mysql은 8버전 부터였나요? rank 함수를 쓸 수 있습니다. 이런 꿀 같은 함수를 외워서 쓰지를 못하다니. 반성해야 겠습니다. 이것은 뒤에 over절이 같이 따라나옵니다. 이 안에 들어갈 내용을 생각해 봅시다. 랭킹을 매길 때나, 정렬을 할 때에는 무엇이 중요한가요? 바로, 기준입니다. 예를 들어서, 인구수 기준으로 내림차순으로 랭킹을 매기고 싶다던지, 점수 내림차순으로 매기고 싶다던지, 그런 것들입니다.
이들은, order by 구문으로 처리할 수 있습니다.
world 데이터 베이스에는, city 테이블이 있습니다. 이것을 가지고 놀아보겠습니다.

예를 들어봅시다. 위 쿼리는, city 테이블에서 Population 내림차순으로 랭크를 매기라는 의미입니다.

그러면 정확하게 랭킹값이 Population이 낮을수록 높다는 것을 알 수 있습니다. 여기서 중요하게 짚어낼 수 있는 특징 하나가 더 있는데요. 랭크를 매기는 기준이 Population이였습니다. 그러면, Population이 같다면, 우선 순위 자체가 같다는 건데요. 이 경우에 어떻게 처리가 될까요?
이 결과 역시 위에 나와 있습니다. Thimphu 지역과, Chuuk 지역의 도시의 인구는 22000으로 같습니다. 이 둘의 랭킹이 4021으로 같습니다. 인구가 22000명보다 작은 도시 중 제일 많은 인구수를 가진 도시는, Bander seri Begawan임을 알 수 있는데요. 이 도시의 랭킹은 4022가 아닌 4023임을 알 수 있어요.

dense_rank는 이와는 다르다는 것을 알 수 있는데요. 같은 Population에 대해서 랭킹이 같은 건 동일합니다.
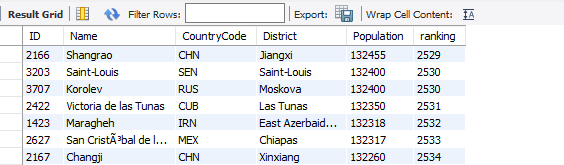
그런데 결과를 보면, 인구가 132350명이 있는 Victoria de las Tunas라는 도시의 인구 랭킹이 2531이라는 것을 알 수 있는데요. 이는, 인구가 132400명 미만인 도시 중 가장 인구가 많은 도시입니다. 공동 2530위 다음에, 2532위가 오는 게 아니라, 2531위가 왔다는 것을 알 수 있어요.
그러면 이런 문제 상황을 생각해 봅시다. 도시 인구수가 2위인 도시를 구해주세요. 사실 이렇게 쿼리를 작성하실 수도 있을 겁니다.

무엇이 문제일까요? 생각해 보면, 답은 간단합니다. 1 ~ 3번째 줄까지 해석을 하면, city 테이블에서 Population으로 내림차순으로 정렬한 결과가 나타나게 됩니다. 여기서 인구 수가 10만인 A, 9만인 B, 9만인 C 이렇게 나왔다고 해 봅시다. 위의 쿼리에 따르면, 인구 수가 9만인 도시 B만 출력이 될 겁니다. 사실, B와 C를 다 출력하는 게 정답임에도 불구하고요.
이는 랭크가 같은 레코드가 여러개 있는 경우에 발생합니다. rank 함수를 이용하면, 이 쿼리를 매우 쉽게 작성할 수 있습니다.

그런데, 호락호락하지는 않습니다. 이렇게 작성하면 어떨까요? city 행에 ranking이라는 필드가 없다면, 문제가 생길 거에요. where 절은 선택된 테이블에서의 필터링 조건이기 때문입니다. 그리고 select 절에서, 레코드들 중에서 어떤 속성을 선택할 건지 기술을 하니까요.
대신에, 서브 쿼리를 쓰면 이 문제를 해결할 수 있는데요. 제가 작성한 이 쿼리 전체를 SubQuery로 넣겠습니다.

rank를 매긴 결과가 있는 테이블을 t로 재정의 하면, t.ranking이라는 것에 접근할 수 있어요. 이 값이 2인 것을 찾기만 하면 됩니다.

답은 Seoul 이군요.
이제, 그룹별로 랭킹을 매기고 싶은 경우를 생각해 봅시다. 예를 들자면, 나라별로 도시 랭킹을 구한다던지. 그러한 경우가 있을 수 있어요. 이 때에는 어떻게 하면 좋을까요?

partition by를 넣습니다. 나라는 CountryCode로 대응이 될 수 있는데요. 이것을 그룹 조건으로 삼습니다. 즉, over 절 안에, 나라 코드를 기준으로 partition 하겠다는 절을 넣습니다. 2번째 줄이 그 의미입니다. 3번째 줄의 의미는 무엇인가요? population이 큰 게, 우선 순위가 높다는 것을 의미합니다.

수행 결과는 위와 같습니다. 여기서 질문 하나 드리겠습니다.

이렇게 쿼리를 작성해도 될까요? group by도 그룹핑을 하는 거 같은데.. 하나의 그룹으로 묶는 거랑, 그룹별로 따로 랭킹을 매기는 거랑은 뉘앙스가 다릅니다. 예를 들어서, 각 나라별로 Table에 있는 도시의 갯수를 구하고 싶다. 그러면, 나라별로 묶어서 count를 해 주면 됩니다.
그런데 각 나라별로 도시의 Rank를 구하고 싶다. 예를 들어 Korea라는 나라에 도시 레코드가 Seoul, Daejeon, Daegu, Busan 이렇게 있다고 하면, 이 4개의 레코드가 Korea 라는 그룹 내에서 랭킹이 매겨져야 하는 것이지, 하나의 그룹으로 묶어져야 하는 것이 아닙니다.

우리가 원하는 결과는 AFG라는 CountryCode를 가진 도시가 4개 나오는 거였습니다. 나라별로, 도시의 rank를 묶는 게 제 의도였습니다. 그런데, Group by 절 덕분에 하나만 나와버렸습니다. 조금만 바꿔서 생각해 보면, 논리적으로 맞지 않는 쿼리임을 알 수 있어요. 헷갈릴 여지가 다분하니, 정리해 두는 게 좋을 듯 싶습니다.
Rank 함수에 대해서 간단히 알아보았습니다. 사실, 랭킹을 매기는 쿼리는 모르면 고역이요. 알면 꿀을 먹을 수 있습니다. 그 꿀을 못 먹었던 저는 무지했습니다. 앞으로 덜 무지한 사람이 되어야 겠습니다.
'코딩 > Sql' 카테고리의 다른 글
| sql group by 응용 : 시험을 최소 1번 이상 통과한 사람을 고르라. (4) | 2020.04.18 |
|---|---|
| mysql dayofweek dayname 함수 : 요일을 돌려준다. (2) | 2020.03.20 |
| mysql distinct 절 : 중복된 결과를 제거한다. (10) | 2020.02.17 |
| hash vs balanced tree : 언제 어떻게 써야 할까요? (6) | 2020.01.19 |
| mysql ascii char 함수 : 문자와 아스키 코드 값을 상호 변환을 해 봅시다. (6) | 2019.12.29 |


최근댓글