제 코딩테스트 레포가 업데이트 되었습니다. stream 관련한 것도 있었고, 굳이 리스트 안에 있는 원소 갯수를 세는데 리스트 컴프리헨션에 len을 섞을 필요가 있냐는 피드백도 받았기 때문입니다.

예제 프로그램을 보겠습니다. 제 예전 21771번 풀이 코드는 요런 식이였습니다. 변경 이력을 봐도 알 수 있습니다. 무엇을 하는 것이냐면, 리스트 lt에서 k가 1인 것만 filtering을 해서 새로운 리스트를 만들고, 그 리스트에 있는 원소의 수를 세서 1의 갯수를 세는 것입니다.
결과는 3이 나옵니다. 의도한 대로 나왔으니 틀린 것은 아닙니다만, 문득 의문이 듭니다. 리스트 안에서 1의 개수를 세기 위해서 논리적으로 저렇게 많은 일이 필요할까요? 이 부분은 사실 잘 모르겠습니다. 대신에, 리스트에 있는 원소 k의 개수를 센다. 는 어떤가요? 아까와는 다르게 논리가 장황하게 돌지 않고 보다 명확해 보입니다. 그러한 일을 하는 함수는 count 입니다.
이렇게 작성하셔도 똑같은 결과가 나옵니다. 그래서, 리스트 내에서 원소 a의 개수를 단순히 세고만 싶다면, list의 count를 이용하시면 됩니다.
그래서, 바꾼 21771번 코드는 이렇습니다. R개의 입력을 받는데요. P의 개수를 세는 로직이 바뀌었음을 알 수 있어요. 이전에는 그냥 입력으로 받은 리스트에서 'P'만 필터링을 해서 새로운 리스트를 만든 다음에 len 함수를 이용해서 새롭게 만든 리스트의 길이를 구했습니다. 그런데, 단순하게 'P'의 개수만 세는 것이였기 때문에, count를 이용하였습니다.
그런데 조심해야 할 부분이 있습니다. list에서 count는 생각보다 효율적이지는 않습니다. 당연한 이야기일 수도 있지만, 뒤죽박죽 원소가 있는 상황에서, a가 몇 개나 있는지를 찾으려면, 시작 위치부터 끝 위치까지 다 탐색을 해 봐야 하기 때문입니다.
이 예제는 리스트의 크기를 변화시켜가면서, r개의 수에 대해, 해당 수가 리스트에 몇 번 등장하는지를 세는 코드입니다. 그리고, 그 연산을 수행하는 데 걸린 시간을 측정합니다.
결과를 보면, 데이터의 크기가 4배 커지면 실행 시간이 16배나 뻥튀기 됨을 알 수 있어요. 정리하면, list에서 count를 꽤 많이 호출하면 매우 비효율적일 수도 있다는 것입니다. 그러면 어떻게 해야 할까요? Counter를 이용하면 됩니다.
리스트를 Counter의 생성자의 인자에 넣어버리면, 리스트에 있는 아이템들이 몇 번 나오는지 빈도를 저장해 버립니다. 이 프로그램은, 1부터 5까지 리스트에서 몇 번 나오는지를 세어 주는 프로그램인데요. counter에 저장된 내용은 수와 몇 번 나오는지에 대한 빈도입니다.
실행해 보니, 2, 1, 1, 1, 2가 나왔는데요. 이는 1과 5가 2번 등장했기 때문입니다.
그런 고로, 아이템들이 등장하는 횟수를 Counter에 저장해 두고 써 먹으면 더 효율적입니다. 실행 결과만 보겠습니다.
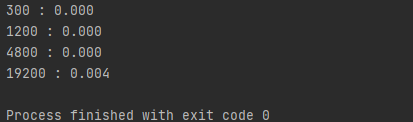
그랬더니 아까와는 다르게 19200개의 원소가 리스트에 있는 상황에서 k가 리스트에서 몇 번 나오는지 빈도를 19200번 묻는 것에 대해서도 꽤 적은 시간이 걸린다는 것을 알 수 있습니다. 다만, 그러한 연산이 많이 일어나지 않을 때에는 리스트 내에서 원소의 개수를 찾는 count 함수를 써도 큰 문제는 없습니다.

'레퍼런스 > 예제' 카테고리의 다른 글
| 파이썬 any all 함수를 어떻게 사용하는지 간단히 알아봅시다. (0) | 2022.04.08 |
|---|---|
| java map set에 특정한 원소들이 모두 있는지 containsAll 메소드로 확인해 봅시다. (0) | 2022.04.03 |
| python choices 함수의 weights와 cum_weights 사용법을 알아봅시다. (0) | 2022.03.23 |
| c++ list insert 함수 사용법을 알아봅시다. (0) | 2022.03.21 |
| c++ list erase 함수 사용법을 간단하게 알아봅시다. (1) | 2022.03.15 |

최근댓글