 추가된 것입니다.

그러면 접근을 한 것에 대해서는 어떻게 처리될까요? 당연하게도, 노드에 접근해서 맨 뒤로 밀어버릴 겁니다. e가 어디로 밀어지는지 보면 되겠는데요. 310번 줄에서 p = e, 가 있으므로, p가 어디로 가는지 보면 되겠습니다.
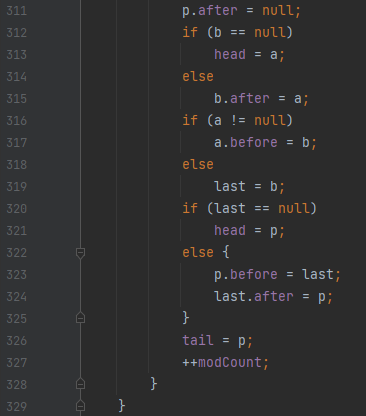
이것 저것 뚝딱한 다음에 tail = p가 되어 있습니다.
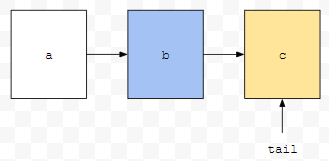
a, b, c로 연결된 상태에서 b에 접근했습니다. 그러면 어떻게 동작할까요? b를 제거합니다.
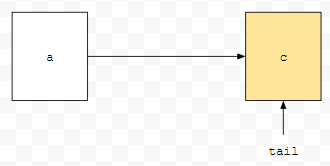
다음에 어떻게 해야 할까요? b를 tail에 추가하면 되겠네요.
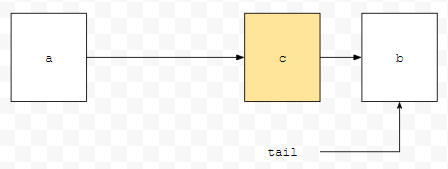
이 과정을 수행하면 b가 맨 뒤로 가게 됩니다. 그림에서는 단일 링크드로 표현하였지만, 실제로는 before와 after가 있는 이중 링크드 리스트로 구현되어 있습니다. 결국, afterNodeXXX 메서드로 특정한 일을 수행한 후에 추가적으로 해야 할 일을 호출하게 됩니다. 추가를 할 때 용량이 꽉 찬 경우에 삭제하는 로직이 필요하고, 순서를 유지하는 것이 필요합니다. LinkedHashMap은 들어온 순서를 저장하고 있어요. 그리고 용량이 꽉 찬 경우에 삭제하기 위해서 removeEldestEntry를 구현했습니다.
이 둘을 잘 버무리면 복잡한 문제를 보다 단순화 시킬 수 있습니다.
'자료알고 > 자료구조' 카테고리의 다른 글
| java treemap compareto나 compare만 구현했을 때 제대로 동작할까요? (0) | 2023.05.11 |
|---|---|
| java stack 클래스와 대체해서 쓸 만한 arraydeque를 간단히 알아봅시다. (0) | 2023.02.28 |
| heap 자료구조에 build를 어떻게 linear time에 끝낼까요? (2) | 2021.10.13 |
| 펜윅 트리 (fenwick tree) : 구간합을 빠르게 구한다. (0) | 2021.03.14 |
| java map find key in value : 2개의 맵을 씁시다. (0) | 2021.01.28 |


최근댓글