안녕하세요. 이번 시간에는 postgresql에서 쓰는 string_agg 함수에 대해 간단하게 알아보겠습니다. 그리고 정렬하는 것과 중복 제거하는 것도 같이 알아볼게요.
먼저, string_agg는 컬럼의 값들을 하나의 string으로 합쳐주는 역할을 합니다. 입력으로 들어오는 row의 속성들을 하나의 string으로 합칠 때 쓰입니다. 이게 무슨 말인가? 예제를 하나 보겠습니다.

temp_data를 with 절로 정의했어요. 속성 t의 값이 'a'인 것과, t의 값이 'b'인 것과, 'Z'인 것을 union한 결과를 temp_data로 정의했어요. 이제, temp_data에 있는 내용을 출력해 봅시다.

'c', 'b', 'Z', 'b'가 나옵니다. 이제 이것을 string_agg로 합쳐 보겠습니다.

temp_data의 t의 모든 값들을 합치는데요. 2번째 인자는 delimeter입니다. 구분자를 의미해요. 결과를 볼까요?
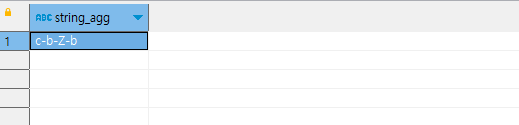
c-b-Z-b가 나옵니다. temp_data에는 레코드들의 속성 t가 'c', 'b', 'Z', 'b' 순으로 있었는데요. 이것이 aggreate가 되면서, 'c-b-Z-b'가 되어버린 것입니다.
이제, distinct와 order by를 알아봅시다. string_agg에서 input row가 들어올 때, 중복된 것들을 제외할 수도 있습니다. 그리고 우리가 원하는 대로 ordering 또한 할 수 있습니다. 간단하게 알아볼게요.

먼저 distinct입니다. 입력 row의 속성 t는 'c', 'b', 'Z', 'b'입니다. 여기서 'b'가 2번 나왔어요. 이것을 제거해서, 'b', 'c', 'Z'만 나오게 하고 싶어요. 그러면 어떻게 하면 되느냐. 그냥 1번째 인자에, distinct t를 써 주면 됩니다. 속성 t에 대해서 중복을 제거하겠다는 의미입니다. 결과가 어떻게 나오는지 보겠습니다.
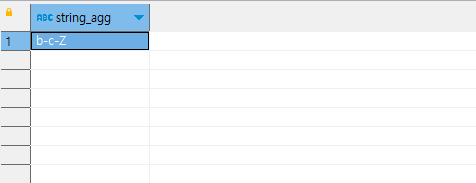
b-c-Z가 나옵니다. 아까 중복 처리를 해 주지 않았을 때에는 c-b-Z-b가 나오던 것과 대조적이지요. 그런데 말이지요. 어떨 땐 c가 먼저 나오기도 하고 어떨 땐 b가 먼저 나오기도 해요. 이것은 order 순서가 없기 때문에 그러해요. 결과가 어떻게 나올지 모르지요. 이 경우, order by를 해서 ordering을 지정해 줄 수도 있습니다.

2번째 인자에 '-' order by t desc가 있습니다. 이는, 들어오는 row의 속성 t 값을 내림차순으로 정렬하라는 의미입니다. 대신에 앞에 중복을 제거하는 distinct가 없으니까, b가 2번 나오겠지요?

결과는 Z-c-b-b가 나옵니다. 이제 중복 제거와 정렬을 같이 적용해 봅시다.

string_agg(distinct t, '-' order by t desc) 요래 입력해 보겠습니다. 그러면 이건, 입력이 들어오는 row들의 속성 t에 대해서 중복을 제거해 주면서, t값에 대해 내림차순 정렬을 합니다. 그러면 Z-c-b가 나오게 됩니다.

Z-c-b가 잘 나왔음을 알 수 있습니다. 이걸 조금 더 응용한다면, 랜덤한 문자열을 뽑을 때도 유용하게 사용할 수 있습니다.
'코딩 > Sql' 카테고리의 다른 글
| postgresql trunc 함수를 알아봅시다. (18) | 2023.06.27 |
|---|---|
| postgresql with 여러개 선언해서 사용하는 방법을 알아봅시다. (1) | 2023.06.12 |
| postgresql 어제 날짜 내일 날짜 구하는 방법을 알아봅시다. (1) | 2023.05.24 |
| postgresql materialized view와 view의 차이가 무엇인지 알아봅시다. (1) | 2023.05.13 |
| dbeaver 테이블 내보내기 불러오기 하는 방법을 알아봅시다. (0) | 2023.03.21 |


최근댓글