이번 시간에는 Self Join에 대해서 배워보도록 하겠습니다. 이것은, 자신과 자신을 Join하는 것을 의미하는데요. 예를 들어, 이런 경우를 생각해 볼 수 있어요. 도시 이름과 인구, 도시 ID가 저장된 테이블이 있다고 가정해 봅시다. 이 때, 해당 도시의 인구 랭킹을 구하고 싶습니다. 단, 동순위는 같은 번호로 처리합니다. 이 쿼리를 어떻게 처리하면 좋을까요?
물론 MYSQL도 지금은 rank 함수가 지원됩니다. 아마 8.0부터인가부터 말입니다. 실제로, 이것을 써 봤는데 무난하게 되었습니다. 하핫. 그런데 이 함수를 쓰는 게 불가능하다. 그러면 어떻게 하면 좋을까요? 몇 가지 방법이 있는데요. 그냥 성능 생각하지 않고 짤 수 있는 방법 중 하나는 self join을 하는 것입니다.
먼저, city 테이블에 있는 내용들을 모두 뽑아보겠습니다.

그러면, ID, Name, CountryCode, District, Population. 이렇게 5개의 정보가 뜬다는 것을 알 수 있어요. 우리는 이 테이블과, 또 다른 테이블인 이것을 Join 할 거에요.
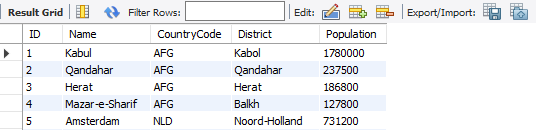
아. 왠지 같은 테이블을 Join 할 거 같은 냄새가 솔솔 납니다. 이 둘을 잘 조인해 봅시다.

이 쿼리를 작성하면 어떤 의미인가요? city x city. 즉 city와 city를 cross join 하겠다는 뜻입니다. 즉, 카티션 곱을 생성하겠다는 의미입니다. 이 테이블에 있는 row 수가 4079개이니까, 결과 값의 수는 4079^2개, 대략 1663만개 정도의 row가 리턴이 됩니다.
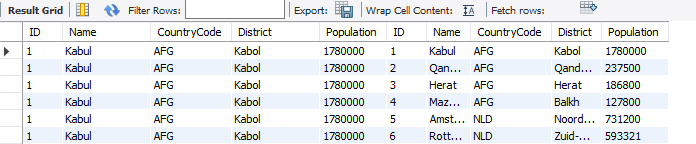
A는 city에 속하는 레코드이고, B가 city에 속하는 레코드일 때, <A, B> 쌍이 모두 리턴된다는 것입니다. 그런데, 우리는, 무엇을 구하려고 했나요? 해당 도시의 Population 순위를 구한다고 했습니다. 순위는 어떻게 계산이 되나요?

그러면 카티션 곱의 쌍 <A, B> 중에서 A.population < B.population의 쌍만 필요하다는 이야기가 됩니다. 이것을 그대로 where 절에 필터링을 걸어주시면 됩니다.

그러면 정확하게, A.population < B.population인 <A, B>쌍만 뽑혔음을 알 수 있어요. 이것을 grouping 한 다음에 잘 정리하면 좋을 듯 싶습니다. 무엇을 기준으로 그룹화 하면 좋을까요? A.ID를 기준으로 그룹화를 한 다음에, count(A.ID) + 1의 값을 출력하면 될 거에요.

그러면 이렇게 쿼리를 작성하실 수 있습니다. 그리고 이것의 결과값을 봅시다.
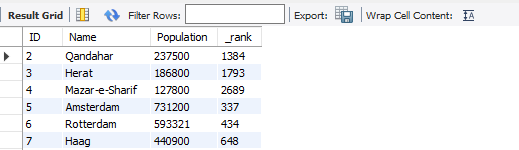
결과값이 잘 나온 것처럼 보입니다. Population을 내림차순으로 정렬해 봅시다.

_rank가 1인 것은 어디로 사라졌을까요? 1780만이 있었던 도시의 정보가 뜬금없이 사라졌습니다. 이것은 왜 그럴까요? 간단합니다.

A.pop < B.pop인 경우에만 Matched가 되었습니다. 심지어, inner Join이였습니다. 즉, A.pop < B.pop을 만족시키지 못한다면, 결과값에 A와 B가 둘 다 보존되지 않아요.
그러면 어떻게 해야 할까요?
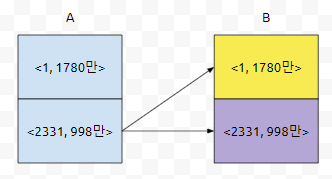
where 절의 조건을 바꾸면 됩니다. 노란색 부분은 기존에 있었던 부분입니다. 보라색 부분만 넣으면 되는데요. 섣불리 A.Population <= B.Population을 Join 조건으로 삼으면 안 됩니다. 왜냐하면, 이런 경우도 있기 때문입니다.

그러면, <2332, 998만>은 조인이 될 때, <2332, 998만> 뿐만이 아니라, <2331, 998만> 과도 매칭이 될 거에요. 그러면 골치가 아파집니다. 차라리, A.Population < B.population이거나 A.ID = B.ID인 것만 필터링 하게 하면 어떨까요?
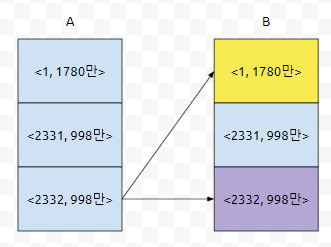
그러면, A.Pop < B.pop은 노란색으로 칠해지고, A.ID = B.ID라면 보라색으로 칠해질 거에요. 그러면 이 때 A.ID를 기준으로 group by를 돌렸을 때, rank를 구하려면 어떻게 하면 될까요? count(A.ID)만 구하면 됩니다. 쿼리는 아래와 같습니다.
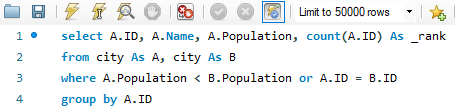
이렇게 쿼리를 작성하면, _rank가 1인 정보도 제대로 들어옵니다.
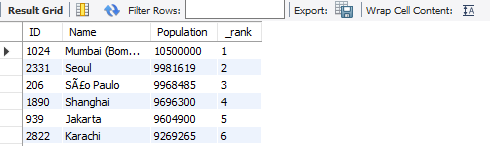
다음에, 동 순위도 제대로 처리가 될까요?

됩니다. 성능 생각 안 하고, rank 함수가 없을 때, 자기 자신과 자기 자신을 조인하는, self join을 이용해서 처리할 수도 있다는 점은, 그냥 예제로만 알고 넘어가셔도 좋을 듯 싶습니다. 왜냐하면, 사실, row 수가 매우 많아지는 경우, 이런 식으로 처리할 경우에 굉장히 많이 느리기 때문이에요.
어떻게 이것을 훨씬 빠르게 할 수 있는지는 다음에 이야기 해 보도록 하겠습니다.
'코딩 > Sql' 카테고리의 다른 글
| mysql ascii char 함수 : 문자와 아스키 코드 값을 상호 변환을 해 봅시다. (6) | 2019.12.29 |
|---|---|
| sql as 절 : 필드명이나 테이블의 이름을 다시 지을 때 쓴다. (2) | 2019.12.26 |
| sql using 절 : 조인을 할 때 같아야 할 속성을 명시한다. (6) | 2019.12.12 |
| sql 자연조인 : 속성 값이 같은 것들끼리만 결합한다. (2) | 2019.12.02 |
| mysql datediff 함수 : 두 날짜의 차이를 일 단위로 리턴해 준다. (8) | 2019.12.01 |


최근댓글